《同花顺2024春招》专题
-
 天音通信 运营管理岗 春招一面面经
天音通信 运营管理岗 春招一面面经面试形式:1v1 问题整理: 1.自我介绍 2.体现你领导力的一次经历 3.你愿意成为小组内付出比较多的那一种人吗 4.进入工作后发现岗位并不是非常适合自己,你会怎么做? 5.为什么不在实习公司转正 6.在印象中经历压力的表现与如何处理的 7.运营管理是轮岗的管培生,如果没有去到想去的城市,会去向领导争取调配到别的城市吗 8.如果一项任务很费精力与时间,没有人愿意去做,但这份工作是由你来组织的,你
-
 【前端校招面经】快手2023春招前端面经
【前端校招面经】快手2023春招前端面经base: bj 岗位: 前端 业务: 快手电商 背景: 这次是上一次电商一面后的二面 自我介绍 过往项目经历 讲讲你实现过的 React 组件 讲一讲你在过往实习经历里面, 最让你有成就感的事情是什么 如何衡量前端性能 前端页面如何排查 bug 事件循环: 看代码说结果 代码题: 获取一个数组中前 n 个最大的值, 你能想到几种方法 如果大数组的 length < n, 则递归处理小的子数组 反
-
使用3个打印不同范围的线程按排序顺序打印数字
这个问题是在电子艺术采访中提出的。 有三条线。第一个线程打印1到10个数字。第二个线程打印从11到20的数字。第三条线从21到30。现在这三个线程都在运行。然而,数字是按不规则的顺序打印的,如1、11、2、21、12等。 如果我想让数字按排序顺序打印,比如1,2。。。我该怎么处理这些线呢?
-
按字母顺序排列.properties文件中的键,同时忽略区分大小写
我有一个函数,它将.properties文件中的值存储到树映射(translatedMap)中,然后从“keymap”中检索新值并将它们也存储到“translatedMap”中。问题是,无论我做什么,似乎总是把大写键和非大写键分开。下面是我的代码: 我得到的输出是这样的: 当我想让它出来的时候: alowercase.key=value3 alother lowercase.key=value4
-
大火花分区尺寸的缺点
我读到过,太多的小分区会因为开销而损害性能,例如,向执行器发送大量任务。 使用最大的分区的缺点是什么?例如,为什么我会看到100s的MB范围内的建议? 如果丢失了一个分区,则需要进行大量的重新计算。对于许多较小的分区,您可能会更经常地丢失分区,但在运行时中的差异会更小。 如果在大分区上执行的少数任务中有一个任务的计算时间比其他任务长,这将使其他核心未被利用,但使用较小的分区,可以更好地在集群中分配
-
 花旗一面11.14(四十五分钟)
花旗一面11.14(四十五分钟)海外经历有么? 深挖竞赛经历? 实习经历? 前端搭建在webservice上?怎么搭建这个webservice,怎么提供? http和https差异? 熟悉哪些协议 https协议?证书放在哪里? CDN服务?项目中是否有使用么? 延迟加载(懒加载) json全称 async和sync异步同步区别? 页面loading太慢,如何debug 未来的规划 实习学业是否冲突? 印象最深刻的实习工作内容?
-
mysql LIKE查询花费太长时间
问题内容: SQL: 用户索引: 个人资料索引 解释 : 上面的查询大约需要0.1221 我怎样才能使其运行更快? 问题答案: 我删除了此查询,因此搜索完成后不会显示总结果数。 似乎是临时解决方案,甚至是永久解决方案。
-
 Canvas实现动态的雪花效果
Canvas实现动态的雪花效果本文向大家介绍Canvas实现动态的雪花效果,包括了Canvas实现动态的雪花效果的使用技巧和注意事项,需要的朋友参考一下 效果如下: 代码如下: 以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持呐喊教程!
-
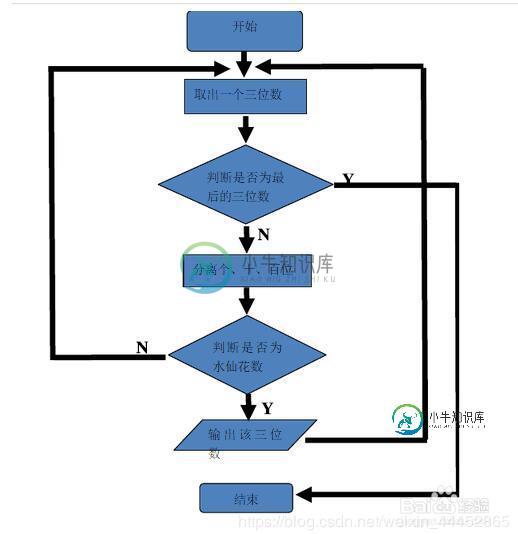 java实现水仙花数的计算
java实现水仙花数的计算本文向大家介绍java实现水仙花数的计算,包括了java实现水仙花数的计算的使用技巧和注意事项,需要的朋友参考一下 看到标题java实现水仙花数,首先先要知道什么是水仙花数,具体了解一下 所谓“水仙花数”是指一个三位数,其各位数字立方和等于该数 列如153=1*1*1+5*5*5+3*3*3 那么153就是水仙花数,首先是分析需要的功能,首先他是一个3位数。 那值一定在100-1000之间,必定
-
火花Kafka生产者可串行化
我想出一个例外: 在这个程序中,我尝试从hdfs路径读取记录,并将它们保存到Kafka中。问题是当我移除关于向Kafka发送记录的代码时,它运行得很好。我错过了什么?
-
DataProc上的Executor心跳超时火花
-
火花:删除所有重复的行
我有一个数据集,如下所示: 但不管用。
-
 Cassandra火花连接器读取性能
Cassandra火花连接器读取性能我有一些Spark经验,但刚开始使用Cassandra。我正在尝试进行非常简单的阅读,但性能非常差——不知道为什么。这是我正在使用的代码: 所有3个参数都是表上键的一部分: 主键(group\u id,epoch,group\u name,auto\u generated\u uuid\u field),聚类顺序为(epoch ASC,group\u name ASC,auto\u generat
-
火花数据帧连接字符串
如何使用Spark-Scala连接日期和时间列(两个字符串)
-
解析火花sql的复杂类型
数据-我使用XML中的许多附加列获取此类数据,并使用com。databricks spark-xml\u 2.11库,用于将xml数据转换为数据帧。 要求-必须从数组(struct)类型或列custom\u属性转换数据。示例中的custom\u属性,如示例输出所示。My struct有三个字段,分别命名为“\u VALUE”、“属性\u id”、“值”。我需要将属性id转换为列名称,数据为-检查“