《数据分析这么卷的吗?》专题
-
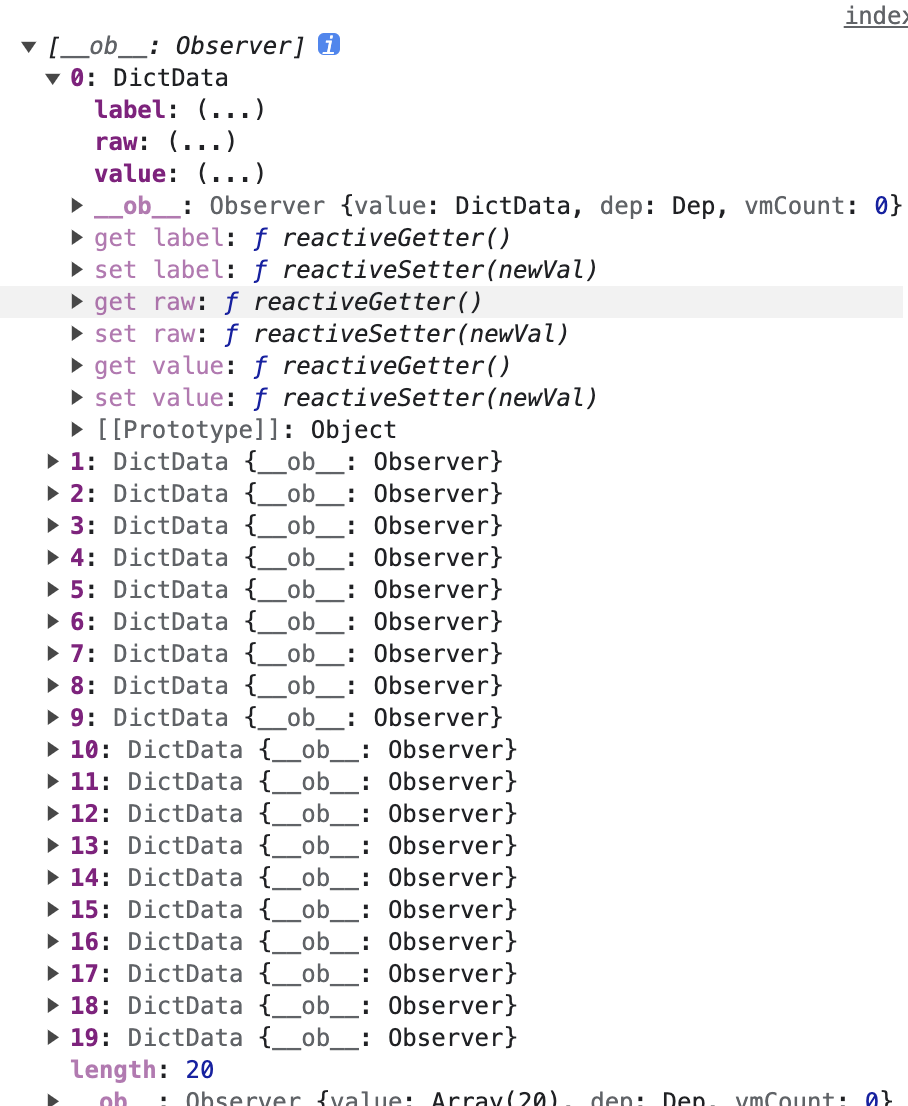 前端 - 这个数据无法使用map遍历吗?
前端 - 这个数据无法使用map遍历吗?定义的dacaData类 字典
-
为什么Kafka Consumer API不从主题的多个分区获取数据
注:使用kafka_2.11-0.9.0.1 我创建了一个Kafka主题,名为:
-
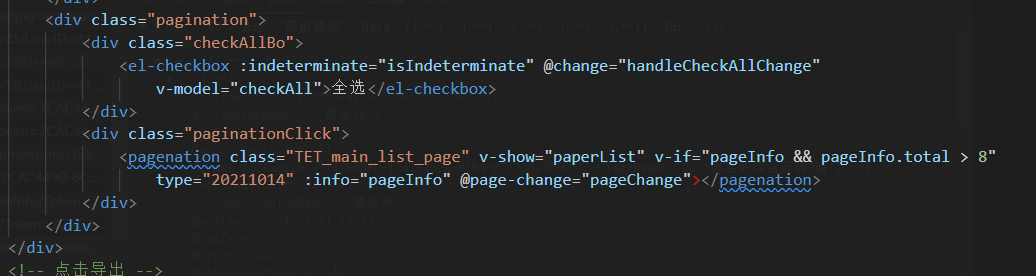 javascript - vue中对于后端已经分页好的数据怎么全选?
javascript - vue中对于后端已经分页好的数据怎么全选?vue中对于后端已经分页好的数据怎么全选?每次通过vue2的分页组件切换页码都会请求到八条数据,在请求完成之后对每条数据增加一个属性checked=false,点击页面上的全选按钮会将这些数据的checked赋值为true,那么这些数据就被选中,但是只要切换页码,又会重新请求接口。怎么样才能对所有的数据进行全选? 上面是全选按钮和分页组件
-
node.js - 请问 nestjs 有类似 mycat 的分布式数据库中间件么?
请问 nodejs 中有 类似mycat 或 sharingjdbc的分布式数据库中间件么
-
将数据帧分解为新的子集/组数据帧。从其他数据框创建包含数据子集/组的新数据框
问题内容: 我有一个如下所示的pandas数据框,并通过一列保存数据组: 现在,我想创建新的数据框(名为df_w,df_x,df_y,df_z),这些数据框仅保存其原始数据中的数据,并在一些可迭代的列表(例如列表)中进行最佳组合: 有没有使用groupby,apply和/或applymap和函数来实现此目的的智能(矢量化熊猫)方法? 我当时正在考虑对数据框进行迭代,但这似乎不是很优雅。 预先感谢您
-
JS解析XML实例分析
本文向大家介绍JS解析XML实例分析,包括了JS解析XML实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS解析XML的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的javascript程序设计有所帮助。
-
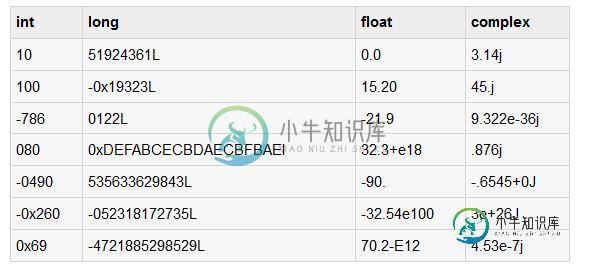 详细解析Python中的变量的数据类型
详细解析Python中的变量的数据类型本文向大家介绍详细解析Python中的变量的数据类型,包括了详细解析Python中的变量的数据类型的使用技巧和注意事项,需要的朋友参考一下 变量是只不过保留的内存位置用来存储值。这意味着,当创建一个变量,那么它在内存中保留一些空间。 根据一个变量的数据类型,解释器分配内存,并决定如何可以被存储在所保留的内存中。因此,通过分配不同的数据类型的变量,你可以存储整数,小数或字符在这些变量中。 变量赋值
-
使用新的Java8DateTimeFormatter进行严格的数据解析
我有一个简单的问题:我希望严格地以的格式解析Java字符串,以便是有效日期,而不是。假设这些是正常公历的广告日期。 我试图使用JDK8中新的包来解决这个问题,但事实证明它比希望的要复杂。我当前的代码是: 如何使用来解决我的简单用例?
-
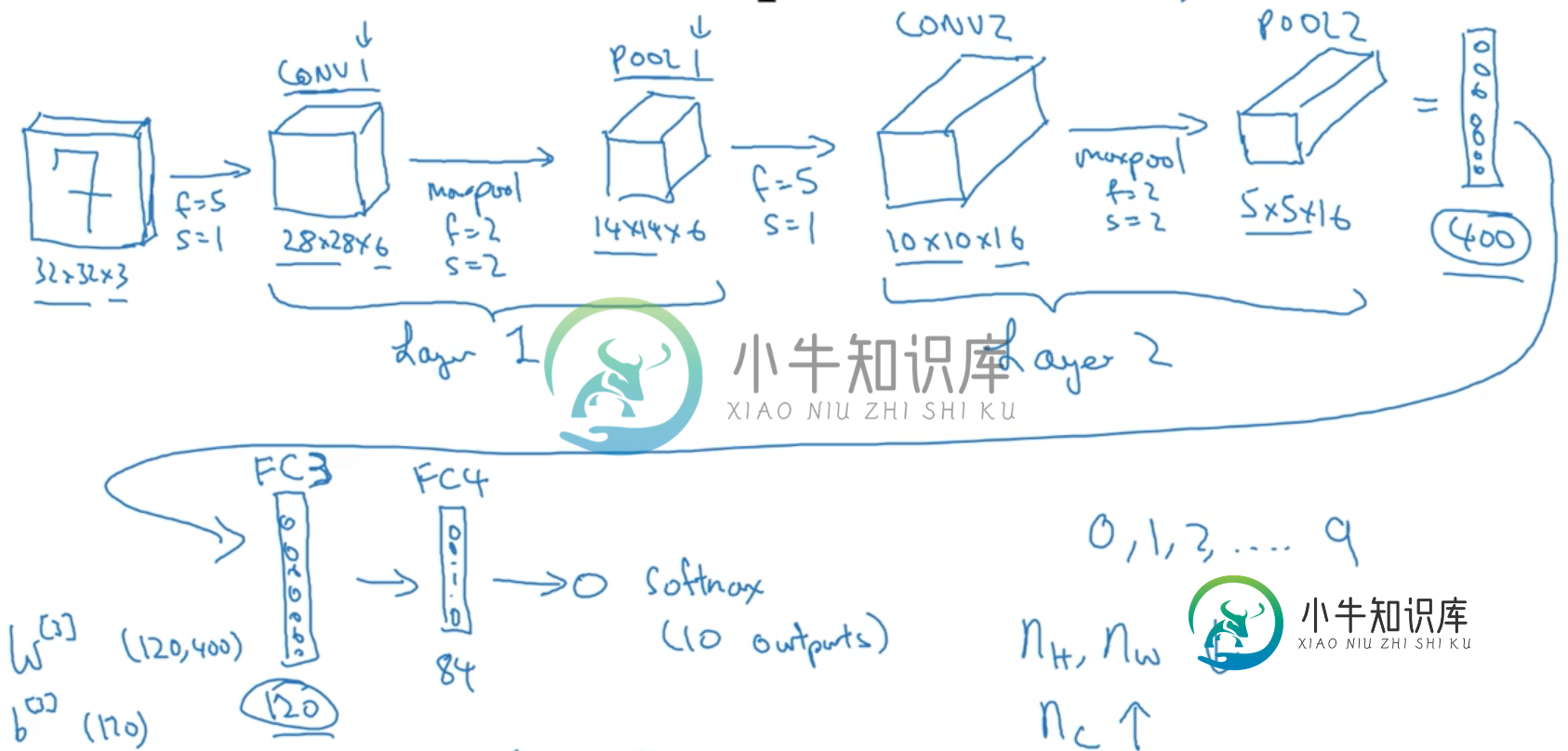 卷积神经网络中参数个数的计算
卷积神经网络中参数个数的计算我是CNN研究的新手,我从看Andrew'NG的课程开始。有一个例子我不明白: 他是如何计算#参数值的?
-
Kafka中的数据日志是什么?
本文向大家介绍Kafka中的数据日志是什么?相关面试题,主要包含被问及Kafka中的数据日志是什么?时的应答技巧和注意事项,需要的朋友参考一下 答:我们知道,在Kafka中,消息会保留相当长的时间。此外,消费者还可以根据自己的方便进行阅读。尽管如此,有一种可能的情况是,如果将Kafka配置为将消息保留24小时,并且消费者可能停机超过24小时,则消费者可能会丢失这些消息。但是,我们仍然可以从上次已知
-
怎么监听vuex数据的变化?
本文向大家介绍怎么监听vuex数据的变化?相关面试题,主要包含被问及怎么监听vuex数据的变化?时的应答技巧和注意事项,需要的朋友参考一下
-
数据库中的文件Snapshot.scala什么?
我正在数据库集群上运行一些流查询作业,当我查看集群/作业日志时,我看到很多 首先在Snapshot.scala:1 和 TransactionalWriteEdge.scala:130处的NewExecutionId 快速搜索得到了这个scala脚本https://github.com/delta-io/delta/blob/master/src/main/scala/org/apache/spa
-
为什么REGISTER_GLOBALS这么糟糕?
问题内容: 我不是PHP开发人员,但我在很多地方都看到人们似乎把它当作瘟疫之类。为什么? 问题答案: 表示通过GET或POST传递的所有变量都可以作为脚本中的全局变量使用。由于访问未声明的变量不是PHP中的错误(这是警告),因此可能导致非常讨厌的情况。考虑一下,例如: 这本身不是一件坏事(精心设计的代码不应生成警告,因此不应访问可能未声明的变量(并且出于相同原因也不 需要 )),但是PHP代码通常
-
Python:为什么IDLE这么慢?
问题内容: IDLE是我最喜欢的Python编辑器。它提供了非常漂亮和直观的Python shell,它对单元测试和调试非常有用,并且还提供了一个简洁的调试器。 但是,在IDLE下执行的代码异常缓慢。 疯狂是指慢 三个数量级 : 重击 需要0.052秒, 闲 需要: 大约慢了2000倍。 有什么想法或想法可以改善这一点吗?我想这与后台调试器有关,但是我不确定。 亚当 问题答案: 问题是文本输出而不
-
phpMyAdmin中的MySQL分析错误(``他的子句类型先前已分析'')
问题内容: 我有以下SQL查询: 它在phpMyAdmin中工作正常。但那里有一个警告说: “此类型的子句先前已解析(在select附近)”。 你能猜出是什么问题吗?该查询可以执行并返回预期结果。 问题答案: 这似乎是phpMyAdmin分析器错误,请参阅github上的问题,查询本身有效。