《数据分析这么卷的吗?》专题
-
 京东数据分析面试3|秋招两面社交电商部
京东数据分析面试3|秋招两面社交电商部京东社交电商APP+小程序京喜,对标拼多多。 一面 1. 自我介绍+项目与实习提问。 2. 你学的这个专业,你认为对你影响最大的是什么? 3. 最大的成长或收获是什么呢?为什么?举个最近实际的例子? 4. 详细问是例子中是怎么想、怎么做、怎么实现的? 5. 运用数据分析,分析一下酒店的漏水情况?(和面试官一来一往提出假设,具化问题,分析讨论) 6. 你SQL怎么样? 7. 你有什么问题? 二面 1
-
jqgrid中带有数组数据的分页问题
问题内容: 我在具有18条记录的数组数据的jqgrid中遇到分页问题,但是即使我指定了pagination:true,pager:jQuery(’#pager1’),记录也不会显示在页面中。您能帮我实现分页而不是滚动吗? 问题答案: 您的主要问题是添加大量行后应重置。线 在代码末尾将解决此问题。我建议您添加行 直接在定义jqGrid之后。然后,您不仅将具有数据分页,还具有数据过滤(搜索)和刷新
-
获取一个数据frame的当前分区数
是否有任何方法可以获得一个DataFrame的当前分区数?我检查了DataFrame javadoc(spark 1.6)但没有找到一个方法,或者我只是错过了它?(对于JavaRDD,有一个getNumPartitions()方法。)
-
转换后保留Spark数据帧的分区数
我正在查看代码中的一个错误,其中一个数据框被分成了太多的分区(超过700个),当我试图将它们重新分区为48个时,这会导致太多的洗牌操作。我不能在这里使用coalesce(),因为我想在重新分区之前首先拥有更少的分区。 我正在寻找减少分区数量的方法。假设我有一个 spark 数据帧(具有多个列),分为 10 个分区。我需要根据其中一列进行 orderBy 转换。完成此操作后,生成的数据帧是否具有相同
-
无分页计数的Spring数据存储库QueryDslPredicateExecutor
我试图创建一个spring数据存储库,它使用一个方法列出一页实体和一个QueryDSL谓词,使用以下内容: 正如这里提到的禁用从PageRequest获取总页数的计数查询的方法,我尝试使用“技巧”用“FindAllby”命名方法。 如何在不发出count查询的情况下使用Pageable创建QueryDSL存储库?在最后一页之后执行额外的查询以获取下一页,而不是对每个页面请求发出额外的计数查询,这样
-
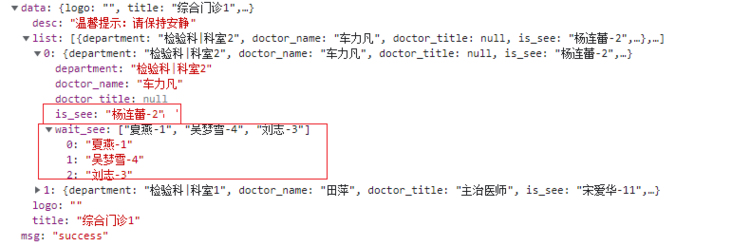 javascript - 怎么把后端返回的数据名字和数字分开,并分别渲染到页面上?
javascript - 怎么把后端返回的数据名字和数字分开,并分别渲染到页面上?这个是后端返回的数据,想把is_see和wait_see数据里面的名字和数字分开,然后分别把名字和数字渲染到页面上 这个是dom做遍历渲染 请问这个问题该怎么去弄呢?
-
这是什么:[Ljava.lang.Object ;?
问题内容: 当我调用toString从函数调用中收到的对象时,会得到此信息。我知道对象的类型编码在此字符串中,但是我不知道如何读取它。 这种编码称为什么类型? 问题答案: ;是的名称代表的数组的类。 命名方案记录在: 如果该类对象表示的引用类型不是数组类型,则返回该类的二进制名称,如Java语言规范(§13.1)所指定。 如果此类对象表示原始类型或void,则返回的名称是与原始类型或对应的Java
-
python 函数的缺省参数使用注意事项分析
本文向大家介绍python 函数的缺省参数使用注意事项分析,包括了python 函数的缺省参数使用注意事项分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python 函数的缺省参数使用注意事项。分享给大家供大家参考,具体如下: python的函数支持4种形式的参数:分别是必选参数、 缺省参数、 可变长参数、关键字参数;而且参数的书写顺序也是又一定规定的,顺序如下 下面针对缺省型参数分
-
为什么这个分支会中断类型推理?
我使用的是Java中的<code>或者</code>的本地实现,它有如下方法: 这两种方法可以编译并正常工作: 此方法不编译: 错误: (我去掉了包限定符,使错误更加易读) 我可以通过指定类型来编译它: 但我为什么需要这样做?我如何避免这种代码混乱?
-
这个奇数排序算法是什么?
有些答案最初有这样的排序算法: 请注意,和都是全范围的,因此可以比大,也可以比小,所以它可以使成对的顺序正确,也可以使成对的顺序错误(实际上这两种顺序都正确!)。我认为这是一个错误(作者后来称之为错误),这会混淆数组,但它看起来排序正确。不过,原因并不明显。但是代码的简单性(范围很广,没有像冒泡排序那样的)使它变得有趣。 正确吗?如果是这样,它为什么起作用?它有名字吗? 带测试的Python实现:
-
1.3.4.3 行为分析分群
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData
-
1.5.3.2.13.3 选址分区分析
选址分区分析是为了确定一个或多个待建设施的最佳或最优位置,使得设施可以用一种最经济有效的方式为需求方提供服务或者商品。选址分区不仅仅是一个选址过程,还要将需求点的需求分配到相应的新建设施的服务区中,因此称之为选址与分区。 设置选址分区分析参数,包括交通网络分析通用参数、途径站点等。 //设置设施点的资源供给中心 var supplyCenterType_FIXEDCENTER = SuperMap
-
使用分配分析器
使用分配分析器工具来查找未被正确地垃圾收回收,并继续保留在内存中的对象。 分配分析器如何工作 allocation profiler(分配分析器)结合了堆分析器中快照的详细信息以及Timeline(时间轴)面板的增量更新以及追踪信息。与这些工具相似,追踪对象堆的分配过程包括开始记录,执行一系列操作,以及停止记录并分析。 分配分析器在记录中周期性生成快照(频率为每50毫秒),并且在记录最后停止时也会
-
怎么保证缓存和数据库数据的一致性?
1、淘汰缓存 数据如果为较为复杂的数据时,进行缓存的更新操作就会变得异常复杂,因此一般推荐选择淘汰缓存,而不是更新缓存。 2、选择先淘汰缓存,再更新数据库 假如先更新数据库,再淘汰缓存,如果淘汰缓存失败,那么后面的请求都会得到脏数据,直至缓存过期。 假如先淘汰缓存再更新数据库,如果更新数据库失败,只会产生一次缓存穿透,相比较而言,后者对业务则没有本质上的影响。 3、延时双删策略 如下场景:同时有一
-
卷积
图像的卷积(Convolution)定义为 $$f(x) = act(\sum{i, j}^n \theta{(n - i)(n - j)} x_{ij}+b)$$ 其计算过程为 示例1 import tensorflow as tf import numpy as np sess = tf.InteractiveSession() input_batch = tf.constant([