《数据分析这么卷的吗?》专题
-
 百度提前批数据分析二面
百度提前批数据分析二面1.深挖简历 2.GMV拆解 异动分析 3.数据分析工具竞品对比 没手撕 体感一般 分享攒好运🍀
-
 淘天数据分析师二面面经
淘天数据分析师二面面经整体感觉面试难度和阿里系公司相当,属于中等难度,我个人给它打了三颗星。 面试过程: 自我介绍:首先,面试官让我做了一个简短的自我介绍,主要包括我的项目经验和实习经历。 模型约束:接着,面试官问我如何在模型中添加约束条件。 电商建模特点:然后,他询问了电商场景下有哪些特点可以用于建模。 双十一销量预判:面试官还问了我如何预判双十一大促期间的销量。 大促推荐策略:在大促期间,如何进行商品推荐也是一个重
-
 字节跳动-数据分析实习生
字节跳动-数据分析实习生二面(约35分钟) 1、自我介绍(在学校的课程上完了吗,可以实习多久等) 2、描述ABtest你所知道的全部内容 3、描述z统计量,t统计量,F统计量 4、z分布,t分布的区别是什么 5、两道SQL题目: (a)找到每个班的学生的数量 ;(b)每个班各科目平均成绩>80分的学生人数和比例 6、怎么分析抖音某个商品购买量下降 7、反问环节
-
 蔚来数据分析实习生面经
蔚来数据分析实习生面经接到电话第二天早上就要面试,用的飞书视频面。 因为时间原因没过,很荒谬啊,谁来告诉我大学生如何做到开学后还要五天全天线下实习的,,,好了,吐槽到此为止,面试官人很好,很温柔反正 1、自我介绍 2、介绍一个最有价值的项目经历 3、深度挖掘这个项目的一些提问 4、提问一个其他相关的项目经历 5、对公司产品的了解(我面试的是某项产品下面的数据分析岗位) 6、从数据的角度如何评价产品好坏,如何挖掘数据背后
-
 2023春招-面试-京东-数据分析
2023春招-面试-京东-数据分析公司:京东(京东物流) 岗位:数据分析 形式:视频面试 视频面试平台:JoyMeeting、手机 时长:30分钟 流程: 1、自我介绍 2、大学的专业是自己选的吗? 3、你在职业规划上最关注的三个方面。 4、假如我们现在的业务部门可能很多表格都需要手工收集,手工用Excel进行分析,花费的时间比较多,你会从哪些方面着手来实现数据体系的改善? 5、通过之前实习的了解后,你觉得在物流行业的数据应用方面
-
 2022日常实习-一面数据-数据分析师-面试
2022日常实习-一面数据-数据分析师-面试公司:一面数据 岗位:数据分析师 形式:视频面试 视频面试平台:飞书 面试官:两个数据分析师 时长:30分钟 流程: 0、面试官自我介绍 1、自我介绍 2、这个实习的岗位更偏向于商业分析,可能更偏向于洞察的产出、可视化的呈现、前端debug等。想问一下你对这一块的看法是什么? 3、过往经历中有哪些是数据分析实际落地到业务上或者有产出实际价值的,可以介绍一下吗? 4、项目经历深挖。数据可视化是基于什
-
 字节跳动-数据分析/数据科学-日常实习
字节跳动-数据分析/数据科学-日常实习已经入职一个多月了,才想起来写篇面经,有些面试细节记得不太清楚了,大家仅供参考。总体来说面试体验挺好,问的问题也没有很刁钻(可能是急缺人手),废话不多说直接上干货 一面 1. 自我介绍 2. 项目介绍-主要关于我在美团实习做的项目,AB实验,如何确保用户画像相似,观察的核心指标等等 3. t检验和z检验 4. p值的意义 5. sql:求用户留存 6. 逻辑回归背后的核心原理 7. 随即森林和xg
-
关键数据结构和相关函数分析
关键数据结构和相关函数分析 对于第一个问题的出现,在于实验二中有关内存的数据结构和相关操作都是直接针对实际存在的资源--物理内存空间的管理,没有从一般应用程序对内存的“需求”考虑,即需要有相关的数据结构和操作来体现一般应用程序对虚拟内存的“需求”。一般应用程序的对虚拟内存的“需求”与物理内存空间的“供给”没有直接的对应关系,ucore是通过page fault异常处理来间接完成这二者之间的衔接。
-
解析数据
Entry conn.GetAsync() 返回的是一个 Entry 集合,Entry 对应 binlog 记录,它可能是事务标记也有可能是行数据变化,通过 Entry.EntryType 来区分,一般事务的标记在业务消费处理时不需要处理。 示例: var entries = await conn.GetAsync(1024); foreach (var entry in entries) {
-
ElasticSearch中的分析器是什么?
本文向大家介绍ElasticSearch中的分析器是什么?相关面试题,主要包含被问及ElasticSearch中的分析器是什么?时的应答技巧和注意事项,需要的朋友参考一下 在ElasticSearch中索引数据时,数据由为索引定义的Analyzer在内部进行转换。 分析器由一个Tokenizer和零个或多个TokenFilter组成。编译器可以在一个或多个CharFilter之前。分析模块允许您在
-
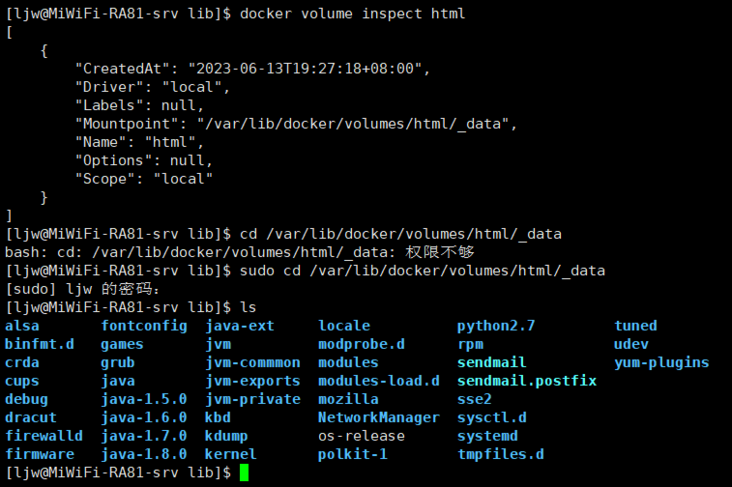 java - docker中数据卷的目录不存在?
java - docker中数据卷的目录不存在?我在容器挂载数据卷时出现了如下图的问题: 在查看html数据卷时出现了挂载点路径,但是当我想要切换到该目录时,无法进入该目录,并且在lib目录下也没有docker目录。这是为什么呢?我该如何能顺利切换到目录呢? 创建容器并挂载数据卷的操作位:
-
 (可内推)百词斩商业分析/数据分析实习生面经
(可内推)百词斩商业分析/数据分析实习生面经工作地点:成都市天府软件园 1.自我介绍:无实习经历/计算机相关专业2.面试问题(45min): -自我介绍 -你在竞赛中主要是负责leader还是执行者 -如果队员出现了矛盾你如何协调 -作为商业分析师,关注的数据指标 -估算双流机场每天航班数量 -估算全国大学生数量 -估算成都出租车数量 -销量下降会如何拆分 -x宝类电商软件最关心的数据指标 -SQL是自己学的还是学校教的,为什么自学 -如何
-
 美团探索分析产品组-数据产品(分析方向)面经
美团探索分析产品组-数据产品(分析方向)面经一面 2023.1.10 着重考察个人性格能力(自驱性、积极主动性、对成长的思考)、过往项目的参与深度 自我介绍 选一段实习经历,讲一下你的工作和角色 快手这段经历干了很久,为什么要离职 你说你在快手后期是主动思考的角色,讲一个例子证明一下 你觉得这些实习经历里,让你觉得有挑战,比较困难的事情或者时刻是什么 用一句话形容你自己 你下一段实习的目标是什么,希望获得什么 面试官介绍岗位对接的业务、工作
-
为什么这个JSON数据无效?[重复]
我有以下JSON文件,它是通过调用数据流生成的。使用以下代码,我无法打开文件,而是出现以下错误: 我使用了Jsonlint并得到以下错误: 我曾尝试通过pandas打开该文件,但也不起作用。任何帮助都将不胜感激,我不知道如何调试这一点。 输出:
-
 数据分析24暑期实习总结(3)-淘天数分oc
数据分析24暑期实习总结(3)-淘天数分oc写在前面 bg:9本+水硕,投递时实习经历:中厂数分+大厂数据产品+大厂数分本身数学统计基础很差,ml相关基础也差,求职意向主要为业务向数分手动加粗:希望认出的大佬手下留情,私聊就好,社恐害怕评论区掉马甲。也欢迎各位牛友交流哇!打破信息差~ ---分割线--- 岗位:淘天-天猫事业部-数据分析 tl:3.19投递-4.6一面-4.7二面-4.12oc-5.17再次oc。。 ---分割线--- 一面