
如何在C++中集成Tesseract-OCR与OpenCV

错误信息

我对tesseract、matlab和OpenCV都很陌生。我试图集成tesseract-ocr与我的C++程序来检测我定位的车牌。但是C++给我带来了错误。我需要帮助加载我的垫子图像到tesseract以识别其中的字符。
这是车牌图像,它是MAT变量
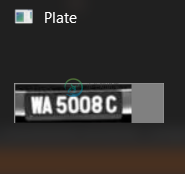
imshow("Plate", plate);
imshow("Blob", Blob);
int threshold = otsn(plate);
Mat plateequal = EHistogram(plate);
Mat converttob = converttobinary(plate,threshold);
imshow("Plate This", plateequal);
tesseract::TessBaseAPI tess;
cv::Mat sub = plate;
tess.SetImage((uchar*)sub.data, sub.size().width, sub.size().height, sub.channels(), sub.step1());
tess.Recognize(0);
const char* out = tess.GetUTF8Text();
共有1个答案

未解析的外部符号意味着编译器/链接器可以找到函数的声明,但找不到它的定义。好像你忘了把cpp文件添加到你的项目中。
-
这里有一个同样的问题。但解决方案不存在。我使用windows8,Visual Studio 2013。我的机器是64位的。我尝试将tesseract ocr集成到vs2013。我从这里安装leptonica,从这里安装tesseract。 我做了以下步骤: > 项目解决方案- 链接器- C: \Tesseract OCR\lib 链接器- 重新启动vs2013 我在main函数tesseract:
-
Tesseract OCR 该软件包包含一个OCR引擎 - libtesseract和一个命令行程序 - tesseract。 Tesseract 4增加了一个基于OCR引擎的新神经网络(LSTM),该引擎专注于线路识别,但仍然支持Tesseract 3的传统Tesseract OCR引擎,该引擎通过识别字符模式来工作。通过使用Legacy OCR Engine模式(--oem 0)启用与Te
-
我已经在Alfresco 5.0中集成了Tesseract ocr。d、 我的要求是将PDF文件数据转换为文本格式。 对于小文件来说,它工作得很好。 但是如果我上传更大的文件,比如超过50 MB, 在这种情况下,它给下面的异常,和整个pdf文件不被转换为文本文件。只有一些起始页被转换为文本格式。 请参考以下日志 有没有人遇到过同样的问题,请帮帮我。 提前谢谢。
-
Tesseract OCR iOS 是个 iOS5+ 框架,支持 armv7s 和 arm64 编译。 Tesseract 可能是最精确的开源 OCR 引擎,结合 Leptonica 图像处理库可以查看大量的图像格式,支持超过 60 种语言的文本转换。
-
我为iOS写了一个数字OCR。我有一个测试图像png与两位数5和4。我找到轮廓了。我如何在Tesseract转乘等高线? 初始化tesseract: 用于检测轮廓的函数: GitHub项目链接:https://github.com/maxpatsy/iorc
-
我正在使用一个控制台应用程序和非常基本的Tesseract来执行数字识别。我从谷歌复制了一个图像,试图找到数字只。