
Umi-OCR 是一款免费、开源、可批量的离线 OCR 软件,基于 PaddleOCR,适用于 Windows10/11 平台。
特性
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,离线运行,无需网络。
- 批量:可批量导入处理图片,结果保存到本地 txt / md / jsonl 多种格式文件。也可以即时截屏识别。
- 高效:采用 PaddleOCR-json C++ 识别引擎。只要电脑性能足够,通常比在线OCR服务更快。
- 精准:默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印、设置文块后处理合并排版段落,得到规整的文本。
说明目录
- 简单上手 截图、批量识别~
- 排版优化 如何合并一个自然段内的文字?
- 忽略区域 如何排除截图水印处的文字?
- 多国语言 添加更多PP-OCR支持的语言模型库!
- 命令行调用 用命令行或第三方工具来调用Umi-OCR!
- 更多小技巧
- 问题排除 无法启动引擎 / 多屏幕截图异常 ?
下载
Umi-OCR 软件本体含 简体中文&英文 通用识别库。
配套 多国语言识别扩展包 可导入繁中,英,日,韩,俄,德,法识别库,请按需下载。
Github下载:Release v1.3.3
蓝奏云下载:https://hiroi-sora.lanzoul.com/s/umi-ocr
兼容性
- 系统支持 Win10 x64 及以上版本。
- CPU必须具有AVX指令集。
- 出现初始化引擎失败等问题时请参考 问题排除 。
前言
关于忽略指定区域的特殊功能:
类似含水印的视频截图、含有UI/按钮的游戏截图等,往往只需要提取字幕区域的文本,而避免提取到水印和UI文本。本软件可设置忽略某些区域内的文字,来实现这一目的。
当有大量的影视和游戏截图需要整理归档,或者想翻找包含某一段台词/字幕的截图;将这些图片提取出文字、然后Ctrl+F是一个很有效的方法。这是开发本软件的初衷。
关于离线OCR引擎 PaddleOCR-json :
对 PaddleOCR 2.6 cpu_avx_mkl C++ 的封装。效率高于Python版本PPOCR及部分Python编写的OCR引擎,通常比在线OCR服务更快(省去网络传输的时间)。支持更换Paddle官方模型(兼容v2和v3版本)或自己训练的模型,支持修改PPOCR各项参数。通过添加不同的语言模型,软件可识别多国语言。
简单上手
准备
下载压缩包并解压全部文件即可。
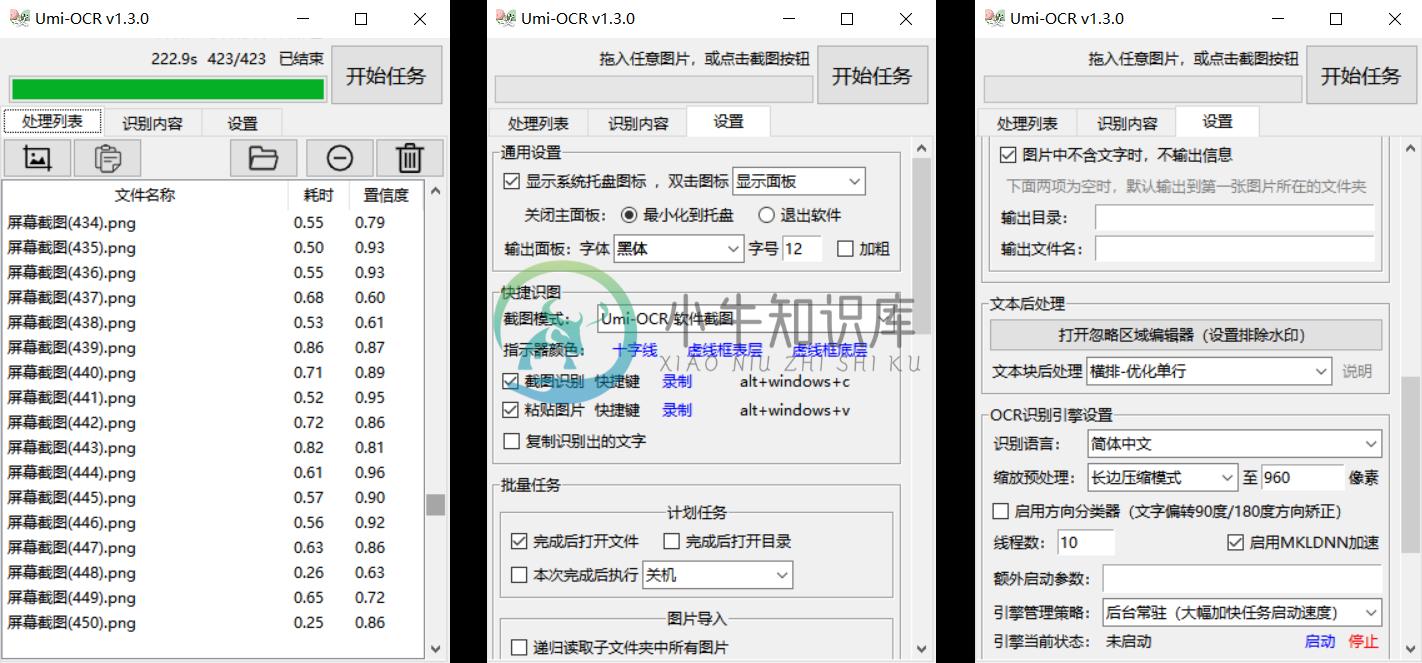
截图识别
点击截图按钮或自定义快捷键,唤起截图识别。

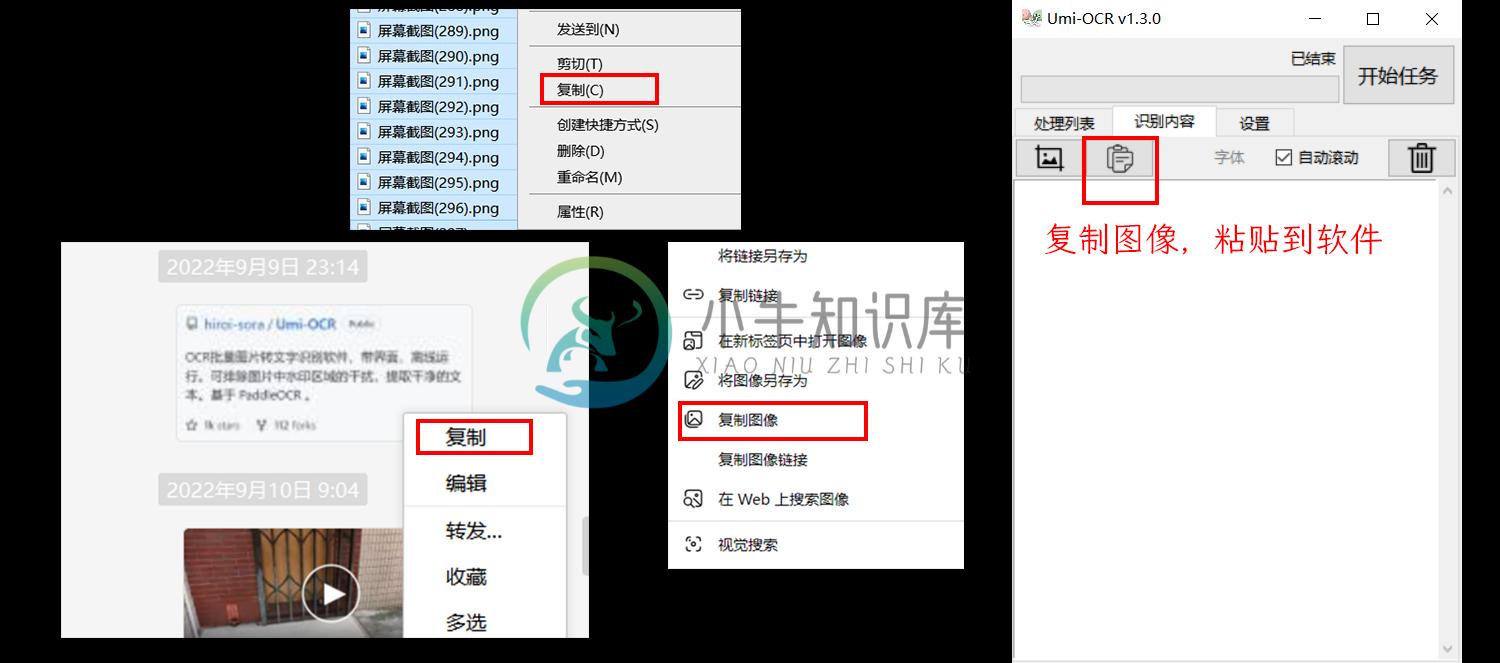
粘贴图片到软件
在任何地方(如文件管理器,网页,微信)复制图片,软件上点击粘贴按钮,自动识别。
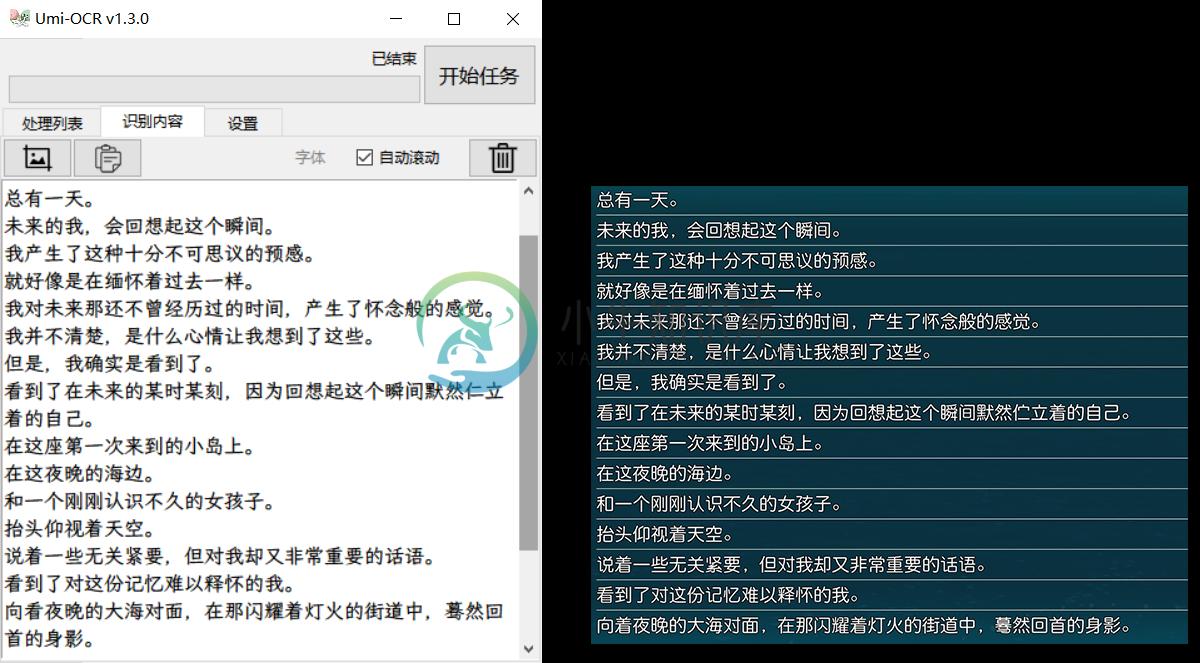
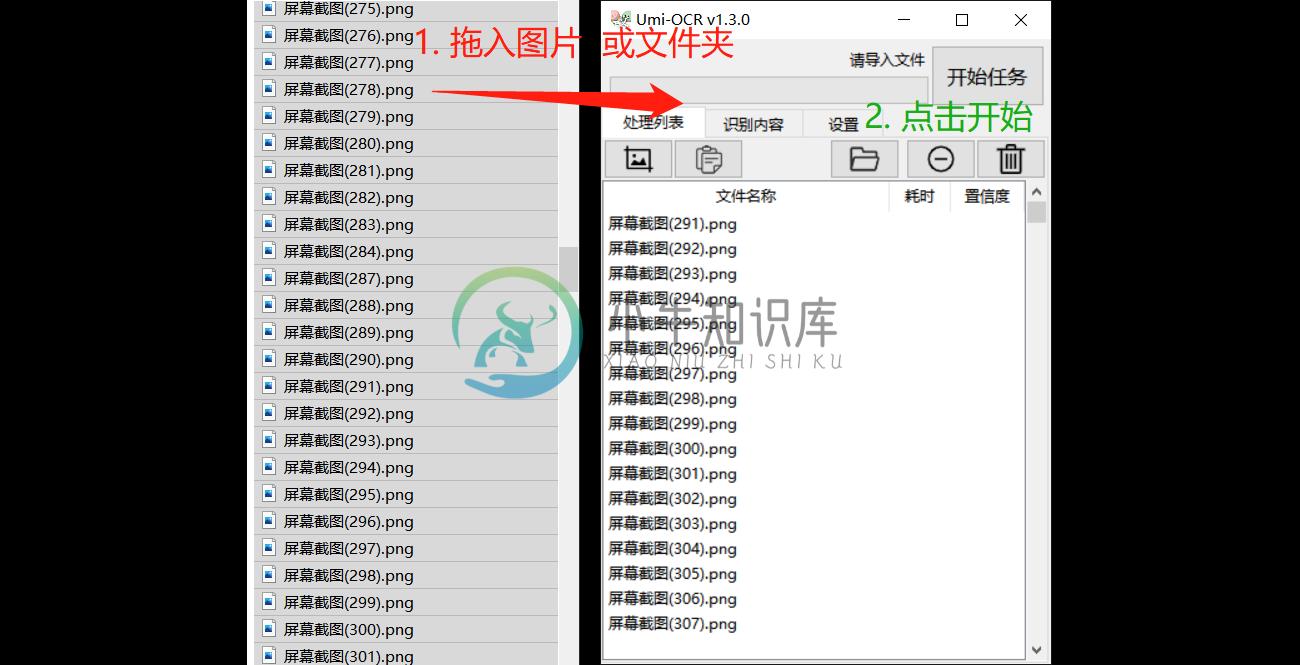
批量识别本地图片文件
将图片或文件夹拖进软件,批量转换文字。也可以点击按钮打开浏览窗口导入。
识别结果将保存到本地。可选生成纯文本txt文件、带链接Markdown文件、原始信息jsonl文件等不同格式。可配置任务完成后执行关机/待机。
文本块后处理(排版优化)
OCR识别出的文本是按“块”划分的,通常一行文字分为一块,有时还会将一行误划分为多块,这给阅读带来了不便。文本块后处理就是对文本块进行再加工的过程,合并同一行或同一段落内的文字,按正确的顺序排序。
下图表示不同排版应该选用何种处理方案:

-
蚂蚁金服的ant design是一个很好的前端框架封装,但是在使用的过程中往往会遇到一些配置问题,比如使用ant design pro 3.0以上版本时,它采用了新的umi作为底层架构,在这里做一些它的配置简单的记录。 plugins Type: Array Default: [] export default { plugins: [ 'umi-plugin-react',
-
umi官方入门指南:https://umijs.org/guide/getting-started.html 当按照官方入门指南进行安装和环境配置的时候,使用yarn安装好umi后,检查umi版本号的时候,即umi -v,显示umi并不是内部或外部命令,然后使用npm安装,npm install -g umi,安装好后,检查umi版本,umi是可以识别的,但是版本号确实1.x版本,版本有些老。 为
-
在/umi/lib/forkedDev.js中有这么几行核心代码,还引入了好几个文件,好复杂,现在一一解析一下 var _ServiceWithBuiltIn = require("./ServiceWithBuiltIn"); var _getCwd = _interopRequireDefault(require("./utils/getCwd")); var _getPkg = _int
-
一款纯粹的本地化的离线OCR识别,在Github上开源免费,你不需联网,运行软件后即可识别。 主要特性 免费:Github上开源免费软件。 方便:绿色版,不需安装,解压即可使用,不需要联网 准确:采用PP-OCRv2.6 cpu_avx_mklOCR识别引擎,速度快,OCR识别准确。 实用:支持批量识别、支持输出纯文本文件;支持快捷键,支持排除区域 mark一下 原文来源:Umi-OCR,无需联网
-
树洞 OCR 文字识别是一款跨平台的 OCR 小工具 下载地址:百度网盘 提取码:m6d8 xxx-with-jre.xx 是完整版,带运行环境;如果精简版不能正常工作,请下载完整版使用; 文字识别使用了各云平台开发的识别接口,因此需要联网才能正常使用; 安装路径请勿包含中文字符; 本程序使用 JavaFX 开发,使用前请务必安装 Java8 运行环境(完整版无需安装 Java8)。 程序使用 启
-
本文向大家介绍Python文字截图识别OCR工具实例解析,包括了Python文字截图识别OCR工具实例解析的使用技巧和注意事项,需要的朋友参考一下 一、简介 你一定用过那种“OCR神器”,可以把图片中的文字提取出来,极大的提高工作效率。 今天,我们就来做一款实时截图识别的小工具。顾名思义,运行程序时,可以实时把你截出来的图片中的文字识别出来。 二、模块 三、获取百度应用接口 AI开放平台文档中心
-
本文向大家介绍java实现百度云OCR文字识别 高精度OCR识别身份证信息,包括了java实现百度云OCR文字识别 高精度OCR识别身份证信息的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了java实现百度云OCR识别的具体代码,高精度OCR识别身份证信息,供大家参考,具体内容如下 1.通用OCR文字识别 这种OCR只能按照识别图片中的文字,且是按照行识别返回结果,精度较低。 首先引入依
-
我已经使用HTK(Hidden Markov Model Tool Kit)来识别用于控制Android应用程序的特定命令,但在这种情况下,我需要将一些语音数据传递给服务器,这可能会耗费更多时间。 为了防止这种延迟,我正在考虑使用pocketsphinx通过Android应用程序在本地识别语音数据,这样我就不需要将音频传递给服务器。 如果这是一个好主意,那么从头开始学习pocketsphinx容易
-
更新时间:2019-07-19 10:48:36 节点简介 人脸识别/图像识别/OCR节点属于智能节点,区别在于封装的云市场api功能不同。人脸识别节点主要有人数检测、人脸身份证对比、性别年龄情绪识别等功能。图像识别节点主要有烟雾火焰火灾识别、动物识别、植物识别、植物花卉识别等功能。OCR节点主要有驾驶证识别、车牌识别、身份证识别等功能。 使用场景 如果您需要进行人数检测、人脸身份证对比、性别年龄
-
在飞行模式下,按下按钮,一个声音退出输入屏幕,输入出现的声音请重新输入,上周可以正常使用,谷歌很长时间找不到解决方案,希望帮助离线谷歌语音已经设置好 公共void onclick1(视图v) { } 受保护的void onActivityResult(int requestCode、int resultCode、Intent data){ }