《算法开发实习》专题
-
C语言实现K-Means算法
本文向大家介绍C语言实现K-Means算法,包括了C语言实现K-Means算法的使用技巧和注意事项,需要的朋友参考一下 一、聚类和聚类算法 聚类,就是将数据对象划分成若干个类,在同一个类中的对象具有较高的相似度,而不同的类相似度较小。聚类算法将数据集合进行划分,分成彼此相互联系的若干类,以此实现对数据的深入分析和数据价值挖掘的初步处理阶段。例如在现代商业领域,聚类分析算法可以从庞大的数据集合中对消
-
python实现ID3决策树算法
本文向大家介绍python实现ID3决策树算法,包括了python实现ID3决策树算法的使用技巧和注意事项,需要的朋友参考一下 决策树之ID3算法及其Python实现,具体内容如下 主要内容 决策树背景知识 决策树一般构建过程 ID3算法分裂属性的选择 ID3算法流程及其优缺点分析 ID3算法Python代码实现 1. 决策树背景知识 决策树是数据挖掘中最重要且最常用的方法之一,主要应用于数据
-
 python实现红包裂变算法
python实现红包裂变算法本文向大家介绍python实现红包裂变算法,包括了python实现红包裂变算法的使用技巧和注意事项,需要的朋友参考一下 本文实例介绍了python实现红包裂变算法,分享给大家供大家参考,具体内容如下 Python语言库函数 安装:pip install redpackets 使用: 1、前情提要 过年期间支付宝红包、微信红包成了全民焦点,虽然大多数的红包就一块八角的样子,还是搞得大家乐此不疲。作为
-
Python贪心算法实例小结
本文向大家介绍Python贪心算法实例小结,包括了Python贪心算法实例小结的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python贪心算法。分享给大家供大家参考,具体如下: 1. 找零钱问题:假设只有 1 分、 2 分、五分、 1 角、二角、 五角、 1元的硬币。在超市结账 时,如果 需要找零钱, 收银员希望将最少的硬币数找给顾客。那么,给定 需要找的零钱数目,如何求得最少的硬币数
-
C++插入排序算法实例
本文向大家介绍C++插入排序算法实例,包括了C++插入排序算法实例的使用技巧和注意事项,需要的朋友参考一下 插入排序 没事喜欢看看数据结构和算法,增加自己对数据结构和算法的认识,同时也增加自己的编程基本功。插入排序是排序中比较常见的一种,理解起来非常简单。现在比如有以下数据需要进行排序: 10 3 8 0 6 9 2 当使用插入排序进行升序排序时,排序的步骤是这样的: 10 3 8 0 6 9 2
-
C++冒泡排序算法实例
本文向大家介绍C++冒泡排序算法实例,包括了C++冒泡排序算法实例的使用技巧和注意事项,需要的朋友参考一下 冒泡排序 大学学习数据结构与算法最开始的时候,就讲了冒泡排序;可见这个排序算法是多么的经典。冒泡排序是一种非常简单的排序算法,它重复地走访过要排序的数列,每一次比较两个数,按照升序或降序的规则,对比较的两个数进行交换。比如现在我要对以下数据进行排序: 10 3 8 0 6 9 2 当使用冒泡
-
C++选择排序算法实例
本文向大家介绍C++选择排序算法实例,包括了C++选择排序算法实例的使用技巧和注意事项,需要的朋友参考一下 选择排序 选择排序是一种简单直观的排序算法,它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 选择排序的主要优点与数据移动有关。如果某个元素位于正确
-
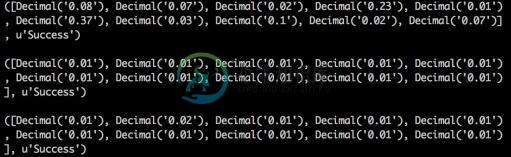
 python实现k-means聚类算法
python实现k-means聚类算法本文向大家介绍python实现k-means聚类算法,包括了python实现k-means聚类算法的使用技巧和注意事项,需要的朋友参考一下 k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法。 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重
-
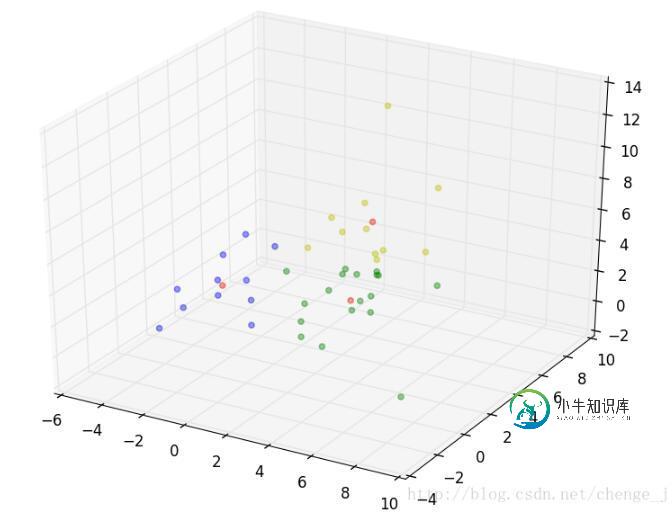
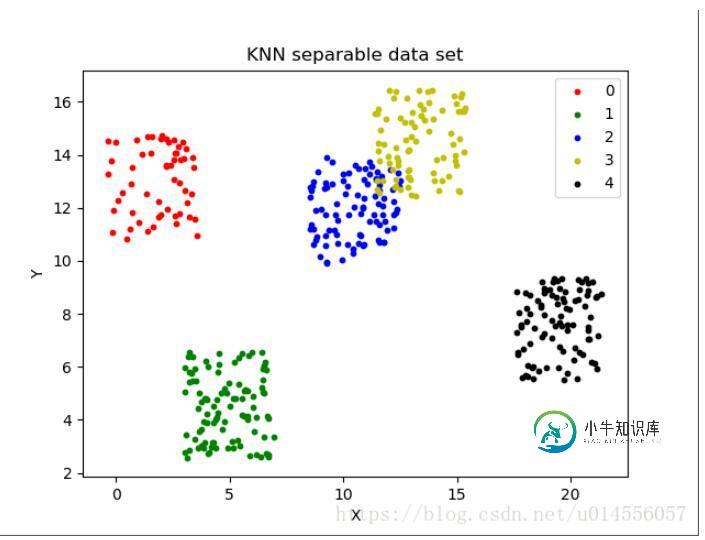 python可视化实现KNN算法
python可视化实现KNN算法本文向大家介绍python可视化实现KNN算法,包括了python可视化实现KNN算法的使用技巧和注意事项,需要的朋友参考一下 简介 这里通过python的绘图工具Matplotlib包可视化实现机器学习中的KNN算法。 需要提前安装python的Numpy和Matplotlib包。 KNN–最近邻分类算法,算法逻辑比较简单,思路如下: 1.设一待分类数据iData,先计算其到已标记数据集中每个数
-
Python算法之栈(stack)的实现
本文向大家介绍Python算法之栈(stack)的实现,包括了Python算法之栈(stack)的实现的使用技巧和注意事项,需要的朋友参考一下 本文以实例形式展示了Python算法中栈(stack)的实现,对于学习数据结构域算法有一定的参考借鉴价值。具体内容如下: 1.栈stack通常的操作: Stack() 建立一个空的栈对象 push() 把一个元素添加到栈的最顶层 pop() 删除栈最顶层的
-
“中位数”算法的Python实现
我已经用python编写了medians算法的median的实现,但是它似乎没有输出正确的结果,而且对我来说它似乎也没有线性复杂度,知道我哪里出错了吗? 这个函数是这样调用的: 乐:不好意思。GetMed是一个简单地对列表排序并返回len(list)处的元素的函数,它应该在那里被选择,我现在修复了它,但我仍然得到错误的输出。至于缩进,代码工作没有错误,我看不出有什么问题:-?? LE2:我期望50
-
Prim算法在Java中的实现
我试图在Java中实现Prim的算法,用于我的图形HashMap LinkedList和一个包含连接顶点和权重的类Edge: 我的想法是,从一个给定的顶点开始:1)将所有顶点保存到一个LinkedList中,这样每次访问它们时我都可以删除它们2)将路径保存到另一个LinkedList中,这样我就可以得到我的最终MST 3)使用PriorityQueue找到最小权重 最后我需要MST,边数和总重量。
-
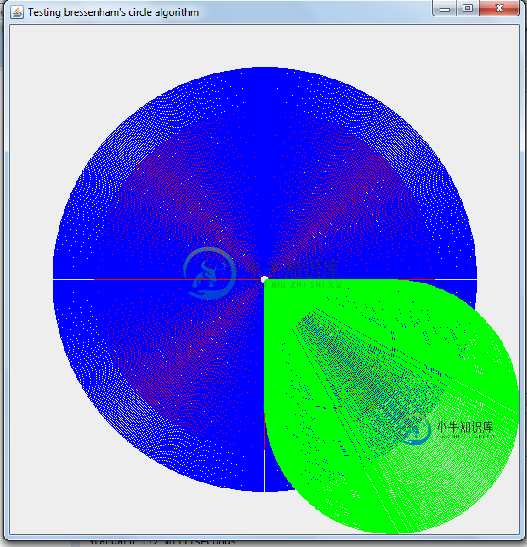 Bresenham圆绘制算法的实现
Bresenham圆绘制算法的实现我已经写了一个Bresenham的圆绘制算法的实现。该算法利用了圆的高度对称特性(它只计算第一个八分之一的点,并利用对称性绘制其他点)。因此,我希望它会非常快。《图形编程黑皮书》第35章的标题是“Bresenham是快的,而且快是好的”,虽然它是关于线条绘制算法的,但我可以合理地预期圆形绘制算法也很快(因为原理是一样的)。 这是我的java,摇摆实现 此方法使用以下方法: getNativeX和g
-
最优化算法实例讲解
DFS(深度优先搜索)是一种常见的算法,我们平时遇到的大部分题目都可以用 DFS 解决,但是一般情况下,这都是骗分算法,很少会有爆搜为正解的题目。因为 DFS 的时间复杂度特别高。 一、定义 DFS(深度优先搜索)定义上的深度优先搜索的思路与树的先序遍历非常相似,是针对图的搜索而提出的一种算法,下面是算法导论上的解释: 在深度优先搜索中,对于最新发现的顶点,如果它还有以此为顶点而未探测到的边,就沿
-
sift算法的编译与实现
sift算法的编译与实现 代码:Rob Hess维护的sift 库。 环境:windows xp+vc6.0。 条件:opencv1.0、gsl-1.8.exe 昨日,下载了Rob Hess的sift库,将其源码粗略的看了看,想要编译时,遇到了不少问题,先修改了下代码,然后下载opencv、gsl。最后,几经周折,才最终编译成功。 以下便是sift源码库编译后的效果图: 为了给有兴趣实现sift算