《数据分析这么卷的吗?》专题
-
组卷
组卷模板 什么是组卷模板,如何组卷? 组卷模板可以实现自动从题库中抽取试题,组成试卷的任务。组卷模板跟试卷类似,但是不包含任何实际的试题,而是包含一组规则,定义了如何从题库中抽取试题。 使用组卷模板的前提是题库已经建立好,并且需要在题库里有足够可供选择的试题,题库里的试题越多,使用组卷形成的试卷的试题重复率就越低。 组卷的步骤和应用:首先需要创建组卷模版,编辑好模版结构,并添加好抽卷规则。 通过模
-
试卷
题型 易考支持的题型: 判断题 单选题 多选题 复合题(即综合分析题) 简答题 填空题 录音题 拖拽题 完形填空题 注:所有类型的试题均支持上传音频和图片。 其中简答、填空和录音题需要人工判分;判断、单选和多选题必须设置正确答案; 复合题增加下设小题请点击“+新增子试题”并选择需要的题型。 各种题型展示 试卷结构 一份普通试卷可包含多个单元,编辑试卷可编辑考生须知、添加单元、导入单元; 试卷限时
-
问卷
讲师可发布问卷,考察学员的学习情况。题干内容与选项均包含在问卷中。 讲师端 说明: 1)支持讲师新建问卷以及发布第三方问卷,第三方问卷需输入问卷地址链接 2)点击新建问卷,出现问卷配置页面,讲师可输入问卷标题、添加所需要的题型及内容、分数等功能 3)问卷创建后可进行发布、编辑、删除、预览等操作;可创建多个问卷,问卷可提前创建,在直播中随时发布 4)终止答题后讲师可查看学员的答题统计,其中问答题统计
-
mysql - 下面这个场景我该使用什么数据存储方案?
我做的是一个线上视频培训服务,每10s就要记录一次学员的已观看时长,一般一个学员需要参加一套120课时的课程,每个课时45分钟,可以计算出理想状况每个学员产生的记录都超过3w+。而计划的学员数量在三年内会到10w,这个数据量比较大了,用mysql存储感觉不是很适合。存储的数据在监管单位要求调学员数据的时候可以导出学习的明细,也就是记录的数据。 这种业务场景应该用哪个数据存储方案?
-
JS数组返回去重后数据的方法解析
本文向大家介绍JS数组返回去重后数据的方法解析,包括了JS数组返回去重后数据的方法解析的使用技巧和注意事项,需要的朋友参考一下 话不多说,请看代码: 以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持呐喊教程!
-
超详细背包DP九讲(算法分析+问题分析+代码分析)
P01: 01背包问题 题目:有N件物品和一个容量为V的背包。第i件物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使这些物品的费用总和不超过背包容量,且价值总和最大。 基本思路:这是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。 用子问题定义状态:即f[i][v]表示前i件物品恰放入一个容量为v的背包可以获得的最大价值。则其状态转移方程便是:f[i][v]=max{
-
javascript - 这个前端代码是这么理解吗?
const dataItem = (msg.data && msg.data[0]) || msg; 如果msg.data和msg.data[0]都为真时返回msg.data[0],否则返回msg?
-
 mysql数据库常见基本操作实例分析【创建、查看、修改及删除数据库】
mysql数据库常见基本操作实例分析【创建、查看、修改及删除数据库】本文向大家介绍mysql数据库常见基本操作实例分析【创建、查看、修改及删除数据库】,包括了mysql数据库常见基本操作实例分析【创建、查看、修改及删除数据库】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了mysql数据库常见基本操作。分享给大家供大家参考,具体如下: 创建数据库 查看数据库 修改数据库 删除数据库 首发时间:2018-02-13 20:47 修改: 2018-04-07:
-
如何实现这个数据库结构?
我想创建一个食谱网站,在那里你可以添加/修改/删除食谱,每个模型都应该有一个配料的列表,与所需的量的那个配料。 我试图使用这样的dict:,但结果是EF Core并不真正喜欢dicts的思想,所以我试图创建一个“映射器”模型,如下所示: 问题是,它仍然没有真正起作用。我不能添加菜谱,也不能删除,因为它进入了一个永远循环。 你将如何实施它? 谢谢
-
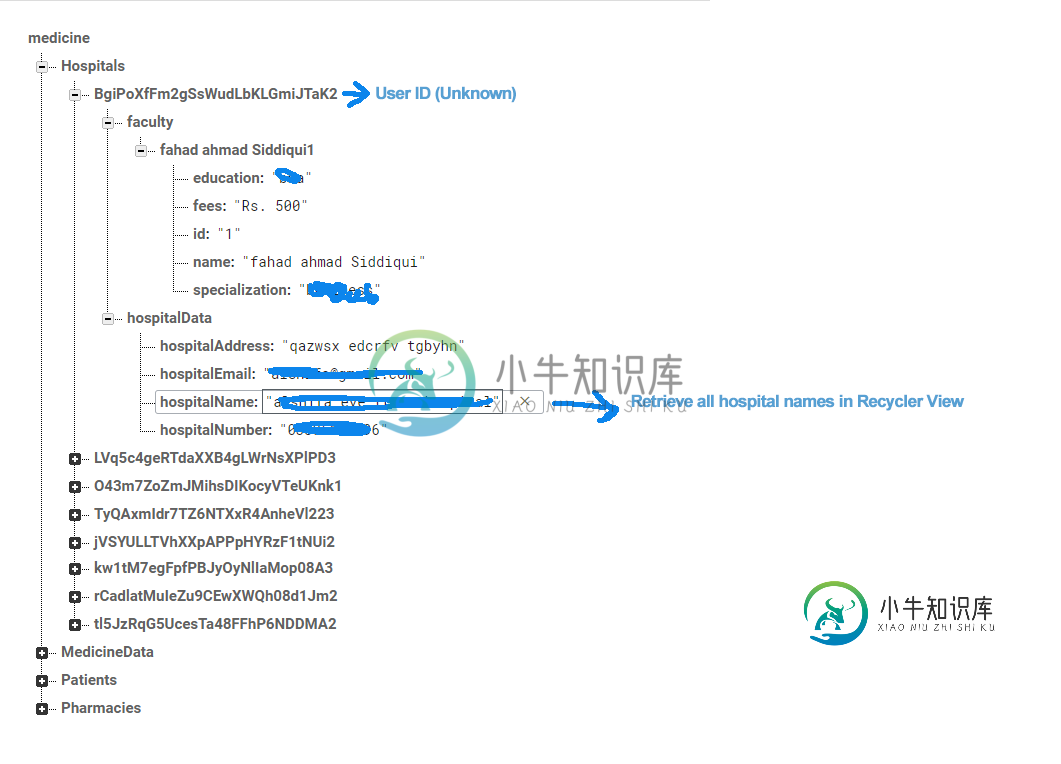 如何从Firebase中检索这些数据?
如何从Firebase中检索这些数据?我如何从所有userid都未知的医院中检索所有的hospitalNames。
-
缺失值的分类数据中的降维
问题内容: 我有一个回归模型,其中因变量是连续的,但是90%的自变量是分类的(有序和无序),大约30%的记录具有缺失值(更糟糕的是,它们无规律地随机缺失,也就是说,超过百分之四十五的数据至少有一个缺失值)。没有先验理论来选择模型的规格,因此关键任务之一是在运行回归之前进行尺寸缩减。虽然我知道用于连续变量降维的几种方法,但我不知道关于分类数据的类似静态文献(也许,除了作为对应分析的一部分,这基本上是
-
Spring项目的数据库访问所使用的这些依赖关系到底是什么?
在Spring MVC项目的pom.xml文件中,我发现了添加到我的项目(使用JPA实现我的存储库)的以下依赖项。 所以我试图理解这个项目的体系结构,以及这些依赖关系到底是什么。 因此,据我所知,JPA只是一个规范,如果没有实现,我就无法使用它。那么JPA是不是像一组指定我可以执行什么操作的接口,然后我需要一些实现该操作的东西? 1)因此,根据我的理解,第一个工件(hibernate-jpa-2.
-
我应该如何分析和或证明这个简单的排序算法?
-
卷积神经网络中的过拟合问题及卷积层参数的确定
我应用批量标准化技术来提高我的cnn模型的准确性。没有批量归一化的模型精度仅为46%,但应用批量归一化后,精度超过了83%,但这里出现了一个bif过拟合问题,模型给出的验证精度仅为15%。也请告诉我如何决定没有过滤器的步幅在卷积层和没有单位在登斯层
-
mysql分表和分区的区别浅析
本文向大家介绍mysql分表和分区的区别浅析,包括了mysql分表和分区的区别浅析的使用技巧和注意事项,需要的朋友参考一下 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈。需要进行数据的处理,采用的手段是分区、分片、分库、分表。 一、什么是mysql分表和分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表 什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在同