《机器学习》专题
-
机器学习:贝叶斯、KNN、决策树
贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。 先验概率:根据以往经验和分析得到的概率。我们用 \small P(Y) 来代表在没有训练数据前假设\small Y拥有的初始概率。 后验概率:根据已经发生的事件来分析得到的概率。以 \small P(Y|X) 代表假设\small X 成立的情下观察到 \small Y数据的概率,因为它反映了在看到训练数据\small X后\small Y成立的置信度。
-
二、端到端的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目。下面是主要步骤: 项目概述。 获取数据。 发现并可视化数据,发现规律。 为机器学习算法准备数据。 选择模型,进行训练。 微调模型。 给出解决方案。 部署、监控、维护系统。 使用真实数据 学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的
-
 Sklearn 与 TensorFlow 机器学习实用指南
Sklearn 与 TensorFlow 机器学习实用指南2006 年,Geoffrey Hinton等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。
-
 顺丰一面机器学习岗 凉经
顺丰一面机器学习岗 凉经本来三十分钟的面试,我直接十四分钟完事,面试官不问具体项目做了啥,就从你做的项目里面挖知识点,基本问的都是纯八股,很基础的问题,但是我太菜了(我答的很不好,可能还没到问项目呢😅),面试官人很好,你说不会,他就说那咱换一个,反问之后还给我提建议来着。 总结,体验还可以,问题在自己太菜😂
-
 快手机器学习工程师凉经
快手机器学习工程师凉经1.自我介绍 2.项目深挖 3.数理统计,如何用更少的试管
-
 东软,研究员(机器学习方向)
东软,研究员(机器学习方向)9.2 东软一面(共 23 min) 主要问项目相关,因网络不佳而中断?后直接发offer,但逼签 自我介绍,项目介绍 简历闲聊 除了c++还会啥 SQL会吗 项目深挖 一句话总结项目在做什么? 实例分割模型有哪些,你用了那些? 污水项目实例分割的评价标准 c++项目为啥不用深度学习做? 网络不佳中断,未反问,说后续会有HR联系 三分钟后,HR微信问期望薪资,然后邮箱发了网申笔试,已进入流程,最后
-
 美团机器学习数据挖掘oc
美团机器学习数据挖掘oc感谢团子解救,笔试面试实在太累了,暑期就到此为止吧
-
 《机器学习高频面试题详解》1.1:感知机
《机器学习高频面试题详解》1.1:感知机前言 大家好,我是鬼仔。今天带来《机器学习高频面试题详解》专栏的第一章监督学习的第一节:感知机,接下来鬼仔将每周更新1~2篇文章,希望每篇文章能够将一个知识点讲透、讲深,也希望读者能从鬼仔的文章中有所收获。 欢迎大家订阅该专栏,可以先看看专栏介绍。如果对文章内容或者排版有任何意见,可以直接在讨论区提出来,鬼仔一定虚心接受! 一、原理 1. 感知机模型 感知机模型是一个最经典古老的分类方法,现在基本
-
 这年头机器学习没深度学习不能活了吗
这年头机器学习没深度学习不能活了吗快手一面凉经 算法 我迟到10分钟 面试45分钟 1. 和为k的连续数组 2.AUC 公式,物理意义,GAUC,auc缺点 3.L1 和L2 4. Dropout 训练预测区别 BN在哪些场景下不适用 5.Xgboost特点 6.损失函数评价函数,Huber 7.交叉熵公式 为什么分类用交叉熵不用Mae 8.生成式模型与判别式模型,NLP了解吗(我是做数据挖掘的, 认识不深,说不了解) 9.实习介
-
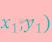 机器学习中的距离计算方法?
机器学习中的距离计算方法?本文向大家介绍机器学习中的距离计算方法?相关面试题,主要包含被问及机器学习中的距离计算方法?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 设空间中两个点为 欧式距离: cos= 切比雪夫距离:max
-
传统的机器学习算法了解吗
本文向大家介绍传统的机器学习算法了解吗相关面试题,主要包含被问及传统的机器学习算法了解吗时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 常见的机器学习算法: 1). 回归算法:回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。 常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regressi
-
机器学习的时间序列是什么?
本文向大家介绍机器学习的时间序列是什么?,包括了机器学习的时间序列是什么?的使用技巧和注意事项,需要的朋友参考一下 顾名思义,时间序列是包含特定时间段或时间戳的数据。它包含一定时间段内的观察结果。这类数据告诉我们变量是如何根据各种因素随时间变化的。时间序列分析和预测可以用来预测未来某个时间的数据。 单变量时间序列包含在一段时间内某些时间实例中针对单个变量获取的值。多元时间序列包含在相同的周期性时间
-
机器学习:使用 NVIDIA JetsonTX2 - 从零开始
从零开始 灌作业系统一定是我们的首要目标,但在这之前,我们要先有一台运行 Ubuntu x64 (14.04或更新) 的电脑,可以用虚拟机来代替。 没有虚拟机的朋友可以用VirtualBox。 Ubuntu x64 的映像档可以在这边下载。 1. 安装 VirtualBox 流程就不在这边赘述,简单来说,就是狂按下一步。 2. 安装 Ubuntu x64 有两点要注意: 因为稍后下载回来的安装包还
-
Azure机器学习(预览)到客户洞察
我正在尝试将MS Dynamics Customer Insights(CI)与我在新的Azure机器学习(designer)中构建的模型集成。目前,我看到CI和Azure机器学习工作室(classic)之间只有一个集成。 我已经在新Azure机器学习中的web服务(REST)后面部署了我的模型,但是它在CI中没有得到重视。但是,我能够使用Python脚本从API中评分/生成预测。 请推荐一种集成
-
weka中的机器学习分类与预测
我对机器学习很陌生。对不起,如果我的英语有任何错误。 我使用weka J48分类来预测是真是假。我有将近999K的训练套件,我用来训练模型。我使用了3倍的交叉验证方法来训练模型,使我的准确率达到了约84%。 现在在存储模型之后。我试着在50k数据集上测试它。结果非常糟糕,其中50%是不匹配的。我有11个属性,包括名词和数字字段。 我不知道为什么会这样。 我有两个问题。 我怎样训练才能在测试集中表现