《数据分析这么卷的吗?》专题
-
在这种情况下,在卷积之间没有池层的好处是什么?
在设计用于提取DNA基序的卷积神经网络的背景下,为什么一个卷积层之间没有最大池函数? 以下是此架构出现的上下文。
-
分布分析
1. 简介 分布分析报告可以帮助您查看事件在不同区间的发生频次,从而判断用户的使用习惯和活跃情况。除了次数,您还能够查看其它事件指标的用户数量分布。 分布分析能够帮助您洞察这些问题: · 对比不同来源渠道的用户在站点的行为次数分布,如浏览页面1-3次,3-10次,10次以上,不同区间的用户数量有多少 · 上周推广活动客单价的人数分布情况 · 改版后,用户的每日启动次数是否增加 2. 使用说明 2.
-
python3.x - Python数据缺失怎么顺延与数据分段求值?
计算出的 start_date_min 日期当日可能有数据也可能没数据,当没数据就想顺延到有数据的日期,请问怎么改代码,谢谢。。。。 还有个问题就是2020怎么换成年份字符窜,有知道的一起指教,就是怎么求每只 code 每年的最低最高价,一年一年算很麻烦,就想一下算所有的,一并谢了。。。
-
为什么我的keras模型有这么多参数?
以上是目前我的CNN的架构。然而,它说它有1.8m可训练的参数。为什么会这样?我以为第一层给出了(32*4=128个参数),但是我如何找到模型的其余部分有多少个参数? 我的理解是,CNN架构应该只依赖于过滤和最大池,因为它们是共享权重。为什么我有这么多参数?我应该如何着手减少这个数字? 我不是问如何使用“汇总”找到参数的数量。我是问为什么我的模型有这么多参数,以及我如何减少这个数字。我不直观地理解
-
使用Selenium-WebDriver/RC分析图形数据内容。无法捕获MouseOver上显示的数据
你能告诉我,我可能做错了什么,以及如何处理这件事吗?
-
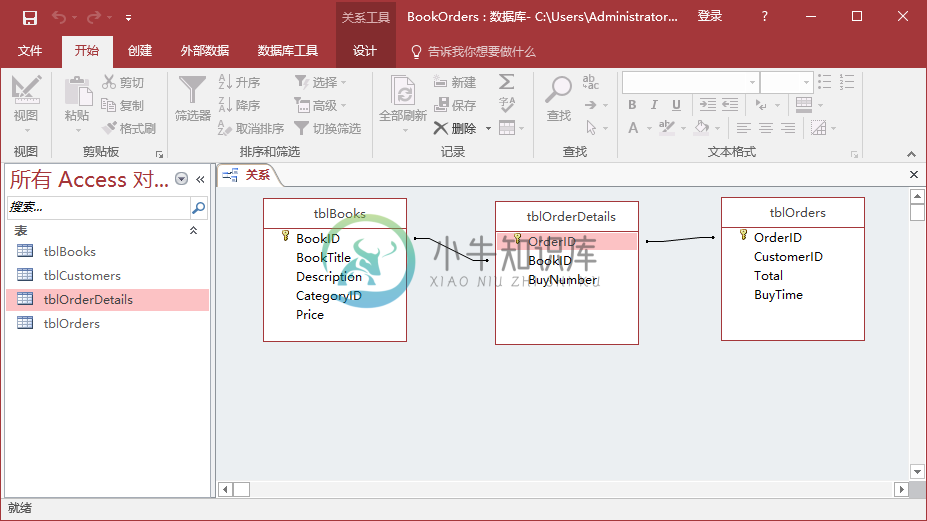 Access分组数据
Access分组数据主要内容:聚合查询,Access中的连接,示例在本章中,我们将介绍Access中如何计算如何分组记录。 我们创建了一个按行计算或按记录计算的字段来创建行总计或小计字段,但是如果想通过分组记录而不是单个记录来计算,那该怎么办呢? 可以通过创建聚合查询来实现这一点。 聚合查询 聚合查询也称为总计或汇总查询是总和,质量或组的详细信息。它可以是总金额或总金额或记录的组或子集。 聚合查询可以执行许多操作。下面是一个简单的表格,列出了分组记录中总的方法。
-
hazelcast数据分布
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
数据集拆分
在机器学习中,通常将所有的数据划分为三份:训练数据集、验证数据集和测试数据集。它们的功能分别为 训练数据集(train dataset):用来构建机器学习模型 验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数 测试数据集(test dataset):用来评估训练好的最终模型的性能 不断使用测试集和验证集会使其逐渐失去
-
卷积神经网络的分层训练
是否有方法按层(而不是端到端)训练卷积神经网络,以了解每一层对最终架构性能的贡献?
-
kafaka 生产数据时数据的分组策略
本文向大家介绍kafaka 生产数据时数据的分组策略相关面试题,主要包含被问及kafaka 生产数据时数据的分组策略时的应答技巧和注意事项,需要的朋友参考一下 生产者决定数据产生到集群的哪个 partition 中 每一条消息都是以(key,value)格式 Key 是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个 partition
-
删除数据库中的数据。分离实例
当我尝试从数据库中删除数据时: 我得到一个错误: 但当我换成: 数据被删除了。为什么? 我想看看实体是否得到了管理: 我看到了真实。 那为什么呢? 在一种情况下会产生错误?
-
排序后的数据帧分区数?
spark如何在使用< code>orderBy后确定分区的数量?我一直以为生成的数据帧有< code > spark . SQL . shuffle . partitions ,但这似乎不是真的: 在这两种情况下,spark都< code >-Exchange range partitioning(I/n ASC NULLS FIRST,200),那么第二种情况下的分区数怎么会是2呢?
-
Python中的这种分配称为什么?a = b =真
问题内容: 我知道元组拆包,但是在单行上有多个等号的情况下,此分配称为什么?啦啦 它总是让我感到有些烦恼,尤其是当RHS易变时,但是我在查找合适的关键字以在文档中搜索时遇到了真正的麻烦。 问题答案: 这是一连串的作业,用来描述它的术语是… -我可以打鼓吗? 链接分配 。 我只是在Google上进行了一次全面的搜索,发现该主题上没有太多要阅读的内容,可能是因为大多数人都觉得它非常简单易用(而且只有真
-
 分享一些最近数据分析/产品方向实习面试的题目吧~
分享一些最近数据分析/产品方向实习面试的题目吧~面了三家互联网,b站携程小红书,拿了一家实习offer,问的比较多的题记录分享一下。 一开始都是先自我介绍,然后就是做题。。 首先是SQL题。 1.左连接和右连接的区别 2.union 和 union all的区别 3.熟悉开窗函数吗?讲一下row_number和dense_rank的区别。 4.hive行转列怎么操作的 5.要求手写的题主要考了聚合函数和开窗,row_number(),sum()
-
 Android中Service实时向Activity传递数据实例分析
Android中Service实时向Activity传递数据实例分析本文向大家介绍Android中Service实时向Activity传递数据实例分析,包括了Android中Service实时向Activity传递数据实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android中Service实时向Activity传递数据的方法。分享给大家供大家参考。具体如下: 这里演示一个案例,需求如下: 在Service组件中创建一个线程,该线程用来生产数值