《数据分析这么卷的吗?》专题
-
分析云是什么
使用指南 - 分析云 - 分析云是什么 一、对企业的价值 百度统计分析云是一款智能、敏捷的用户增长分析产品,以强大的数据采集和数据分析等能力,帮助企业实现数据资产沉淀,驱动企业业务全方位成长! 数据资产沉淀:帮助企业实现全域数据采集,安全、可靠的数据智能管理 数据驱动业务增长:深度挖掘数据价值,助力企业实现全业务优化升级 二、五大产品优势 全域数据采集 融合多端行为数据,底层数据全量无采样,满足企
-
分析云是什么
1. 对企业的价值 百度统计分析云是一款智能、敏捷的用户增长分析产品,以强大的数据采集和数据分析等能力,帮助企业实现数据资产沉淀,驱动企业业务全方位成长! 数据资产沉淀:帮助企业实现全域数据采集,安全、可靠的数据智能管理 数据驱动业务增长:深度挖掘数据价值,助力企业实现全业务优化升级 2. 五大产品优势 全域数据采集 融合多端行为数据,底层数据全量无采样,满足企业对全域用户数据的需求 多维
-
MongoDB数据库的日志文件深入分析
本文向大家介绍MongoDB数据库的日志文件深入分析,包括了MongoDB数据库的日志文件深入分析的使用技巧和注意事项,需要的朋友参考一下 前言 日志是MongoDB中一个非常重要的功能,他保证了数据库服务器在意外断电、自然灾害下数据的完整性 。MongoDB日志记录了数据库实例的健康状态、语句的执行状况、资源的消耗情况,所以日志对于分析数据库服务和性能优化很有帮助。 因此,很有必要花费一些时间来
-
 Python运用于数据分析的简单教程
Python运用于数据分析的简单教程本文向大家介绍Python运用于数据分析的简单教程,包括了Python运用于数据分析的简单教程的使用技巧和注意事项,需要的朋友参考一下 最近,Analysis with Programming加入了Planet Python。作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析。具体内容如下: 数据导入 导入本地的或者web端的CSV文件;
-
SQL数据库中的维度和单位分析
问题内容: 问题: 关系数据库(Postgres),用于存储各种测量值的时间序列数据。每个测量值可以具有特定的“测量类型”(例如,温度,溶解氧等),并且可以具有特定的“测量单位”(例如,华氏/摄氏度/开尔文,百分数/毫克/升等)。 问题: 有没有人建立过类似的数据库以保持尺寸完整性? 有什么建议吗? 我正在考虑建立一个measurement_type和一个measurement_unit表,这两个
-
 数据分析面试|美团商业分析2|秋招三面Offer
数据分析面试|美团商业分析2|秋招三面Offer笔试,8月15日,行测题,包括四部分:逻辑推理、数字判断、言语理解、资料分析。 一面,8月20日 1. 自我介绍。(主要经历是数据挖掘建模) 2. 介绍下实习中项目的脉络?遇到的困难?怎么解决?结果怎么样? 3. 除了技术上,做了哪些工作?(说明商分更重视业务能力) 4. 为什么到这家公司实习?答:想了解认识直播这个行业。(没有过相关行业思考的别给自己挖坑) 5. 追问:现在对于行业的认识和思考?
-
移动默认docker postgres数据卷
我使用以下命令创建了docker postgis容器: 这为/var/lib/docker/volumes/[some\u very\u long\u id]/\u data中的数据创建了一个卷 现在我需要将此卷移动到其他地方以方便我的外包承包商的备份......并且不知道如何做到这一点。我有点迷路了,因为似乎有不同的替代方案,例如数据卷和fs挂载。 那么今天正确的做法是什么?如何将我当前的数据目
-
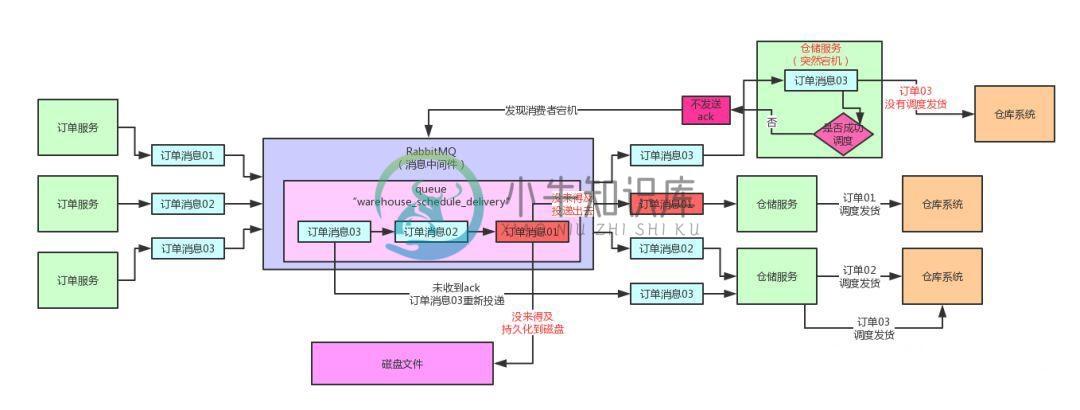 MQ这么用,数据丢失的概率仅有0.0001%
MQ这么用,数据丢失的概率仅有0.0001%主要内容:一、前情提示,二、保证投递消息不丢失的confirm机制,三、confirm机制的代码实现,四、confirm机制投递消息的高延迟性,五、高并发下如何投递消息才能不丢失,六、消息中间件全链路100%数据不丢失能做到吗?一、前情提示 上篇文章:《选Redis做MQ的人,是脑子里缺根弦儿吗?》,我们分析了RabbitMQ开启手动ack机制保证消费端数据不丢失的时候,prefetch机制对消费者的吞吐量以及内存消耗的影响。 通过分析,我们知道了prefetch过大容易导致内存溢出,prefe
-
 爱回收(业务数据分析师)面经分享
爱回收(业务数据分析师)面经分享1月3号下午HR在BOSS直聘与我联系,沟通好以后约定1月5号下午2点面试。 一共3轮面试,一个下午流程全部走完,整个面试经过如下: 1.一面(HR初试): 耗时30分钟左右,主要针对简历上的过往经历详细做了沟通了解,也问了期望薪资等问题 2.二面(部门leader面): 耗时1个小时多,是一位年轻的美女面试官,针对简历上的过往工作经历和项目经历进行了深挖,问了不少细节,很专业。 问了以后的职业发
-
 快手 数据分析师-电商 一面 60分钟
快手 数据分析师-电商 一面 60分钟面试官是个小姐姐,人很好,沟通愉快。Base在北京,说希望我能实习5-6个月,但是我说因为研究生九月开学,所以没办法更久。接着告诉我每天的实习时间还挺长,早上10点半到晚上10点(sos),问能不能接受。 自我介绍 问我这么多段Data(DE, DA, DS,BA实习),自己对哪一块更感兴趣? 我回答:商业分析(即落脚到商业决策会让我更有成就感) 自己举一段印象最深的商业分析的经历说说? e.g.
-
将分析数据从Spark插入到Postgres
问题内容: 我有Cassandra数据库,可以通过Apache Spark使用SparkSQL从该数据库分析数据。现在我想将那些分析过的数据插入PostgreSQL中。除了使用PostgreSQL驱动程序之外,是否有其他方法可以直接实现此目的(我想通过postREST和Driver实现它,我想知道是否有类似的方法)? 问题答案: 目前,尚无将RDD写入任何DBMS的本地实现。这里是Spark用户列
-
AJAX提交表单数据实例分析
本文向大家介绍AJAX提交表单数据实例分析,包括了AJAX提交表单数据实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了AJAX提交表单数据的方法。分享给大家供大家参考。具体如下: 遍历表单各元素,将参数值组织成JSON格式 这里对CheckBox复选框做了特殊处理,后台接收到的该值为所有复选框值用逗号的拼接 AJAX的调用: 谈到服务器端返回的JSON格式数据,支持如下格式 前端调
-
Android React-Native通信数据模型分析
本文向大家介绍Android React-Native通信数据模型分析,包括了Android React-Native通信数据模型分析的使用技巧和注意事项,需要的朋友参考一下 无论是计算机领域还是日常生活中,我们所言的通信,其核心都是数据信息的交换,而数据模型的优劣对通信效率有着决定性的作用。 在React-Native项目中,Javascript语言与Native两种语言(Java或OC等)间存
-
Mysql数据表分区技术PARTITION浅析
本文向大家介绍Mysql数据表分区技术PARTITION浅析,包括了Mysql数据表分区技术PARTITION浅析的使用技巧和注意事项,需要的朋友参考一下 在这一章节里, 我们来了解下 Mysql 中的分区技术 (RANGE, LIST, HASH) Mysql 的分区技术与水平分表有点类似, 但是它是在逻辑层进行的水平分表, 对于应用而言它还是一张表, 换句话说: 分区不是实际真正的对一张表
-
 详解Python数据分析--Pandas知识点
详解Python数据分析--Pandas知识点本文向大家介绍详解Python数据分析--Pandas知识点,包括了详解Python数据分析--Pandas知识点的使用技巧和注意事项,需要的朋友参考一下 本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. 2. 缺失值的处理 缺失值是数据中因缺少信息而造