《机器学习面试》专题
-
 小红书-机器学习算法工程师-一面
小红书-机器学习算法工程师-一面用的是赛码的面试系统,面试官到点发起了语音通话,在线IDE。 ------------------------------------------------------------------------------------ 自我介绍,五分钟结束,然后面试官没有就自我介绍提问。直接说开始做题,从这里感觉到这是KPI面了。 -----------------------------------
-
 美团机器学习算法岗校招面经(OC)
美团机器学习算法岗校招面经(OC)面试形式 3轮面试+1轮hr面。 时间线: 一面X 二面X+14 三面X+14+7 hr面X+14+7+7 其中,对时间信息进行脱敏,一面开始时间作为基准,记作X。例如,X+1表示距离一面的时间为一天。其中,对精确的时间也进行了相应的模糊处理,1-7天,就记作7天,可以认为是在一周内,8-14天,记作14天,可以认为在两周内。 一面(1h,X) 自我介绍 项目讲解与介绍,讲的自己上传的PPT(30
-
 24春招蚂蚁算法岗机器学习二面面经
24春招蚂蚁算法岗机器学习二面面经上周五一面结束,这周二约的二面。 全程20分钟,纯聊天。 面试官人巨好。 问了手里有的offer,为什么还在找。 然后是聊项目,论文的创新点。 之后就是反问了,给我科普了广告所做的内容。 问下一轮面试,如果通过就是HR面了。 面试官看时间还比较早,就继续聊了会儿。 面试官人巨好,也跟我说了对我的评价,需要和一面面试官讨论一下再确认结果。 真的是很愉快的一次面试。 许愿二面能够通过
-
 24春招蚂蚁算法岗机器学习一面面经
24春招蚂蚁算法岗机器学习一面面经笔试ak了被捞起来了,部门是支付宝广告业务技术部。 全程30min(感觉又要凉) 项目。问GRU的原理(这里重置门和更新门具体的作用记不清哪个是哪个了) 问到线性回归(平时用深度学习比较多,机器学习接触的少一些) 然后就做题了。。 三道题选一个即可,都是leetcode原题,分别是 16最接近的三数和 22括号生成 53最大子数组和 选第三个秒了 反问:业务、新人培养(问HR比较好)、深度学习多还
-
 美团机器学习/数据挖掘方向一面面经
美团机器学习/数据挖掘方向一面面经#美团求职进展汇总# #你收到了团子的OC了吗# 美团履约平台技术部,配送时间策略组 自我介绍,问了我学校和清华什么关系 1、上来一道算法题:找最长的回文串。用动态规划dp秒了。然后问怎么优化空间复杂度,想到从两遍同时找最长回文串来做。 2、然后根据简历来问,没想到简历拿错了,没拿我最新更新的简历。让我讲最拿手的项目。我共享屏幕展示了我最新的简历,讲我的SCI科研项目讲了半个小时。 3、问我ten
-
 百度机器学习算法春招一二三面面经
百度机器学习算法春招一二三面面经【一面】 1. word2vec的原理,skip-gram训练的具体流程,使用的损失函数,是怎么选择正负样本的,选择样本上有哪些优化算法,负采样的原理,还有哪些优化方法 2. 贝叶斯调优,机器学习中有哪些优化参数的方法,为什么交叉熵会作为softmax结果的损失函数?梯度下降为什么有效,关于损失求一阶导数为什么有效?刚你提到了泰勒一阶展开,泰勒二阶展开有哪些相关的优化方法呢? 3. SGD的原理,
-
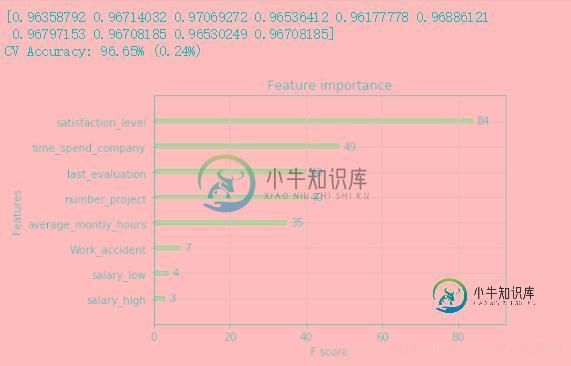 python机器学习库xgboost的使用
python机器学习库xgboost的使用本文向大家介绍python机器学习库xgboost的使用,包括了python机器学习库xgboost的使用的使用技巧和注意事项,需要的朋友参考一下 1.数据读取 利用原生xgboost库读取libsvm数据 使用sklearn读取libsvm数据 使用pandas读取完数据后在转化为标准形式 2.模型训练过程 1.未调参基线模型 使用xgboost原生库进行训练 使用XGBClassifier进行
-
 机器学习图像特征提取
机器学习图像特征提取在机器学习中,灰度图像的特征提取是一个难题。 我有一个灰色的图像,是用这个从彩色图像转换而来的。 我实际上需要从这张灰色图片中提取特征,因为下一部分将训练一个具有该特征的模型,以预测图像的彩色形式。 我们不能使用任何深度学习库 有一些方法,如快速筛选球。。。但我真的不知道如何才能为我的目标提取特征。 以上代码的输出就是真的。 有什么解决方案或想法吗?我该怎么办?
-
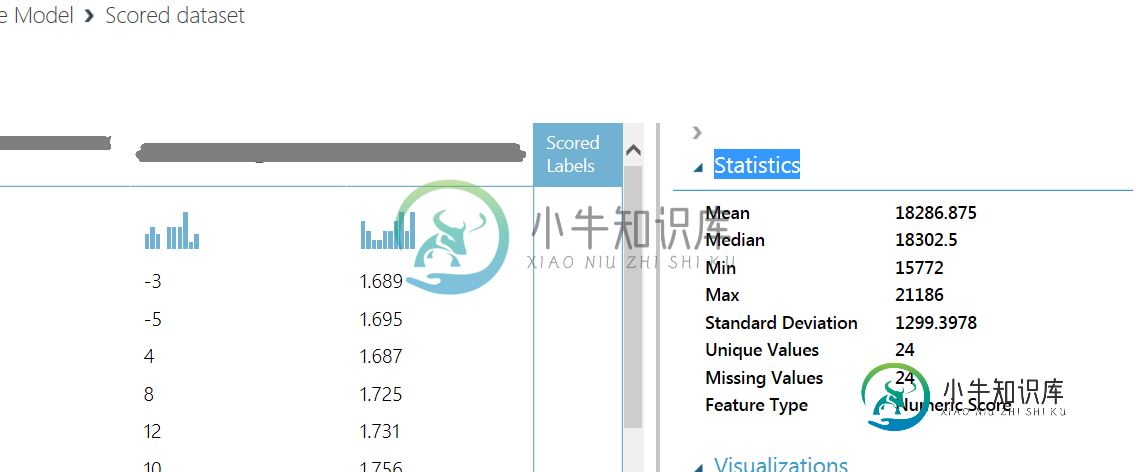 Azure机器学习-空分数结果
Azure机器学习-空分数结果我训练了一个模型,在测试集上的测试结果是可以的。现在,我已经将模型保存为“训练模型”,并将一个新的实验转化为一个新的数据集,以便在我没有实际值的情况下进行预测。 通常,训练过的模型给我一个每个实例的评分标签结果。但是现在,打分的标签结果是空的。另外,当我将得分结果转换为CSV时,得分标签列是空的。 更奇怪的是,当我查看score Visualize选项卡的统计数据时,我确实看到了得分值的统计数据。
-
第十八章 机器学习入门
入门文章 一文读懂机器学习,大数据/自然语言处理/算法全有了
-
8. 大数据与机器学习 - Tensorflow
Kubeflow 是 Google 发布的用于在 Kubernetes 集群中部署和管理 tensorflow 任务的框架。主要功能包括 用于管理 Jupyter 的 JupyterHub 服务 用于管理训练任务的 Tensorflow Training Controller 用于模型服务的 TF Serving 容器 部署 部署之前需要确保 一套部署好的 Kubernetes 集群或者 Mini
-
8. 大数据与机器学习 - Spark
Kubernetes 从 v1.8 开始支持原生的Apache Spark应用(需要Spark支持Kubernetes,比如v2.2.0-kubernetes-0.4.0),可以通过 spark-submit 命令直接提交Kubernetes任务。比如计算圆周率 bin/spark-submit --deploy-mode cluster --class org.apache.spark.
-
使用 scikit-learn 介绍机器学习
校验者: @小瑶 翻译者: @李昊伟 校验者: @hlxstc @BWM-蜜蜂 @小瑶 翻译者: @... 内容提要 在本节中,我们介绍一些在使用 scikit-learn 过程中用到的 机器学习 词汇,并且给出一些例子阐释它们。 机器学习:问题设置 一般来说,一个学习问题通常会考虑一系列 n 个 样本 数据,然后尝试预测未知数据的属性。 如果每个样本是 多个属性的数据 (比如说是一个多维记录),
-
6 最好的机器学习资源
用于制定人工智能、机器学习和深度学习课程表的资源概览。 制定课程表的一般建议 上学获得一个正式学位并不总是可行或者令人满意的。对于那些考虑自学来代替的人,这就是写给你们的。 1. 构建基础,之后专攻兴趣领域 你不能深入每个机器学习话题。有太多药学的东西,并且领域的进展较快。掌握基础概念,之后专注特定兴趣领域的项目 -- 无论是自然语言理解,计算机视觉,深度强化学习,机器人,还是任何其它东西。 2.
-
1 为什么机器学习重要
简单、纯中文的解释,辅以数学、代码和真实世界的示例 谁应该阅读它 想尽快赶上机器学习潮流的技术人员 想要入门机器学习,并愿意了解技术概念的非技术人员 好奇机器如何思考的任何人 本指南旨在让任何人访问。将讨论概率,统计学,程序设计,线性代数和微积分的基本概念,但从本系列中学到东西,不需要事先了解它们。 为什么机器学习重要 人工智能将比本世纪的任何其他创新,更有力地塑造我们的未来。 任何一个不了解它的