
具有限制的再平衡算法

请帮助解决以下问题。
给出了以下实体:
-
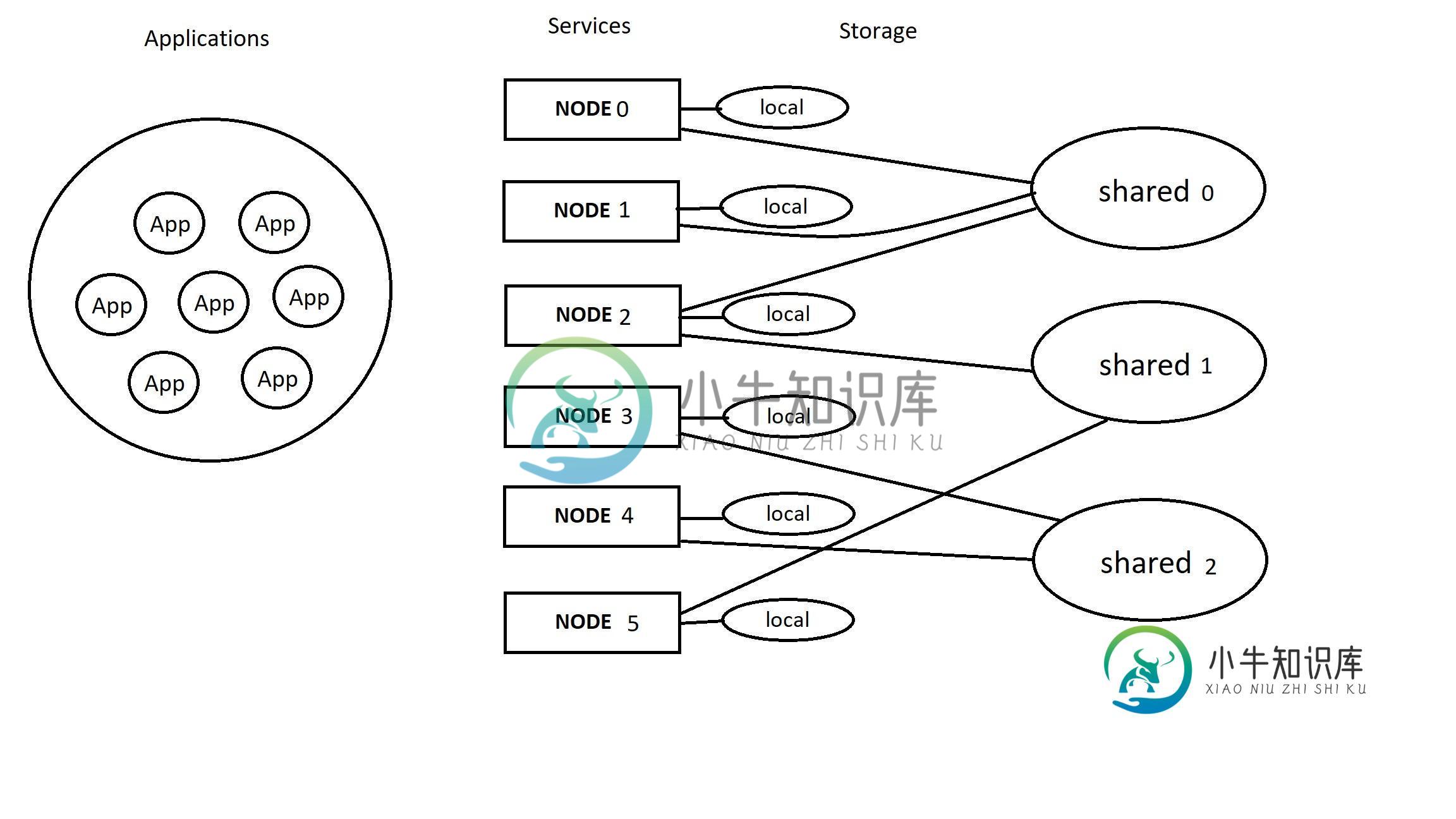
< li >应用。应用程序驻留在存储上,它们通过服务节点产生流量。 < li >服务。服务分为几个节点。每个节点都可以访问本地或/和共享存储。 < li >存储。这是应用程序驻留的地方。它可以是本地的(仅连接到一个服务节点),也可以由几个节点共享。
规则:
- 每个应用程序都放置在某个特定的存储上。并且不能改变存储
- 只要新的服务节点可以访问应用程序的存储,应用程序的服务节点就可以更改为另一个
例如,如果 App 驻留在 Node0 的本地存储上,则它只能由 Node0 提供服务。但是,如果应用驻留在存储共享0 上,则可以由 Node0、Node1 或 Node2 提供服务。
问题是找到在服务节点之间重新平衡应用程序的算法,因为所有应用程序都已经放在它们的数据存储中。并使这种重新平衡尽可能公平。
如果我们以共享2存储为例,解决方案似乎微不足道:我们计算Node3和Node4的应用程序数量,并在它们之间平均分配所有应用程序。但是当涉及到共享1时,它变得更加复杂,因为Node2也可以访问共享0存储。因此,在从组[Node2, Node5]重新平衡应用程序时,我们还必须考虑来自组[Node0, Node1, Node2]的应用程序。组[Node2, Node5]和[Node0, Node1, Node2]相交,应该一次对所有组执行重新平衡。
共有1个答案

我认为匈牙利匹配算法会满足你的需要。然而,尝试自己的方法可能是一个足够简单的问题。
如果将所有未连接的图分开,每个图将有一组共享存储单元,每个存储单元与一组应用程序关联。如果将这些应用程序平均分布在每个存储的关联节点上,则某些节点的应用程序会比其他节点多。这些节点将连接到多个共享存储单元。
如果所有空闲节点都被填充,则连接图中的任何两个节点之间应该始终存在传递关系,这样一个应用程序可以减少,另一个应用程序可以增加,即使需要一些中间位移。因此,如果您迭代地将应用程序沿着从最重节点到最轻节点的路径移动,如果您到达一个空闲节点,则可以快捷方式,并根据需要在任何中间节点交换应用程序以继续沿着该路径通过一个或多个共享存储单元,当最重和最轻节点的数量相差不超过一个时,您应该保持平衡。
-
Kafka再平衡算法是否适用于不同主题? 假设我有5个主题,每个主题都有10个分区,同一消费者组中有20个消费者应用程序实例,每个实例都订阅了这5个主题。 Kafka会尝试在20个实例中平衡50个分区吗? 还是它只在一个主题内保持平衡,因此10个第一个实例可能(或可能)接收所有50个分区,而其他10个实例可能保持空闲? 我知道,在过去,Kafka并没有在不同的主题之间取得平衡,但现在的版本呢?
-
有人能告诉我Kafka消费者的再平衡算法是什么吗?我想了解分区计数和消费者线程是如何影响这一点的。 非常感谢。
-
我有4个单一分区和应用程序的三个实例的主题。我试图通过编写一个自定义的PartitionGrouper来实现可伸缩性,它将创建如下3个任务: 第一个实例-topic1,分区0,topic4,分区0 第二个实例-主题2,分区0 第三实例-桌面3,分区0 我将NUM_STANDBY_REPLICAS_CONFIG配置为1,因为它将在本地维护状态(也可以消除invalidstatestore异常)。 上
-
当我们的kafka主题中有多个分区时,分区重新平衡是一件常见的事情吗? 这并不一定意味着我们的应用程序存在延迟或问题? 我一直看到分区被撤销和重新分配的日志。
-
我知道在你的流中的任何时间点都可能发生再平衡。当它发生时,由于没有提交给定偏移量的最新偏移量,可能会发生事件的重新处理。 Kafka流是否允许在重新平衡发生之前完成任何飞行中处理?我的意思是,你的应用程序正在消耗一个记录(在你的过程方法内部),发生一个再平衡事件。该处理是否立即中止或允许处理方法完成? 一个具体的例子是 最后一次计算是否会在状态存储中结束并转发到接收器主题?因此,这意味着当重新平衡