《算法求职》专题
-
javascript运算符语法全面概述
本文向大家介绍javascript运算符语法全面概述,包括了javascript运算符语法全面概述的使用技巧和注意事项,需要的朋友参考一下 前面的话 javascript中的运算符大多由标点符号表示,少数由关键字表示,它们的语法言简意赅,它们的数量却着实不少。运算符始终都遵循着一些固定语法,只有了解并掌握这些内容,才能正确使用运算符。本文将主要介绍javascript运算符的语法概述 操作数个数
-
C#排序算法的比较分析
本文向大家介绍C#排序算法的比较分析,包括了C#排序算法的比较分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了C#的各种排序算法。分享给大家供大家参考。具体分析如下: 首先通过图表比较不同排序算法的时间复杂度和稳定性。 排序方法 平均时间 最坏情况 最好情况 辅助空间 稳定性 直接插入排序 O(n2) O(n2) O(n) O(1) 是 冒泡排序 O(n2) O(n2) O(n)
-
PHP实现货币换算的方法
本文向大家介绍PHP实现货币换算的方法,包括了PHP实现货币换算的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现货币换算的方法。分享给大家供大家参考。 具体实现代码如下: 上面的代码复制到一个新文件并将其保存为CurrencyConverter.php。当你需要转换包含类文件,称为“转换”功能。你需要输入自己的mysql数据库变量如登录详细信息。下面的例子将£2.50英镑转
-
Python版微信红包分配算法
本文向大家介绍Python版微信红包分配算法,包括了Python版微信红包分配算法的使用技巧和注意事项,需要的朋友参考一下 红包分配算法代码实现发给大家,祝红包大丰收! python 2.py 0.01 10 20 30 0.01 10 20 30 第1个人拿到红包数为:1.34, 余额为: 18.66 第2个人拿到红包数为:1.06, 余额为: 17.60 第3个人拿到红包数为:1.08, 余额
-
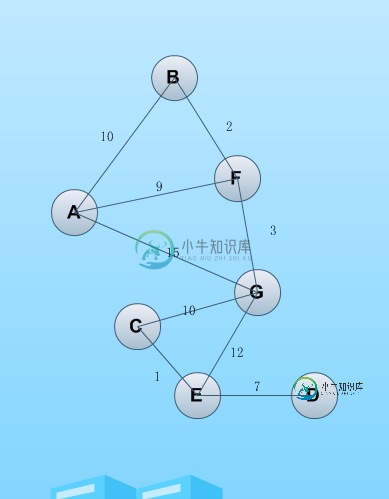 python编写的最短路径算法
python编写的最短路径算法本文向大家介绍python编写的最短路径算法,包括了python编写的最短路径算法的使用技巧和注意事项,需要的朋友参考一下 一心想学习算法,很少去真正静下心来去研究,前几天趁着周末去了解了最短路径的资料,用python写了一个最短路径算法。算法是基于带权无向图去寻找两个点之间的最短路径,数据存储用邻接矩阵记录。首先画出一幅无向图如下,标出各个节点之间的权值。 其中对应索引: A ——> 0 B——
-
Java 二分查找算法的实现
本文向大家介绍Java 二分查找算法的实现,包括了Java 二分查找算法的实现的使用技巧和注意事项,需要的朋友参考一下 二分查找又称折半查找,它是一种效率较高的查找方法。 折半查找的算法思想是将数列按有序化(递增或递减)排列,查找过程中采用跳跃式方式查找,即先以有序数列的中点位置为比较对象,如果要找的元素值小 于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。通过一次比较,将查找区间缩小一
-
C#常见算法面试题小结
本文向大家介绍C#常见算法面试题小结,包括了C#常见算法面试题小结的使用技巧和注意事项,需要的朋友参考一下 本文实例汇总了C#面试常见的算法题及其解答。具有不错的学习借鉴价值。分享给大家供大家参考。具体如下: 1.写出冒泡,选择,插入排序算法。 2.有一列数1,1,2,3,5,........求第30个数. 3. 程序设计: 猫大叫一声,所有的老鼠都开始逃跑,主人被惊醒。 4.有一个字符串 "I
-
Ruby实现的合并排序算法
本文向大家介绍Ruby实现的合并排序算法,包括了Ruby实现的合并排序算法的使用技巧和注意事项,需要的朋友参考一下 算法课的作业,利用分治法,合并排序。
-
Ruby实现的矩阵连乘算法
本文向大家介绍Ruby实现的矩阵连乘算法,包括了Ruby实现的矩阵连乘算法的使用技巧和注意事项,需要的朋友参考一下 动态规划解决矩阵连乘问题,随机产生矩阵序列,输出形如((A1(A2A3))(A4A5))的结果。 代码:
-
 使用javascript做在线算法编程
使用javascript做在线算法编程本文向大家介绍使用javascript做在线算法编程,包括了使用javascript做在线算法编程的使用技巧和注意事项,需要的朋友参考一下 基于node的readline一样可以使用标准流的输入输出 对于大学生在刚开始学习c ,c++, java的时候,写着hello word的代码,然后在命令框中输入输出; 基于很多算法的学习,在我短浅的认识中,身边的同学都是使用 c, c++,甚至是java去
-
JavaScrip常见的一些算法总结
本文向大家介绍JavaScrip常见的一些算法总结,包括了JavaScrip常见的一些算法总结的使用技巧和注意事项,需要的朋友参考一下 下面就简单列举一下javascript中常见的一些算法,需要的朋友可以做一下参考。当然这些算法不仅仅适用于javascript,同样也适用于其他语言。 一.线性查找: 比较简单,属于入门级的算法 二.二分查找: 又称折半查找,适用于已排好序的线性结构。 三.冒泡
-
javascript计算对象长度的方法
本文向大家介绍javascript计算对象长度的方法,包括了javascript计算对象长度的方法的使用技巧和注意事项,需要的朋友参考一下 计算对象的长度,即获取对象属性的个数,具体如下 方法一:通过for in 遍历对象,并通过hasOwnProperty判断是否是对象自身可枚举的属性 方法二:通过Object.keys()获取对象可枚举属性所组成的数组,并通过length获取对象长度 以上就是
-
java实现任意矩阵Strassen算法
本文向大家介绍java实现任意矩阵Strassen算法,包括了java实现任意矩阵Strassen算法的使用技巧和注意事项,需要的朋友参考一下 本例输入为两个任意尺寸的矩阵m * n, n * m,输出为两个矩阵的乘积。计算任意尺寸矩阵相乘时,使用了Strassen算法。程序为自编,经过测试,请放心使用。基本算法是: 1.对于方阵(正方形矩阵),找到最大的l, 使得l = 2 ^ k, k为整数并
-
java递归算法的实例详解
本文向大家介绍java递归算法的实例详解,包括了java递归算法的实例详解的使用技巧和注意事项,需要的朋友参考一下 递归三要素: 1、明确递归终止条件; 2、给出递归终止时的处理办法; 3、提取重复的逻辑,缩小问题规模。 1、1+2+3+…+n 2、1 * 2 * 3 * … * n 3、斐波那契数列 前两项均为1,第三项开始,每一项都等于前两项之和。即:1,1,2,3,5,8,… 4、二叉树的遍
-
算法规范-数据结构介绍
本文向大家介绍算法规范-数据结构介绍,包括了算法规范-数据结构介绍的使用技巧和注意事项,需要的朋友参考一下 算法定义为一组有限的指令,如果遵循这些指令,它们将执行特定的任务。所有算法必须满足以下条件 输入。一种算法具有零个或多个输入,这些输入是从一组指定的对象中获取或收集的。 输出。一种算法具有一个或多个与输入具有特定关系的输出。 确定性。必须明确定义每个步骤;每条指令必须清晰明确。 有限。该算法