《机器学习面试》专题
-
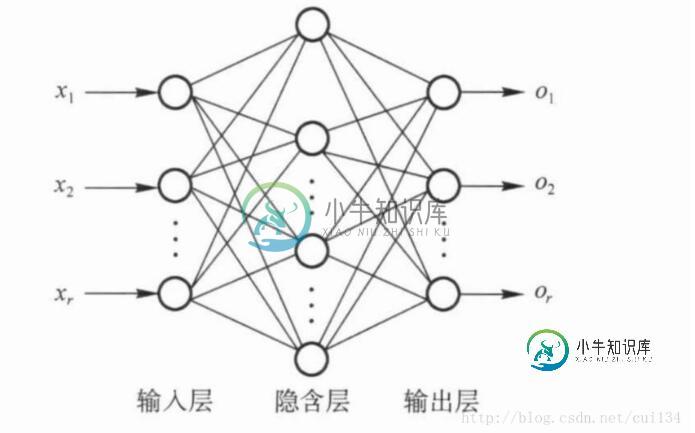 python机器学习之神经网络(二)
python机器学习之神经网络(二)本文向大家介绍python机器学习之神经网络(二),包括了python机器学习之神经网络(二)的使用技巧和注意事项,需要的朋友参考一下 由于Rosenblatt感知器的局限性,对于非线性分类的效果不理想。为了对线性分类无法区分的数据进行分类,需要构建多层感知器结构对数据进行分类,多层感知器结构如下: 该网络由输入层,隐藏层,和输出层构成,能表示种类繁多的非线性曲面,每一个隐藏层都有一个激活函数,将
-
机器学习:使用 NVIDIA JetsonTX2 - 安装TensorFlow
安装 TensorFlow 安装依赖套件 $ sudo apt-get install default-jdk libcupti-dev $ export JAVA_HOME='/usr/lib/jvm/java-8-openjdk-arm64/' 取得 TensorFlow 编译脚本 $ git clone git://github.com/jetsonhacks/installTenso
-
机器学习:使用 NVIDIA JetsonTX2 - 安装OpenCV
安装 OpenCV 既然 TX2 上面有相机模组,那我们就来装个 OpenCV 来做相机的影像处理吧! Python3 会是我们的主要语言。 安装依赖套件 $ sudo apt-get install build-essential cmake git pkg-config libjpeg8-dev libtiff5-dev libjasper-dev libpng12-dev libavcod
-
Scikits机器学习中的价值缺失
问题内容: scikit-learn中是否可能缺少值?应该如何代表他们?我找不到关于此的任何文档。 问题答案: scikit-learn不支持缺少值。 以前在邮件列表上已经对此进行了讨论,但是没有尝试实际编写代码来处理它们。 无论您做什么, 都不要 使用NaN编码缺失值,因为许多算法都拒绝处理包含NaN的样本。 上面的答案已经过时;最新版本的scikit-learn具有一个类,该类可以进行简单的针
-
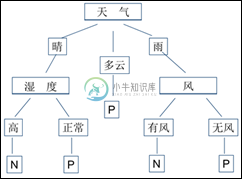 Python机器学习之决策树算法
Python机器学习之决策树算法本文向大家介绍Python机器学习之决策树算法,包括了Python机器学习之决策树算法的使用技巧和注意事项,需要的朋友参考一下 一、决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构。 决策树的根结点是所有样本中信息量最大的属性。树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性。决策树的叶结点是样本的类别值。决策树是一种知识表示形式,它是对所有样本数据的高度概括
-
Azure机器学习指定输入大小
我刚开始使用Azure ML,我正试图找出如何为模型指定输入大小。具体地说,我有一个很大的数据训练集,但我想一次只输入250条记录到PCA算法中。似乎我所能做的就是将整个数据集连接到PCA模块中。 我知道如何为X验证划分数据,但我希望一个分区(比如10000条记录)每次只向模型提供250条记录。
-
机器学习:贝叶斯、KNN、决策树
贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。 先验概率:根据以往经验和分析得到的概率。我们用 \small P(Y) 来代表在没有训练数据前假设\small Y拥有的初始概率。 后验概率:根据已经发生的事件来分析得到的概率。以 \small P(Y|X) 代表假设\small X 成立的情下观察到 \small Y数据的概率,因为它反映了在看到训练数据\small X后\small Y成立的置信度。
-
二、端到端的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目。下面是主要步骤: 项目概述。 获取数据。 发现并可视化数据,发现规律。 为机器学习算法准备数据。 选择模型,进行训练。 微调模型。 给出解决方案。 部署、监控、维护系统。 使用真实数据 学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找的数据的
-
 Sklearn 与 TensorFlow 机器学习实用指南
Sklearn 与 TensorFlow 机器学习实用指南2006 年,Geoffrey Hinton等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。
-
 快手机器学习工程师凉经
快手机器学习工程师凉经1.自我介绍 2.项目深挖 3.数理统计,如何用更少的试管
-
 东软,研究员(机器学习方向)
东软,研究员(机器学习方向)9.2 东软一面(共 23 min) 主要问项目相关,因网络不佳而中断?后直接发offer,但逼签 自我介绍,项目介绍 简历闲聊 除了c++还会啥 SQL会吗 项目深挖 一句话总结项目在做什么? 实例分割模型有哪些,你用了那些? 污水项目实例分割的评价标准 c++项目为啥不用深度学习做? 网络不佳中断,未反问,说后续会有HR联系 三分钟后,HR微信问期望薪资,然后邮箱发了网申笔试,已进入流程,最后
-
 美团机器学习数据挖掘oc
美团机器学习数据挖掘oc感谢团子解救,笔试面试实在太累了,暑期就到此为止吧
-
 《机器学习高频面试题详解》1.3:L1和L2正则化
《机器学习高频面试题详解》1.3:L1和L2正则化前言 大家好,我是鬼仔,今天带来《机器学习高频面试题详解》专栏的第1.3节:L1和L2正则化。这是鬼仔第一次开设专栏,每篇文章鬼仔都会用心认真编写,希望能将每个知识点讲透、讲深,帮助同学们系统性地学习和掌握机器学习中的基础知识,希望大家能多多支持鬼仔的专栏~ 目前这篇是试读,后续的文章需要订阅才能查看哦(每周一更/两更),专栏预计更新30篇文章(只增不减),具体内容可以看专栏介绍,大家的支持是鬼仔
-
 23秋招 顺丰科技机器学习工程师 面经
23秋招 顺丰科技机器学习工程师 面经9.6一面 (30min) 面试官先说流程,一共考察两部分:一,简历上的项目提问+基础知识;二,个人综合素质与沟通交流能力。感觉更注重模型和特征的解释方面,说是因为要经常跟学统计的人打交道和合作。 自我介绍 项目提问,并穿插着问基础,比如讲一下特征选择的方法,特征重要性等等 问懂数理统计吗?讲一下假设检验的流程。特征选择的卡方检验。 碰到给客户解释不清的东西,或者他听不懂,怎么解决? IT领域裁员
-
 23春招 顺丰科技 机器学习工程师 面经
23春招 顺丰科技 机器学习工程师 面经一面: 自我介绍 说一下卡方检验 树的剪枝 GBDT 随机过程 ADASYN(我简历里面写了这个所以才问的) SVM常用核函数 问项目 反问 二面: 自我介绍 GBDT(问的巨细,包括为什么可以用负梯度拟合残差、如果换个loss function还可以用负梯度拟合吗) 拉格朗日插值法具体怎么算的(我简历里面写了这个所以才问的) 回归树用什么损失函数(我回答了一堆分类树的,傻杯了哈哈哈哈) 用三个词