《数据分析这么卷的吗?》专题
-
解析http多部分/表单数据移交值接收的JSON文件(Java Springboot)
总结 上传服务接收包含JSON(MediaType.APPLICATION_JSON_VALUE)的超文本传输协议multipart/form数据流 JSON值需要作为参数传递给构造函数 当前情况:我将从REST API接收http多部分/表单数据,该API通过接口包含JSON文件(MediaType.APPLICATION\u JSON\u值) 让我们假设发布的多部分文件如下所示(尚不知道确切内
-
分析数据组织时出错。json。JSONException:在的字符0处输入结束
我正在尝试登录应用程序,但我一直遇到“解析数据org.json.JSONException错误:在字符0的输入结束” 我的登录名。java看起来像这样 公共类登录扩展活动实现OnClickListener{私有EditText用户,pass; 私有静态最终字符串LOGIN_URL="my url"; //从真实服务器进行测试: } } 我的JSONParser。java如下所示:` 公共类JSON
-
使用Python解析数据以创建json数据对象
问题内容: 这是我从Google bigquery解析的数据: 作为Python新手,我真的不知道如何解析该数据以创建一个json对象,如下所示: 任何人都可以给我一些入门的提示吗? 例 在这个单词中,是995和1600。因此也是如此。 问题答案: 如果“ Z”是您的大词典,则在“响应”上您将获得所需的结构。 响应后,您将获得以下信息: 我相信它是您所需要的。比仅使用json对响应做一个就可以了。
-
无法解析组织。springframework。数据:Spring数据键值:2.7.0
项目xmlns="http://maven.apache.org/POM/4.0.0"xmlns: xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:模式位置="http://maven.apache.org/POM/4.0.0https://maven.apache.org/xsd/maven-4.0.0.xsd" 在此处输入图像描述
-
Mongo分片不删除源分片中分片集合的数据
我在5台机器上安装了MongoDB 3.2.6,这些机器都形成了由2个碎片组成的碎片集群(每个碎片都是具有主次仲裁器配置的副本集)。 我还有一个数据库,其中包含非常大的集合(约50M记录,200GB),它是通过mongos导入的,mongos将其与其他集合一起放入主分片。 我在该集合上生成了散列ID,这将是我的分片密钥。 在thay之后,我用: 命令返回: 它开始碎裂。碎片的状态如下所示: 这一切
-
Python-将数据框拆分为多个数据框
问题内容: 我有一个非常大的数据框(大约一百万行),其中包含来自实验的数据(60位受访者)。我想将数据框分成60个数据框(每个参与者一个数据框)。 在数据帧(称为=数据)中,有一个名为“名称”的变量,它是每个参与者的唯一代码。 我已经尝试了以下方法,但是没有任何反应(或者一小时内没有停止)。我打算做的是将数据帧(数据)拆分为较小的数据帧,并将其附加到列表(数据列表)中: 我没有收到错误消息,脚本似
-
为什么数组中的这段代码不合适?
我正在尝试插入: 在: 但我不工作... 我试过: 为什么??
-
浅析JS中什么是自定义react数据验证组件
本文向大家介绍浅析JS中什么是自定义react数据验证组件,包括了浅析JS中什么是自定义react数据验证组件的使用技巧和注意事项,需要的朋友参考一下 我们在做前端表单提交时,经常会遇到要对表单中的数据进行校验的问题。如果用户提交的数据不合法,例如格式不正确、非数字类型、超过最大长度、是否必填项、最大值和最小值等等,我们需要在相应的地方给出提示信息。如果用户修正了数据,我们还要将提示信息隐藏起来。
-
在Apple Swift中解析Excel数据
问题内容: 我当前的工作流程涉及使用Applescript本质上界定Excel数据并将其格式化为纯文本文件。我们正在向全Swift环境推进,但是我还没有找到任何将我的Excel数据解析为Swift的工具包。 我唯一想到的就是使用C或其他东西并将其包装,但这并不理想。关于解析此数据以在Swift中使用的任何更好的建议? 目的是消除Applescript,但是我不确定在仍然与Excel文件交互时是否有
-
从JQuery.ajax成功数据解析JSON
问题内容: 我无法从JQery.ajax调用获取JSON对象的内容。我的电话: 似乎正确返回了JSON对象,因为“ alert(data)”显示以下内容 但是当我尝试使用以下方法在页面上显示ID或名称时: 它将“未定义”返回到页面。我究竟做错了什么? 谢谢您的帮助。 问题答案: 数据以JSON的字符串表示形式返回,您无需将其转换回JavaScript对象。将设置为仅使其自动转换。
-
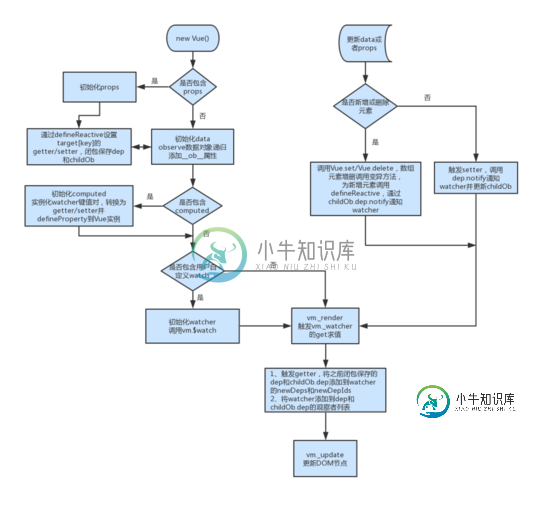 Vue数据绑定简析小结
Vue数据绑定简析小结本文向大家介绍Vue数据绑定简析小结,包括了Vue数据绑定简析小结的使用技巧和注意事项,需要的朋友参考一下 作为MVVM框架的一种,Vue最为人津津乐道的当是数据与视图的绑定,将直接操作DOM节点变为修改 data 数据,利用 Virtual Dom 来 Diff 对比新旧视图,从而实现更新。不仅如此,还可以通过 Vue.prototype.$watch 来监听 data 的变化并执行回调函数,实
-
WebLogic无法解析jndi数据源
我有通过jndi名称从WebLogic获取数据源的应用程序。 我在应用程序中配置了jndi数据源名称。yml: 我在WebLogic服务器上配置了它,指定了特定的目标。我测试了这个数据源,WebLogic说测试成功了。但是当我尝试部署应用程序时,我收到以下错误: 我需要确定WebLogic的数据源配置中存在问题,或者在java代码中获取数据源时存在问题。我是否能够在不部署应用程序的情况下测试获取数
-
将JSON解析为数据结构
我正在尝试将上面的JSON解析为数据结构。我最初使用Gson,但大多数解决方案建议创建一个反映我的Gson结构的类结构并使用fromJson(String, Class),但我不想这样做,因为JSON的结构可能会改变,我不想每次都格式化我的类。
-
Android改造无法解析数据
无法解析以下json数据。获得成功响应但返回的正文为空以下是我通过Web浏览器获得的json响应。 下面是用于解析所用响应类的模型类 Departure.java 调用api 我从浏览器中得到了正确的响应。但当通过改装库调用时,获得成功响应(200),但正文为空。 我从浏览器中得到了正确的响应。但当通过改装库调用时,获得成功响应(200),但正文为空。
-
如何使用REGEXP_SUBSTR解析数据?
问题内容: 我有一个这样的数据集(请参见下文),我尝试提取以下形式的数字:{variable_number_of_digits} {hyphen} {only_one_digit}: 我没有得到正确的结果集,应为以下内容 如何实现呢? 问题答案: 如果要从第二个和第三个定界的组中获取结果,则: 输出 : 更新 : 如果只希望第一个和第二个模式匹配,并且不在乎它们在字符串中的位置,则: 输出 :