《数据分析这么卷的吗?》专题
-
忽略JSON.NET数据解析期间的解析错误
问题内容: 我有一个具有预定义数据结构的对象: 和JSON应该是 我想以肯定的方式处理JSON错误,并且每当服务器为定义的数据类型返回意外的值时,我都希望它被忽略并设置默认值(空)。 现在,当JSON部分无效时,我得到了JSON阅读器异常: 而且我什么都没有。我想要的是获取一个对象: 并分析警告(如果可能)。可以使用JSON.NET完成吗? 问题答案: 为了能够处理反序列化错误,请使用以下代码:
-
用Java解析JSON数据
问题内容: 我想解析此页面上的一些数据:http : //www.bbc.co.uk/radio1/programmes/schedules/england/2013/03/1.json 我想解析的数据是标题,但是我不确定如何提取数据。到目前为止,这是我所做的: } 这只是返回null。有人可以告诉我我需要更改吗?谢谢。 问题答案: 如果您阅读的Javadoc 实际上是,它会指出 返回: 指定键映
-
Python-解析JSON数据集
问题内容: 我正在尝试解析看起来像这样的JSON数据集: 假设可以有许多这样的数据集。 我想遍历它们中的每一个并获取“名称”和“广告系列ID”参数。 到目前为止,我的代码看起来像这样: 可能挺简单的!我对列表/字典不好:( 问题答案: 使用或(提供默认值)访问词典: 我建议你读一些有关字典的东西。
-
用PHP解析JSON数据
问题内容: 我已经多次解析JSON数据,但是由于某种原因,无法找到嵌套数据时要使用的正确语法。我正在尝试从此JSON解析“资产”,但是无论我尝试什么,都继续获取为foreach()提供的无效参数。 我希望这是… 问题答案: 来自php官方文档:http : //php.net/manual/fr/function.json- decode.php 第二个func arg用于assoc数组返回。如果
-
 7.2.2 Android JSON数据解析
7.2.2 Android JSON数据解析主要内容:本节引言:,1.Json概念以及与XML的比较,2.Android给我们提供的Json解析类,3.代码示例:解析Json字符串:,本节小结:本节引言: 相信大家肯定对 Json 不陌生吧,我们和服务器交互一般用得较多的数据传递方式都是 Json 字符串的形式, 保存对象,我们也可以写成一个 Json 字符串然后存储!解析 Json 不知道你用的是 Gson,Fastjson,jackson 等,不过本节我们并不会去用这些第三方的解析库,而是使用 Android 自带的 Json 解析器
-
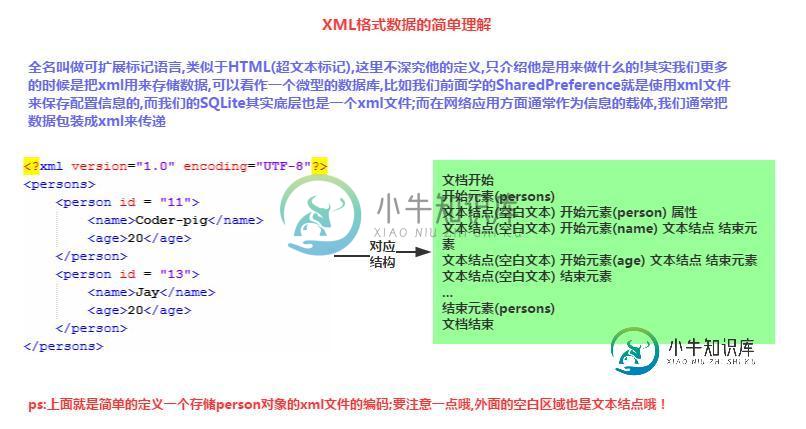 7.2.1 Android XML数据解析
7.2.1 Android XML数据解析主要内容:本节引言:,1.XML数据要点介绍,2.三种解析XML方法的比较,3.SAX解析XML数据,4.DOM解析XML数据,5.PULL解析XML数据,6.代码示例下载:,本节小结:本节引言: 前面两节我们对Android内置的Http请求方式:HttpURLConnection和HttpClient,本来以为OkHttp 已经集成进来了,然后想讲解下Okhttp的基本用法,后来发现还是要导第三方,算了,放到进阶部分 吧,而本节我们来学习下Android为我们提供的三种解析XML数据的方案!
-
PHP函数import_request_variables()用法分析
本文向大家介绍PHP函数import_request_variables()用法分析,包括了PHP函数import_request_variables()用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了PHP函数import_request_variables()用法。分享给大家供大家参考,具体如下: import_request_variables 函数可以在 register_
-
jquery ready函数深入分析
本文向大家介绍jquery ready函数深入分析,包括了jquery ready函数深入分析的使用技巧和注意事项,需要的朋友参考一下 最近看一些关于jquery ready 有人说他缓慢,有人说他快,说法不一。 于是自己深入研究一下。首先看了一下jquery 文档 关于ready 的描述 翻译一下 虽然JavaScript提供了load事件,当页面渲染完成之后会执行这个函数,在所以元素加载完成之
-
用于有效连接Spark数据帧/数据集的分区数据
我需要根据一些共享的键列将许多数据帧连接在一起。对于键值RDD,可以指定一个分区程序,以便具有相同键的数据点被洗牌到相同的执行器,因此连接更有效(如果在之前有与洗牌相关的操作)。可以在火花数据帧或数据集上做同样的事情吗?
-
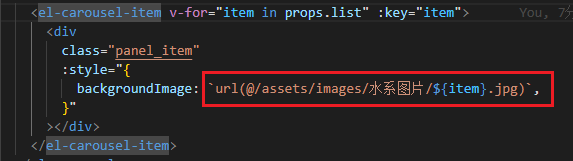 javascript - vite中,这样的路径会解析错误,怎么办?
javascript - vite中,这样的路径会解析错误,怎么办?如何在backgroundImage中使用 路径别名@ 和 变量 呢?
-
海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10?
本文向大家介绍海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10?相关面试题,主要包含被问及海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10?时的应答技巧和注意事项,需要的朋友参考一下 这种就分为两种情况: 情况1: 情况2:
-
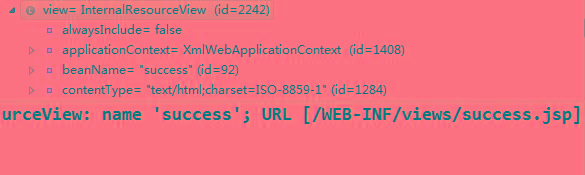 springmvc处理响应数据的解析
springmvc处理响应数据的解析本文向大家介绍springmvc处理响应数据的解析,包括了springmvc处理响应数据的解析的使用技巧和注意事项,需要的朋友参考一下 1. ModelAndView 相关的成员变量和方法 private Object view; 描述视图信息 private ModelMap model 描述模型数据(响应数据) public void setViewName(String viewName)
-
如何解析Node中的数据URL?
问题内容: 我有一个像这样的数据URL: 将其作为二进制数据(例如a )获取以便将其写入文件的最简单方法是什么? 问题答案: 使用“ base64”编码将数据放入缓冲区,然后将其写入文件:
-
flatter与flaskrestapi之间的数据解析
我正在尝试将我的颤振应用程序的请求发布到Flask REST API,使用POST MAN测试API没有问题,但在颤振上,我在颤振中遇到如下错误: I/颤振(6378):格式异常:意外字符(字符1处)I/颤振(6378):I/颤振(6378):^ 在Flask应用程序中,如下所示: [2020-01-23 11:42:32,517]应用程序中的错误:异常 /cards[POST]Traceback
-
java解析来自组件的数据
我正在创建一个游戏,我正在做一个字符选择屏幕,其中有一个JTextField用于输入用户名,屏幕上还有一个JButton“创建字符”,当按下时会解析JTextField,如果有任何问题(名称中的空格,以空格开头等),它会将一些文本放在JTextField旁边的JLabel中。 我将JButton连接到actionPerformed方法,该方法调用解析数据的函数。我的问题是,每次我按下按钮,一个新标