《算法引流:》专题
-
如何解释这种换币算法
我试图找到一个简单问题的直接答案...在这里它是... 假设你有一个硬币更换算法,在面值为d(1)=1、d(2)=7和d(3)=10的系统中,n=10。 现在给出了教科书中算法的实现。。 结果会不会是:“使用10枚面额为1的硬币”? 这是因为当然,以我的理解,denom[1]=1,denom[2]=7,denom[3]=10。正确吗? 如果是这样的话,这个算法就不会被认为是最优的,对吗? 但是,代
-
动态换币算法(最优结果)
我已经得到了动态编程的这部分代码(找到硬币变化的最佳组合。例如,如果我们有两个价值3和4的硬币- 给定金额的总硬币数量可以从该数组的最小值[总和]中找到。但我试图获取的其他信息(哪枚硬币价值多少)似乎几乎不可能找到。此外,从阵列硬币[sum][0]中,我只能找到最后一枚使用的硬币,在本例中是3。 如您所见,它会检查从1到11的所有内容,但当它达到11时,它会存储正确数量的硬币(3)和最后使用的硬币
-
java.security.cert.CertificateException:证书不符合算法约束
-
最小切片位置N阶算法
给出了一个由N个整数组成的非空零索引数组。一对整数(P,Q),如0≤ P 编写一个函数: int解(int A[],int N); 给定一个由N个整数组成的非空零索引数组a,它将以最小的平均值返回切片的起始位置。如果有多个切片具有最小平均值,则应返回该切片的最小起始位置。 假定: N是[2..100000]范围内的整数;数组A的每个元素都是范围内的整数[−10,000..10,000]. 复杂性:
-
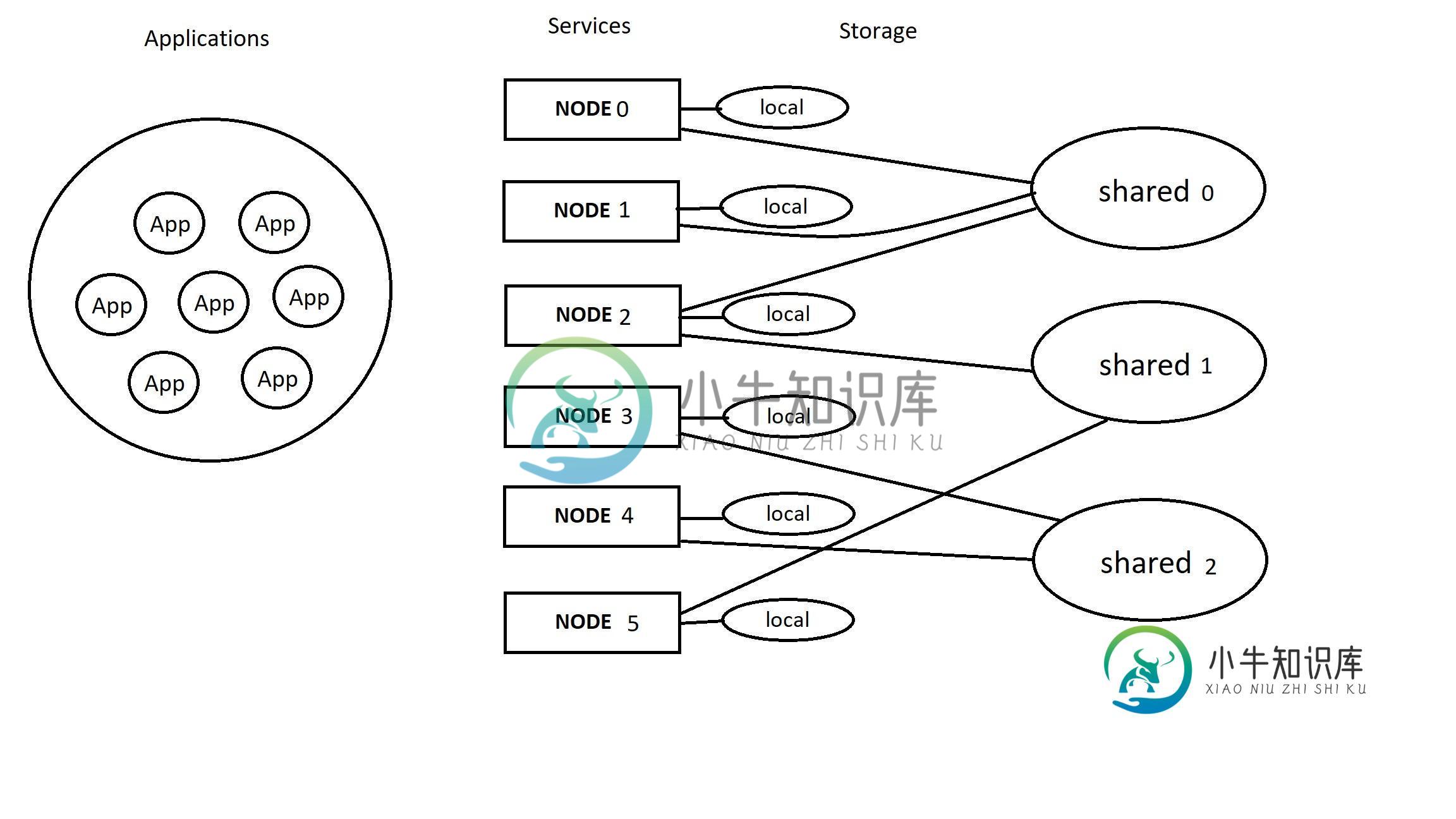 具有限制的再平衡算法
具有限制的再平衡算法请帮助解决以下问题。 给出了以下实体: < li >应用。应用程序驻留在存储上,它们通过服务节点产生流量。 < li >服务。服务分为几个节点。每个节点都可以访问本地或/和共享存储。 < li >存储。这是应用程序驻留的地方。它可以是本地的(仅连接到一个服务节点),也可以由几个节点共享。 规则: 每个应用程序都放置在某个特定的存储上。并且不能改变存储 只要新的服务节点可以访问应用程序的存储,应用程
-
Dijkstra算法中的优先级队列
这是我写的Dijkstra算法的代码: 在这方面我不能理解的工作 这涉及到: < code>()运算符在这里有什么用?我是说它在这段代码中是如何运作的? 还有为什么我们使用
-
带优先级队列的Dijkstra算法
在我实现Dijkstra算法的过程中,我有1个数组(包含所有节点)和1个优先级队列(包含所有节点)。每当一个节点排队时,我都会用新的距离和它来自哪里来更新所有相邻的节点,这样我就可以回溯路径。 优先级队列中的节点更新为新距离,数组中的节点更新为它来自的位置和新距离。当节点出列时,数组中的最终距离会更新: 用前一个节点的信息更新数组和用距离更新优先级队列是否可以接受? 只要找到更好的距离,就会发生这
-
确定算法的时间复杂度
下面是我写的一些伪代码,给定一个数组A和一个整数值k,如果与k之和中有两个不同的整数,则返回true,否则返回false。我正试图确定这个算法的时间复杂度。 我猜这个算法在最坏的情况下的复杂度是O(n^2)。这是因为第一个for循环运行n次,该循环内的for循环也运行n次。if语句进行一次比较,如果为true,则返回一个值,这两个操作都是常量时间操作。最后的return语句也是一个常数时间操作。
-
JAVA安全NoSuchAlgorithmException:算法PBKDF2WithHmacSHA1不可用
我有java 1.4版本的代码,我们有一个新的要求,比如从另一个webservice响应中解密密码,因此必须使用AES 256解密,得到以下异常: 我试图将jce\U policy\u 1-4版本JAR复制到java home security文件夹中,但仍遇到上述异常 Java 1.4中是否有不更改为1.5的解决方案,因为运行jboss server 3.2.3版将不支持Java 1.5。
-
Tarjan算法的Ruby版本中的Bug
http://en.wikipedia.org/wiki/tarjan's_strongly_connected_components_algorithm http://en.algoritmy.net/article/44220/tarjans-算法 我无法在我的Ruby版本的Tarjan算法中找出这个bug用于强连接组件。我得到了Kosaraju-Sharir算法,我的Tarjan算法在Rub
-
这个问题的最有效算法
我已经提出了几个解决方案,但我认为它们的效率不高,而且我很难计算它们的复杂性。 计划A)对于我随机选择的[1,N]范围内的每一个整数,我检查它是否被占用。如果是,我重新滚动直到我得到一个未被占用的整数。这对于N的高阶数来说变得低效,因为碰撞非常高。 计划B)每次迭代时,我遍历数组的所有值,那些我没有占用的我会写在一个列表中。之后,我洗牌列表(例如通过Fisher-Yates shuffle?)并任
-
使用NetworkX的社区检测算法
我有一个网络是一个图形网络,它是Email-Eu网络,在这里可用。 该数据集具有实际数据集,这是一个由大约1005个节点组成的图,其边缘形成了这个巨大的图。它还具有节点及其相应社区(部门)的地面真相标签。这些节点中的每一个都属于42个部门中的一个。 我想在图上运行一个社区检测算法,为每个节点找到相应的部门。我的主要目标是找到最大社区中的节点。 因此,首先我需要找到前42个部门(社区),然后在其中最
-
Tic Tac Toe确定胜利者算法
我在C和一般编程方面是个新手,我想知道这段代码的性能/复杂性有多好,因为它与我在SO的其他帖子中发现的不同。for循环是否使这变得不必要的复杂?
-
这样的分区算法正确吗?
我一直在看《破解编码面试》(5E,119页)一书中的分区函数。我将其复制如下: 给定此数组: 1 2 3 3 5 6 4 左=4,右=4。退出 然而,我最后得到的数组是:
-
Docker build无法计算缓存密钥
我有下面的项目结构 我在中有一个目录名为。 我的Dockerfile如下: 在我运行下面的命令从这个docker文件构建图像之后 我得到了下面的错误 我的问题是为什么我有这个错误?以及如何解决它? 我在Windows 10 20H2 19042.964上使用了 我看到Docker-未能计算缓存密钥:未找到-在Visual Studio和一些内部链接中运行良好,但没有找到任何有用的东西。 我正在处理