
Tesseract OCR 该软件包包含一个OCR引擎 - libtesseract和一个命令行程序 - tesseract。 Tesseract 4增加了一个基于OCR引擎的新神经网络(LSTM),该引擎专注于线路识别,但仍然支持Tesseract 3的传统Tesseract OCR引擎,该引擎通过识别字符模式来工作。通过使用Legacy OCR Engine模式(--oem 0)启用与Tesseract 3的兼容性。它还需要训练有素的数据文件,这些文件支持传统引擎,例如来自tessdata存储库的文件。
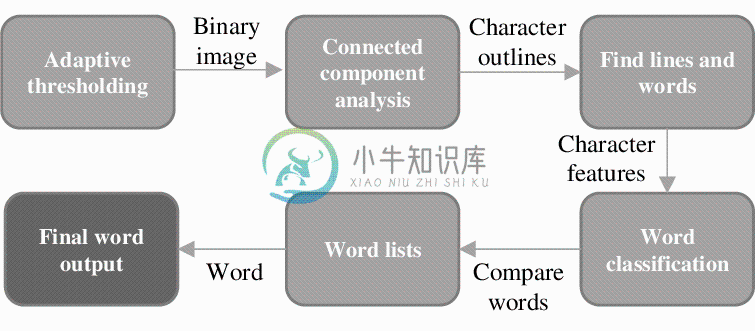
Tesseract 架构:
首席开发人员是Ray Smith。维护者是Zdenko Podobny。有关贡献者的列表,请参阅AUTHORS和GitHub的贡献者日志。
Tesseract 支持 unicode(UTF-8),可以“开箱即用” 识别100多种语言。
Tesseract支持各种输出格式:纯文本,hOCR(HTML),PDF,不可见文本的PDF,TSV。主分支还具有ALTO(XML)输出的实验支持。
您应该注意,在许多情况下,为了获得更好的OCR结果,需要提高您给Tesseract的图像质量。
该项目不包括GUI应用程序。如果您需要,请参阅3rdParty维基页面。
可以训练Tesseract识别其他语言。有关详细信息,请参阅Tesseract培训。
支持的编译器:
- GCC 4.8 and above
- Clang 3.4 and above
- MSVC 2015, 2017, 2019
-
Tesseract OCR for PHP A wrapper to work with Tesseract OCR inside PHP. Installation $ composer require thiagoalessio/tesseract_ocr ‼️ This library depends on Tesseract OCR, version 3.02 or later. Note
-
tesseract 最近搞xc,之前在x86集群是用的ocr插件的包不能再arm服务器直接安装,需要寻找arm版本的rpm包。 tesseract的arm rpm包比较好找,问题是还有其他的依赖,需要安装,否则安装会报错。经过几天的寻找,将所依赖的rpm包全部寻找到,并安装调试成功。 操作系统版本:麒麟v10sp1 下载链接 https://download.csdn.net/download/f
-
TensorFlow包含图像识别的特殊功能,这些图像存储在特定文件夹中。出于安全目的,经常要识别相同的图像,这个逻辑很容易实现。 图像识别代码实现的文件夹结构如下所示 - dataset_image 文件夹中包含需要加载的相关图像。这里将专注于图像识别,其中定义了徽标。加载“load_data.py”脚本,它记录各种图像识别模块。 图像的训练用于将可识别的图案存储在指定的文件夹中。 上面的代码行生
-
我正在使用卷积神经网络(CNN)对30种不同的水果进行图像检测。我目前拥有的数据集由“训练”和“测试”文件夹组成,每个文件夹都有30个不同类的子目录。 “train”文件夹共有671个jpg文件,“test”文件夹共有300个jpg文件。 我编写的实现图像检测的Python代码如下- 当我尝试执行此代码时,我得到以下消息- 使用TensorFlow后端。找到了属于30个类别的671张图片。找到了3
-
更新时间:2019-07-19 10:48:36 节点简介 人脸识别/图像识别/OCR节点属于智能节点,区别在于封装的云市场api功能不同。人脸识别节点主要有人数检测、人脸身份证对比、性别年龄情绪识别等功能。图像识别节点主要有烟雾火焰火灾识别、动物识别、植物识别、植物花卉识别等功能。OCR节点主要有驾驶证识别、车牌识别、身份证识别等功能。 使用场景 如果您需要进行人数检测、人脸身份证对比、性别年龄
-
问题内容: 我一直在寻找网络上图像识别数字的资源。我发现许多链接提供了有关该主题的大量资源。但不幸的是,这比提供帮助更令人困惑,我不知道从哪里开始。 我有一个带有5个数字的图像,没有打扰(没有验证码或类似的东西)。数字在白色背景上为黑色,以标准字体书写。 我的第一步是分离数字。我当前使用的算法非常简单,它只是检查一列是否完全为白色,因此是否为空格。然后,它会修剪每个字符,以使其周围没有白色边框。这
-
嗨 我们如何识别空白图像(白色图像), 我传递的图像是空的,有一些高度和宽度,我想识别它
-
问题内容: 我正在寻找一个Java框架来帮助进行一些特定于图像的数据挖掘。我们有一组历史图像,我想对其进行分类和分类。我希望找到类似weka的东西http://www.cs.waikato.ac.nz/ml/weka/或Marsyas http://marsyas.sness.net,但更特定于通过图像数据进行筛选以找到图案。有什么建议? 问题答案: 如何使用OpenCV 库进行处理?从技术上讲,
-
问题内容: 我在Visual Studio 2013中运行Python 2.7。以前在Spyder中运行该代码正常,但是在运行时: 我最终遇到以下错误: 为什么会这样,我该如何解决? 如建议的那样,我已经在我的Python 2.7中使用了Pillow安装程序。但是奇怪的是,我最终得到了这个: 都失败了! 问题答案: 我有一个同样的问题。 代替 解决了这个问题
-
是否支持使用表单识别器示例标签工具输入TIFF图像。https://docs.microsoft.com/en-us/azure/cognitive-services/form-recognizer/build-training-data-set#general-输入要求