《算法求职》专题
-
SQL高效的计划生成算法
问题内容: 想象一下设有 分支机构的 教育中心。该教育中心的 课程 对所有分支机构都是通用的。 分行 *管理员生成的每个课程的每个分支中的 *房间 。例如,管理员输入数学课程的房间数。系统生成3个房间。换句话说,它们受到计数的限制。 每个房间每天有5个可用的教学时间。换句话说,每个教学小时(共5个)将有1个不同的学生组。 学生 -也按分支分组。每个学生都喜欢按周计划()上中学。 一周的1、3、5天
-
结合无损数据压缩算法
我想知道我们可以在多大程度上进行无损数据压缩;我无法找到一个无损算法的在线模拟器来执行一些经验测试。我可以自己做一个,但不幸的是,我在这段时间没有足够的时间;我仍然对我的直觉感到好奇,我将解释一下。 让我们只看两种更流行的算法:
-
antlr4语法中“~”运算符的意义
我正在努力理解语法文件:https://github.com/antlr/grammars-v4/blob/master/url/url.g4 我无法理解运算符在最后的Character集合中:我知道代表不在集合运算符中,如:https://github.com/antlr/antlr4/blob/master/doc/lexer-rules.md即是匹配任何单个字符不在描述的集合中,但如何解释当
-
C DFS中的迷宫回溯算法?
我是C的新手,我目前正在一个项目中创建一个使用DFS算法生成的迷宫。 我已经成功地生成了一条路径,例如 如上所述, Source是初始单元,1是我根据随机邻居创建的路径,D是“死胡同”。所以,如果可能的话,我想回到S,从另一个方向开始。我该如何处理队列和堆栈?有人能解释一下吗?非常感谢你?
-
浮点运算中尾数的乘法
关于尾数(关于浮点运算的指南),实际上如何将两个尾数相乘? 假设IEEE 754单精度浮点表示。 假设一个数字的尾数为,将被编码为(十进制为)。第二个数字的尾数为,将被编码为(十进制为)。 <代码>1.5 x 1.125=1.6875。 编码为(十进制为)。但是不等于... 尾数乘法是如何工作的,以至于将4194304(1.5)乘以1048576(1.125),得到5767168(1.6875)?
-
c#数学运算的一般方法
我想创建一个执行基本数学运算的通用方法。例如,如果将double传递给函数,它将返回double。 这对我不起作用。 编辑:我得到一个错误运算符“*”不能应用于“T”和“int”类型的操作数 然而,我想知道是否有其他方法来实现我正在努力的目标? 谢啦
-
哈夫曼树算法理解困难
我在基于频率表的哈夫曼树上工作。频率表是通过计算给定字符串中字符的频率并将相应项(字符和频率)放置在链接列表中生成的。然后,我需要将项目按频率顺序放置在哈夫曼树中。我得到了它背后的逻辑是确保每个子树都有右节点和左节点,添加它们的频率,用它们添加的频率创建一个根节点,将下一个频率分别放在左树和右树中,并重复这个过程,直到没有更多的频率,子树与添加其频率的根连接;我遇到的问题是如何实现代码。 代码相当
-
 无法计算生成计划-Eclipse Maven
无法计算生成计划-Eclipse Maven当我尝试构建项目时。生成失败,出现以下消息。 我看到了两个类似的问题,并尝试了答案中提到的一切。 我尝试过的事情。
-
如何解释这种换币算法
我试图找到一个简单问题的直接答案...在这里它是... 假设你有一个硬币更换算法,在面值为d(1)=1、d(2)=7和d(3)=10的系统中,n=10。 现在给出了教科书中算法的实现。。 结果会不会是:“使用10枚面额为1的硬币”? 这是因为当然,以我的理解,denom[1]=1,denom[2]=7,denom[3]=10。正确吗? 如果是这样的话,这个算法就不会被认为是最优的,对吗? 但是,代
-
动态换币算法(最优结果)
我已经得到了动态编程的这部分代码(找到硬币变化的最佳组合。例如,如果我们有两个价值3和4的硬币- 给定金额的总硬币数量可以从该数组的最小值[总和]中找到。但我试图获取的其他信息(哪枚硬币价值多少)似乎几乎不可能找到。此外,从阵列硬币[sum][0]中,我只能找到最后一枚使用的硬币,在本例中是3。 如您所见,它会检查从1到11的所有内容,但当它达到11时,它会存储正确数量的硬币(3)和最后使用的硬币
-
java.security.cert.CertificateException:证书不符合算法约束
-
最小切片位置N阶算法
给出了一个由N个整数组成的非空零索引数组。一对整数(P,Q),如0≤ P 编写一个函数: int解(int A[],int N); 给定一个由N个整数组成的非空零索引数组a,它将以最小的平均值返回切片的起始位置。如果有多个切片具有最小平均值,则应返回该切片的最小起始位置。 假定: N是[2..100000]范围内的整数;数组A的每个元素都是范围内的整数[−10,000..10,000]. 复杂性:
-
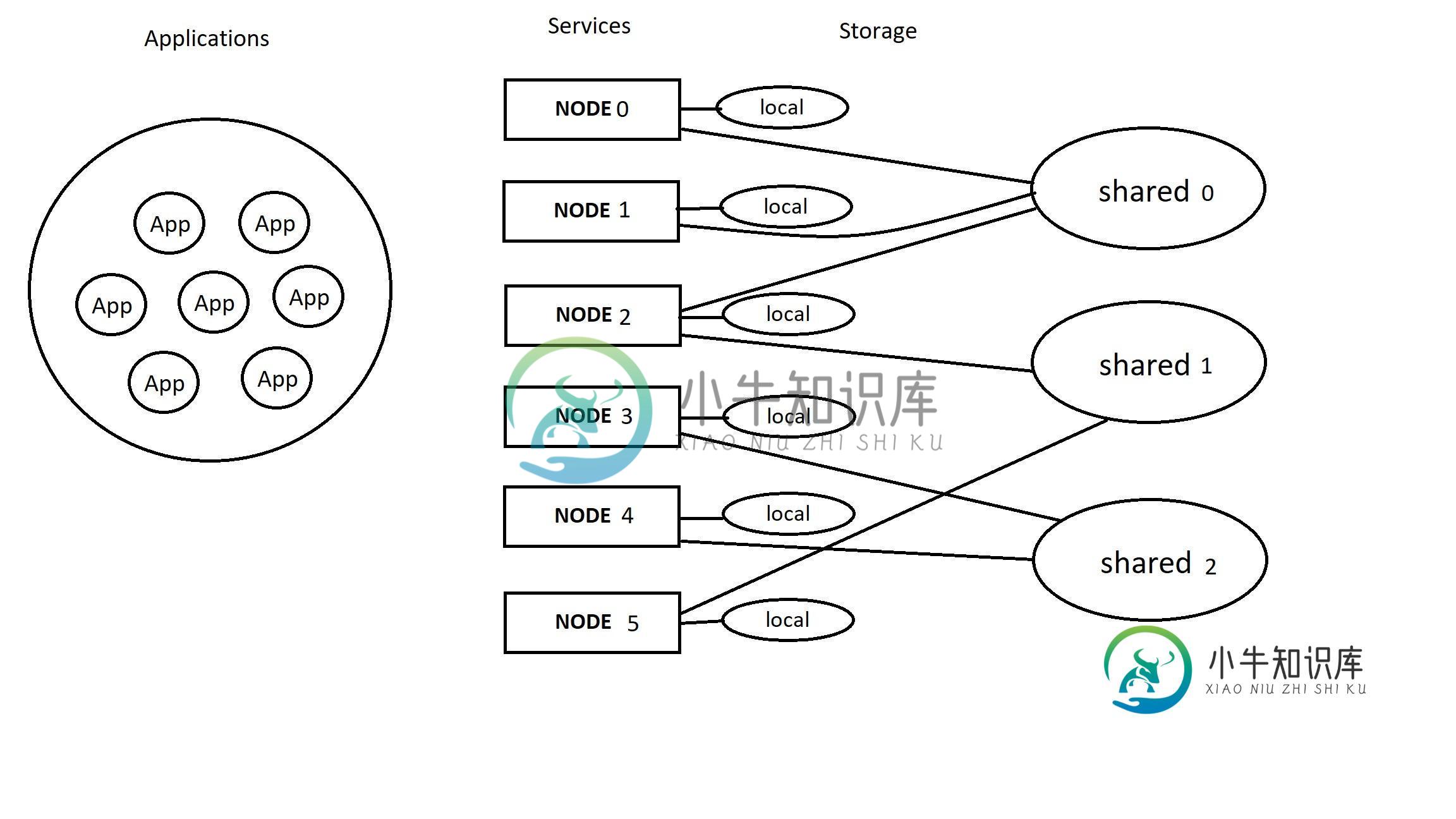 具有限制的再平衡算法
具有限制的再平衡算法请帮助解决以下问题。 给出了以下实体: < li >应用。应用程序驻留在存储上,它们通过服务节点产生流量。 < li >服务。服务分为几个节点。每个节点都可以访问本地或/和共享存储。 < li >存储。这是应用程序驻留的地方。它可以是本地的(仅连接到一个服务节点),也可以由几个节点共享。 规则: 每个应用程序都放置在某个特定的存储上。并且不能改变存储 只要新的服务节点可以访问应用程序的存储,应用程
-
Dijkstra算法中的优先级队列
这是我写的Dijkstra算法的代码: 在这方面我不能理解的工作 这涉及到: < code>()运算符在这里有什么用?我是说它在这段代码中是如何运作的? 还有为什么我们使用
-
带优先级队列的Dijkstra算法
在我实现Dijkstra算法的过程中,我有1个数组(包含所有节点)和1个优先级队列(包含所有节点)。每当一个节点排队时,我都会用新的距离和它来自哪里来更新所有相邻的节点,这样我就可以回溯路径。 优先级队列中的节点更新为新距离,数组中的节点更新为它来自的位置和新距离。当节点出列时,数组中的最终距离会更新: 用前一个节点的信息更新数组和用距离更新优先级队列是否可以接受? 只要找到更好的距离,就会发生这