《神策数据笔试》专题
-
 蚌埠住了,23阿里灵犀游戏策划实习(非文字)笔试经历
蚌埠住了,23阿里灵犀游戏策划实习(非文字)笔试经历从本科生到硕士研究生第一次参加笔试就是阿里的笔试,还是很开心的😊 上面单选啥的都很简单。 具体就说一说后面记得的一些填空题 一个是写三个excel的函数并说明意义,还有一个是根据公式函数去填空 最后的简答题,第一个是五行属性游戏设计,设计一个界面,设计五行技能,设计一个角色有三个技能槽怎么设计技能槽与五行属性相搭配合理。类似于一个原神的游戏系统设计,我是用了三国全战,卧龙苍天陨落,战锤,山海经各
-
 秋招面试神器——题库
秋招面试神器——题库#设计人秋招总结#【23届交互or体验设计岗位】 通常来说,专业类面试的问题基本就是那些,有很多问题是可以提前准备的。 【第一阶段】在完成作品集后,在大量面试前,根据自己的求职岗位方向准备一套题库,在这个时候可以参考一些博主的分享,尽量搭建一个比较完善的题库。 ⚠️:可以参考博主分享的问题,不要过分借鉴博主的答案,一定要根据自身经历回答。 【第二阶段】在不断面试中复盘,丰富完善自己的题库,增加一些
-
 碰到个神仙面试官
碰到个神仙面试官蔚来 嵌入式软件开发一面 大概面了接近一个小时,其中只有三十多分钟是在正经面试,后面的时间基本都在聊天,聊蔚来的工作强度、聊他对我的建议、聊他对应届生求职的建议、聊他为什么从*跳到蔚来、聊初入职场应该注意什么、聊他对蔚来发展前景的看法、聊应届生应该怎么选择公司与职位、聊他为什么不读研,甚至聊到了他老婆总吐槽他喜欢“好为人师”,最后说下一轮面试应该会在节后再联系了 1. 自我介绍 2. 为什么这么多
-
汇合和卡桑德拉:获取数据异常:无法将数据反序列化到Avro,未知的神奇字节
我遵循了http://www.confluent.io/blog/kafka-connect-cassandra-sink-the-perfect-match/我可以从avro控制台向cassandra插入数据。现在我正在尝试将其扩展到使用水槽,我的机器中设置了水槽,它将拾取日志文件并将其推送到kafka,尝试将我的数据插入cassandra数据库。在文本文件中,我正在放置数据 {“id”: 1,
-
Laravel策略(函数App\Policy的参数太少)
我正在尝试为用户设置策略。然而,我不断得到一个错误: 太少的参数功能应用\政策\用户政策::更新(),1传递 /vendor/laravel/framework/src/Illuminate/Auth/Access/Gate.php在第481行,正好2预期(视图: /resources/views/users/index.blade.php) 错误异常 /app/Policies/UserPoli
-
神经网络中隐藏的神经元在做什么?
例如,我的训练集是20 x 20个图像或400个特征图像来识别书写数字,我假设我在NNs中有模型3层:输入层包含400个神经元;一个隐藏层包含25个神经元,输出层包含10个神经元。我读了《神经网络与深度学习》的第一章。 最后一部分“一个简单的手写数字分类网络”(您可以使用ctrl-f进行搜索),它说“隐藏层中的神经元检测是否存在以下图像”。所以,它想说隐藏层中的神经元是通过图像呈现的吗?我认为它们
-
用PyTorch数据加载器将三维和一维特征传递给神经网络
我有大小为2x8x8的张量的例子,我使用PyTorch Dataloader。但是现在我想添加一个额外的1微调张量,大小为1(单个数字)作为输入。 所以我有两个神经网络的输入参数,一个是多维的,用于卷积层,另一个是我稍后将连接的。 也许我可以为每个张量形状使用两个数据加载器,但是我不能洗牌它们。 如何将一个PyTorch数据加载器用于这两个不同的输入张量?
-
 2024/8/17 美团秋招第二场后端 笔试 算法与数据结构
2024/8/17 美团秋招第二场后端 笔试 算法与数据结构时间是晚上7点到8点半 总共一个半小时 已知10个元素数据(54,28,16,34,73,62,95,60,26,43)依次插入节点的方法生成一颗二叉排序树,再查找成功的情况下,每个元素的平均比较次数为? 解 理解二叉树结构 总比较次数应该为 1+2+3+3+2+3+3+4+4+4=29 平均比较次数为2.9 给定一个无向图的节点编号结合为{A,B,C,D,E,F},边的结合为{A-C,A-D,B
-
如何在将数据发送到另一个应用程序时实施重试策略?
我正在开发将数据发送到的应用程序。以下是我的应用程序的功能: 我有一个类,它将数据发送到zeromq 这个想法非常简单,我必须确保我的重试策略工作正常,这样我就不会丢失数据。这是非常罕见的,但如果我们没有收到确认。 我正在考虑构建两种类型的,但我无法理解如何在此处构建与我的程序相对应的: 在这种情况下,它将在每次重试之间的特定睡眠中重试N次,之后,它将删除记录。 在这种情况下,它将指数级地继续重试
-
 Shopee笔试经验 虾皮笔经
Shopee笔试经验 虾皮笔经虾皮 Shopee 笔经 #大数据开发2024笔面经# 💼岗位:大数据开发实习生 昨天考的 📝 笔试题目: 题型:单选10个 30',多选5个 15',算法题3个 55' 题型分数上来说,无论单选多选都是3分,多选漏选1得一分 编程题就是常规 LeetCode 中等题 知识点范围:【不说具体题目内容】 单选: TCP连接建立过程,三次握手的流程和含义。 进程同步与互斥,信号量的基本概念和使用。
-
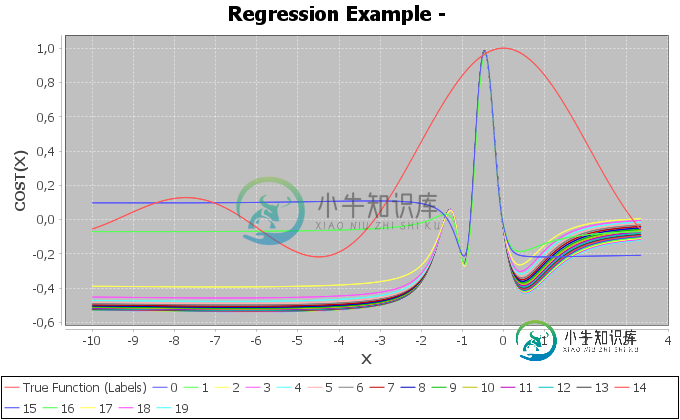 预测函数的DeepLearning4j神经网络不收敛
预测函数的DeepLearning4j神经网络不收敛我试图在DL4j中做一个简单的预测(稍后将用于具有n个特性的大型数据集),但无论我做什么,我的网络都不想学习,行为非常奇怪。当然,我学习了所有的教程,并执行了dl4j repo中显示的相同步骤,但不知何故,它对我不起作用。 对于虚拟特性,我使用以下数据: *双[val][x]特征;其中val=linspace(-10,10)...;和x=math.sqrt(math.abs(val))*val;
-
卷积神经网络中的特征映射数
我读过这篇文章http://www.codeproject.com/Articles/143059/Neural-Network-for-Recognition-of-Handwritten-Di当我转到这个:第0层:是MNIST数据库中手写字符的灰度图像,填充到29x29像素。输入层有29x29=841个神经元。图层#1:是一个包含六(6)个要素地图的卷积图层。从第1层到前一层有13x13x6=
-
对于主要数据库,实际上为“ GenerationType.AUTO”选择了什么策略?
问题内容: 在Hibernate的单证(5.1.2.2。标识符生成器)状态 AUTO:根据基础数据库的功能选择IDENTITY,SEQUENCE或TABLE。 但是,当将特定数据库定义为GenerationType.AUTO时,我无法找到文档/概述用于特定数据库的@GeneratedValue策略。 是否有人知道是否维护着主要数据库(例如Oracle,DB2,PostgreSQL,MySQL,MS
-
使用Spring和Hibernate在多租户环境中访问数据的策略
我在一个多租户环境中工作,在这个环境中,数据可以从大约10个不同的数据源(和实体管理器)通过网络应用程序(rest)前端访问。 要使用的entityManager取决于其余api中的URL参数,例如。api/订单/1/1000003。 我需要使用entitymanager“1”来获取数据。目前,在创建hibernate会话和通过hibernate条件创建查询之前,我正在使用存储库层中调用setDi
-
Maven 3神器问题
问题内容: 我使用struts2-archtype-starter在Eclipse中创建了一个新的struts项目。 在执行任何操作之前,我的项目中已经存在一些错误。解决了大多数问题,但仍有1个仍然给我一些问题。 我尝试将tools.jar手动添加到我的存储库中,但没有解决问题。 我的pom看起来像这样 问题答案: 您看到的错误可能是因为您没有正确设置JAVA_HOME路径。你看到类似的东西吗?