《机器学习》专题
-
 快手 机器学习算法 二面
快手 机器学习算法 二面时长:1h 1.自我介绍 2.选了个实习深挖,这部分问了蛮多的,从流程到实现,每部分的输入输出等等 3.根据我的研究方向,问了一些经典的算法和最新的一些前沿成果(这部分拉了坨大的,面试官说我说的那些东西在他上学那会就有了) 4.注意力机制的计算公式?为什么除以根号dk? 5.了解推荐模型嘛?知道哪些模型? 6.手撕:和为k的连续子数组(面试官口述的问题,一开始理解成输出数量,结果是要输出所有的数组
-
 美团 机器学习 一面 二面
美团 机器学习 一面 二面8.23 一面: 自我介绍 项目1,2 算法题:最长回文子串 八股: 逻辑回归 bagging boosting 反问 8.30 二面 自我介绍 项目盘 算法题:重复数字 八股: 逻辑回归为什么用交叉熵损失函数 word2vec为什么只用一个隐藏层 python的迭代器和生成器的区别 反问 唉,二面答的不好,算法题也有点紧张了,没当场撕出来 发面攒人品了
-
 OPPO机器学习提前批一面
OPPO机器学习提前批一面1.自我介绍+项目 2.卷积的特征图计算((w+2p-k)/s+1) 3.VGG16的结构和思想?(5×5卷积核等价于2个3×3,7×7等价于3个3×3) 4.UNet结构和思想?下采样+上采样 5.Deformable Conv的做法(卷积+offset预测) 6.SVM,K means,GBDT等传统机器学习算法的一些问题:hard margin如何做的+K means流程 7.蒸馏是什么,温
-
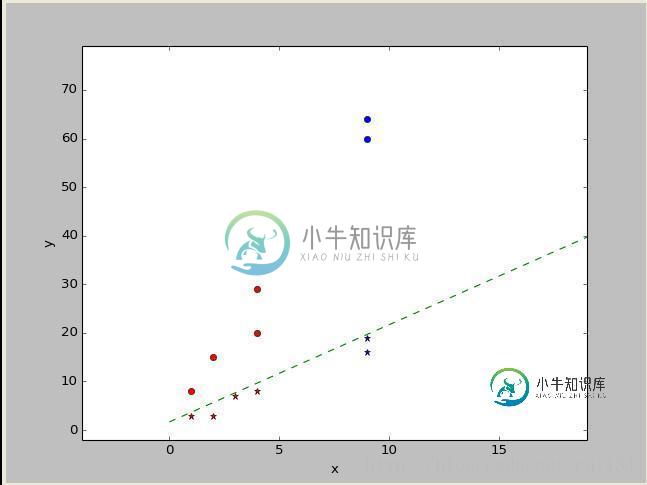 python机器学习之神经网络(一)
python机器学习之神经网络(一)本文向大家介绍python机器学习之神经网络(一),包括了python机器学习之神经网络(一)的使用技巧和注意事项,需要的朋友参考一下 python有专门的神经网络库,但为了加深印象,我自己在numpy库的基础上,自己编写了一个简单的神经网络程序,是基于Rosenblatt感知器的,这个感知器建立在一个线性神经元之上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干
-
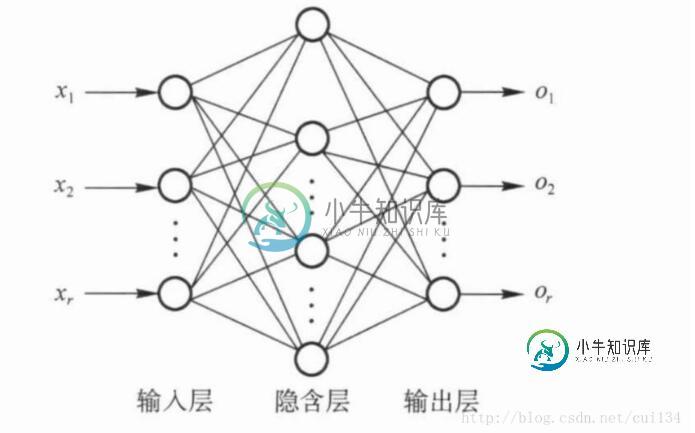 python机器学习之神经网络(二)
python机器学习之神经网络(二)本文向大家介绍python机器学习之神经网络(二),包括了python机器学习之神经网络(二)的使用技巧和注意事项,需要的朋友参考一下 由于Rosenblatt感知器的局限性,对于非线性分类的效果不理想。为了对线性分类无法区分的数据进行分类,需要构建多层感知器结构对数据进行分类,多层感知器结构如下: 该网络由输入层,隐藏层,和输出层构成,能表示种类繁多的非线性曲面,每一个隐藏层都有一个激活函数,将
-
机器学习:使用 NVIDIA JetsonTX2 - 安装TensorFlow
安装 TensorFlow 安装依赖套件 $ sudo apt-get install default-jdk libcupti-dev $ export JAVA_HOME='/usr/lib/jvm/java-8-openjdk-arm64/' 取得 TensorFlow 编译脚本 $ git clone git://github.com/jetsonhacks/installTenso
-
机器学习:使用 NVIDIA JetsonTX2 - 安装OpenCV
安装 OpenCV 既然 TX2 上面有相机模组,那我们就来装个 OpenCV 来做相机的影像处理吧! Python3 会是我们的主要语言。 安装依赖套件 $ sudo apt-get install build-essential cmake git pkg-config libjpeg8-dev libtiff5-dev libjasper-dev libpng12-dev libavcod
-
Scikits机器学习中的价值缺失
问题内容: scikit-learn中是否可能缺少值?应该如何代表他们?我找不到关于此的任何文档。 问题答案: scikit-learn不支持缺少值。 以前在邮件列表上已经对此进行了讨论,但是没有尝试实际编写代码来处理它们。 无论您做什么, 都不要 使用NaN编码缺失值,因为许多算法都拒绝处理包含NaN的样本。 上面的答案已经过时;最新版本的scikit-learn具有一个类,该类可以进行简单的针
-
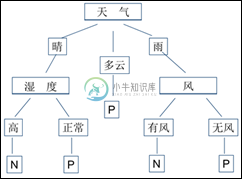 Python机器学习之决策树算法
Python机器学习之决策树算法本文向大家介绍Python机器学习之决策树算法,包括了Python机器学习之决策树算法的使用技巧和注意事项,需要的朋友参考一下 一、决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构。 决策树的根结点是所有样本中信息量最大的属性。树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性。决策树的叶结点是样本的类别值。决策树是一种知识表示形式,它是对所有样本数据的高度概括
-
Azure机器学习指定输入大小
我刚开始使用Azure ML,我正试图找出如何为模型指定输入大小。具体地说,我有一个很大的数据训练集,但我想一次只输入250条记录到PCA算法中。似乎我所能做的就是将整个数据集连接到PCA模块中。 我知道如何为X验证划分数据,但我希望一个分区(比如10000条记录)每次只向模型提供250条记录。
-
 机器学习面试题与解析1
机器学习面试题与解析1面试高频题1: 题目:了解决策树吗 答案解析: 决策树是一种机器学习的方法。决策树的生成算法有ID3, C4.5和C5.0等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。 决策树的构造过程: 决策树的构造过程一般分为3个部分,分别是特征选择、决策树生产和决策树裁剪。 (1)特征选择: 特征选择表示从众多的特征中选择一个
-
 机器学习面试题与解析2
机器学习面试题与解析2面试高频题11: 题目:L1、L2的原理?两者区别? 答案解析: 原理: L1正则是基于L1范数和项,即参数的绝对值和参数的积项;L2正则是基于L2范数,即在目标函数后面加上参数的平方和与参数的积项。 区别: 1.鲁棒性:L1对异常点不敏感,L2对异常点有放大效果。 2.稳定性:对于新数据的调整,L1变动很大,L2整体变动不大。 答案解析 数据分析只需要简单知道原理和区别就行,公式推导不需要,面试
-
 oppo机器学习算法实习面经
oppo机器学习算法实习面经前言: 岗位:机器学习算法实习 笔试情况:无笔试 一面 1.自我介绍(非科班硕,一份水实习); 2.介绍项目,并由此引出一系列八股文: 介绍gbdt算法的原理与实现 说说xgboost对于gbdt所做的主要优化 3.介绍实习工作 简单介绍resnet及其主要改进(shortcut连接,BN层),说说这些改进为什么work 介绍transformer及self-attention机制实现方式 了解哪
-
 星环_机器学习_提前批笔试
星环_机器学习_提前批笔试牛客上星环的帖子很少,我来分享下。 2道选择题10分,3道问答题30分,3道简答题60分 3道简答题是3选2,题目量不大,时间充裕。 题目考的内容就是统计学习,概率论,深度学习理论 跟牛客星环题库里的那套算法真题一样。 感觉挺复杂的,有些基础知识还是得系统梳理下😅 #星环科技##提前批#
-
 大疆8.7机器学习笔试A卷
大疆8.7机器学习笔试A卷不知道题目是不是随机抽的 感觉考了好多模型压缩问题,唉,好多选择题不会 简答三道,第一题是介绍至少三种模型压缩方法,第二题是考非对称算法和int8的卷积,第三题是考各个优化器 第二题完全没听过,直接跳过了,孩子会不会直接挂了唉 一个编程题,超级简单,完全二叉树的S遍历 统计一下大家简答题和编程题 #大疆##算法##投票##大疆2023校招笔试心得体会#