《机器学习》专题
-
机器学习编程语言之争,Python夺魁
来源:http://www.infoq.com/cn/news/2015/09/Python 随着科技的发展,拥有高容量、高速度和多样性的大数据已经成为当今时代的主题词。数据科学领域中所采用的机器学习编程语言大相径庭。究竟哪种语言最适合机器学习成为争论不休的话题。近日,密西根州立大学的博士生Sebastian Raschka再次发起了机器学习编程语言之争,分析了自己选择Python的原因。 目前,
-
 斯坦福 CS229 机器学习讲义中文版
斯坦福 CS229 机器学习讲义中文版今天人工智能领域的研究者,几乎无人不谈深度学习。很多人甚至高喊出了「深度学习 = 人工智能」的口号。毋庸讳言,深度学习绝对不是人工智能领域的唯一解决方案,二者之间也无法画上等号。但说深度学习是当今乃至未来很长一段时间内引领人工智能发展的核心技术,则一点儿也不为过。
-
 百度机器学习工程师一面凉经
百度机器学习工程师一面凉经岗位:机器学习/数据挖掘/自然语言处理工程师 面试体验:第一个面的公司,很紧张,也是被拷打的最狠的一次 一面 8/23 70分钟 1. 自我介绍 2. 实习拷打 推荐算法中的相关模型和前沿理论 是否有读过最近的期刊上的文章,做一些介绍 3. 科研拷打 如何做的模型 其中的系数如何确定 4. NLP拷打 Attention介绍 QKV是什么,举例说一下 Tranformer的encoder和deco
-
 快手机器学习算法工程师一面
快手机器学习算法工程师一面快手机器学习算法工程师一面50min 人生中第一次找工作面试😭 (面试官姐姐人超好😭,一直心平气和的和聊天一样,我说错了也没说我而是跟我解答,甚至帮我找理由,全程都很耐心) 1.自我介绍 2.介绍用过哪些机器学习方法 3.SVM的原理跟优势 4.集成学习(扯了下随机森林跟集成学习原理),XGBOOST(没用过) 5.knn和kmeans做分类的原理 6.你们做的遥感图像怎么提取特征 7.问了下
-
 百度2024秋招机器学习一面面经
百度2024秋招机器学习一面面经百度2024秋招机器学习一面面经 岗位:机器学习/数据挖掘/NLP-T联合 部门:百度地图 地点:北京 一面 自我介绍 对项目和实习的大概询问,没有去深挖,只是对一些问题进行询问 询问对大模型的了解,讲了 RLHF 的原理 RLHF是一种新的训练范式,通过使用强化学习方式根据人类反馈来优化语言模型。一共包括三个步骤: 预训练一个语言模型(LM) 收集数据并训练奖励模型 (Reward Model,
-
 百度地图机器学习算法岗一面
百度地图机器学习算法岗一面11月27日 首先自我介绍,大致说了一下自己硕士阶段的项目工作。项目用的是高德地图数据😂,面试官好像并不在意这个。 从项目中提的问题: 1数据处理工作包含的内容 2交通异常检测任务细节 3超图的概念,为什么要用超图 4论文中自己算法的指标有多高(自己记不清了,翻了一下手机,被笑话,说这样会让人怀疑不是自己做的) 5Lstm原理,优缺点(我不太清楚优缺点,但是回答了比RNN的优势) 开放性问题:
-
 23秋招 360机器学习工程师 面经
23秋招 360机器学习工程师 面经9.7一面 (50min) 自我介绍 项目比赛提问,问具体的细节 GRU与LSTM的区别 GBDT的原理 XGBoost和LightGBM与GBDT的区别 BN在训练和测试阶段的区别?BN在训练时是如何更新参数的? 手撕算法题: 在一个m*n的矩阵里,一个机器人初始在x,y点,并且每次只能向相邻的上下左右四个方向移动一步,那么在最多移动k次情况下,一共有多少条路径可以逃出矩阵? 输入5个参数:m,
-
 京东 算法工程师--机器学习 面经
京东 算法工程师--机器学习 面经中秋节前一天 一面(初试) 30分钟 没开摄像头,是在京东的会议平台上面的 深挖简历,主要问了项目与竞赛 八股文集中于大数据方面:spark与map reduce之间的差别、spark与flink区别、flink水位线等,有些问题不记得了,但基本都答上来了 没有手撕 反问:业务、匹配程度 ------------------------ 已挂 #京东##算法工程师#
-
 小米--机器学习算法工程师(一面)
小米--机器学习算法工程师(一面)8.18 测评 9.6 一面 项目1介绍 逻辑回归简介 极大似然法简介 反问 KPI面...面完了面试官说他们是做加密的,不懂为什么让我面... #小米面试#
-
 23秋招 360 机器学习算法岗 面经
23秋招 360 机器学习算法岗 面经写在前面:360我很早就面完了,一直没结果估计泡没了,自己也签了其他公司了,最近来更新一下面经。 一面:2022.9月初 (40分钟左右) 1、自我介绍 2、讲实习项目,讲到LightGBM,有没有试过XGB、GBDT,讲讲模型异同,在这个项目里怎么处理缺失值的。机器翻译是怎么做的,lstm和cnn的区别有了解嘛, 3、讲一个比赛项目,说下你怎么做特征的。语义特征怎么做的,如何判断两个近义词,wo
-
 卓驭 机器学习平台工程师 一面
卓驭 机器学习平台工程师 一面8月15日 一面(40分钟) 没有笔试,测评做完直达面试,两个面试官,没有手撕。 自我介绍 实习经历 大模型多卡流水并行的实现 资源利用率怎么评估 还有没有其他相关的优化方案 项目经历 八股 多态的概念和原理->虚函数->虚函数指针->多次继承的派生类的虚函数指针和虚函数表的情况 模板类用的多吗->vector在push_back会有什么操作 cpp多线程 你觉得做机器学习平台开发要哪些知识? 你
-
 百度 提前批机器学习 二面面经
百度 提前批机器学习 二面面经自我介绍到一半打断了,直接问八股…… 关注的点和一面一样有点奇怪,特别喜欢问我记不记得base模型的d_models和seq_len以及各种各样的参数…… 项目里一直纠结我训的1.5B模型,我跟她说我还训了3.8B和72B版本,没让我讲下去,说1.5B已经很大,可以满足我们项目需求了…… 代码题做了lc. 236的变体最近公共子节点,和lc. 15三数之和,手撕的没什么问题,但这三数之和在一面已经
-
在机器学习中处理地理空间坐标
我正在建立一个机器学习模型,其中一些列是物理地址(我可以将其转换为X / Y坐标),但我对ML算法如何处理这一点有点困惑。有没有一种特定的方法可以将地理位置转换成列,以便用于ML(分类和/或回归)中? 提前感谢!
-
生产中机器学习算法的实验设计
我已经准备好了机器学习算法。我想在一个拥有70个城市的国家将其投入生产。但在将其推广到 70 个城市之前,我想在 1 个城市进行实验,以评估它在生产中的性能。但是,我现在面临一个问题,如果出现以下情况,我应该设置什么标准:1. 时间(我可以将其投入生产多少个月)2.数据(在实时环境中我需要多少数据来评估算法性能) 任何人都可以在生产环境中指导此机器学习实验吗? 编辑:我正在将机器学习应用于美国的价
-
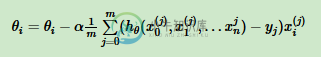 python实现机器学习之多元线性回归
python实现机器学习之多元线性回归本文向大家介绍python实现机器学习之多元线性回归,包括了python实现机器学习之多元线性回归的使用技巧和注意事项,需要的朋友参考一下 总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便。 一元线性回归实现代码 下面是多元线性回归用Python实现的代码: 特别需要注意的是要弄清:矩阵的形状 在梯度下降的时候,计算两个偏导值,这里面的矩阵形状变化需要注意。 梯度下降数学式子