《opencv》专题
-
JBoss OpenCV未解析编译
问题演示 我的任务是创建一个动态Web项目,该项目扫描来自服务器的文档,通过我的程序并将图片从文本中拆分。我需要OpenCV库。我的代码在eclipse中运行良好,工作良好。现在,我需要将库作为全局模块加载到jboss中,而不是在eclipse中,以便服务器始终知道需要加载哪些库。我所做的一切都是这个链接描述的: 有人知道为什么这是个问题吗?是否存在验证问题?Eclipse在将一个新类放入open
-
anaconda/lib/libcurl。所以4当我在ubuntu14编译opencv时,没有可用的版本信息
当我在Ubuntu上编译opencv时,我遇到了这个问题“/usr/bin/cmake:/usr/home/anaconda/lib/libcurl。所以。4:没有可用的版本信息(cmake需要)”。 我不知道原因,我找到了libcurl。所以4在/usr/home/anaconda/lib/,是因为我有其他版本的libcurl吗。所以4.或者我应该重新安装蟒蛇?
-
指定cmake使用qt4构建opencv
我的Ubuntu电脑同时安装了qt4和qt5,因为它与一些lib兼容。目前,我想用qt4重建opencv(用于highgui)。但cmake始终使用qt5(默认版本)。我编辑了CMakeLists。txt文件 重建opencv后,我使用ldd libopencv_highgui检查依赖项。所以 libqt5核心。所以5 = Highgui仍然链接到Qt5。有人能帮我吗?谢谢
-
在eclipse ubuntu上构建opencv项目失败
我想在ubuntu 16.04上的eclipse上构建简单的opencv程序。 我添加包含路径文件: 收件人: 并添加库路径: 收件人: 并添加: 到库(),但当我想要构建项目时,发生了此错误: 为什么?
-
尝试构建docker映像时,在pkg配置搜索路径中未找到包opencv
我在努力塑造docker的形象,但我有这个 应用程序/实用程序 应用程序/供应商/fifo/fifobuffer_v2 停车检测/p kgs/utils app/pkgs/utils 应用程序/供应商/github。com/stratoberry/go-gpsd 驻车检测/gpsdata gocv.io/x/gocvapp/gpsdata 包装配置——cflags opencv 在pkg配置搜索路
-
Pyspark UDF获取描述符的问题与openCV问题
我从Spark哲学开始,在我的例子中是Pyspark。 我有一个学校的小项目要做,看起来不难,但是我已经做了很多天了,我仍然不能成功。 我必须将图像加载到文件夹中并提取描述符以进行降维。 我创建了一个带有图像路径的Pyspark数据框,现在我想添加一个带有描述符的列。 我是这样做的。 图像路径列表: 提取描述符的函数: 功能自定义项: 新列的创建: printSchema()的结果: 根--pat
-
 如何使用OpenCV对高度压缩图像中的宏块进行“去量化”?
如何使用OpenCV对高度压缩图像中的宏块进行“去量化”?给定一个高度压缩的图像(非特定格式),存在各种大小和形状的图像块,其中所有像素具有完全相同的值。 例如: 我的目标是“智能地”平滑这些块到梯度产生一个更平滑,更有机看起来的图像。我看过绘画中的技巧(如热扩散),可能是适用的,但我不完全确定如何适应我的目的。我目前正在编写自己的函数来执行这个操作(详情如下)。在OpenCV(或其他地方)中是否已经有一个C++函数可以执行这个过程?如果没有,是否有一种
-
Python OpenCV未显示对象检测tensorflow的结果
我从网络摄像头中添加了目标检测代码,当我运行此代码时,它会显示检测2-5秒,然后在imshow窗口中显示未响应。 注: > 我用的是cv2。等待键(1),cv2。waitKey(0)也是,结果相同。 我正在使用tensorflow gpu,它检测到我的gpu:1050ti。 但是OpenCV使用CPU来显示图像。 更新部分: [已解决]我刚刚创建了新的conda环境并安装了tensorflow版本
-
如何为Python OpenCV CV2更新imshow()窗口
我的当前程序将向用户输出图像,并根据用户输入,根据需要重新调整图像。 长话短说,我试图在图像文件中找到圆形对象。我将使用Hough圆变换。然而,因为我在图像中的许多圆不是“完美圆”,所以我正在做一个“猜测”圆半径的算法。但是,我希望允许用户根据需要重新调整半径。 有没有办法要求用户输入,然后根据用户输入,重新调整imshow()中的窗口?现在,imshow()拒绝显示实际的窗口,直到我使用cv2.
-
opencv-Videowriter控制比特率
我有一个使用opencv视频编写器的python脚本。 来源https://gist.github.com/stanchiang/b4e4890160a054a9c1d65f9152172600 如果我接受一个文件,无论我是否简单地将视频帧传递给作者(有效地复制文件),或者如果我试图编辑帧,文件总是更大。我希望它不比原来的大(因为如果你读了我的剧本,我会模糊很多东西)。 在检查他们的元数据后,使用
-
使用OpenCV imwrite方法处理OpenMV摄像头的图像时出现问题
我正在尝试使用OpenCV的缝合算法缝合从OpenMV H7相机拍摄的一些图像。我遇到了无法写入或读取这些图像的问题,这让我觉得存在一些兼容性问题。 更确切地说,我在使用方法(cv2.imwrite)本身时得到了这个错误: 我一直在想,也许有一种方法可以将图像转换为NumPy数组以使其兼容,但我不太确定。 有什么建议吗?
-
 带OpenCV的增强现实SDK[封闭]
带OpenCV的增强现实SDK[封闭]我正在OpenCV上开发一个增强现实SDK。我有一些问题要找到关于这个主题的教程,哪些步骤要遵循,可能的算法,快速高效的实时性能编码等。 到目前为止我已经收集了下一个信息和有用的链接。 下载最新版本。 null 此外,应该有一些算法,以找到位置和方向的相机在每一帧。这是通过检测场景中检测到的标记与离线处理的标记的二维图像之间的单应变换来实现的。这里对这种方法的解释(第18页)。姿态估计的主要步骤是
-
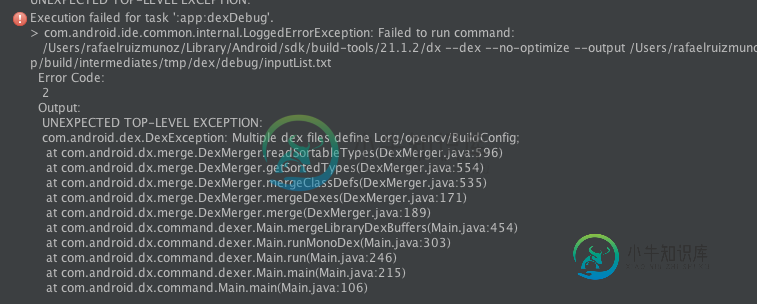 使用OpenCV库在Android Studio上创建多个dex文件
使用OpenCV库在Android Studio上创建多个dex文件所以,我的方案是:我的应用程序A项目使用Java OpenCV库,模块B也是一个使用Java OpenCV库的库模块。 我的模块设置是这样的:在应用程序A我编译模块B和B模块编译JavaOpenCV库,但我得到: 错误:任务': app: dexDebug'的执行失败。 /Users/rafaelruizmunoz/Library/Android/sdk/build-tools/21.1.2/dx
-
OpenCv与Android studio 2.2+一起使用带有cmake的新gradle-未定义引用
和我的Gradle构建文件
-
 如何在C++中集成Tesseract-OCR与OpenCV
如何在C++中集成Tesseract-OCR与OpenCV错误信息 我对tesseract、matlab和OpenCV都很陌生。我试图集成tesseract-ocr与我的C++程序来检测我定位的车牌。但是C++给我带来了错误。我需要帮助加载我的垫子图像到tesseract以识别其中的字符。 这是车牌图像,它是MAT变量