《神策数据笔试》专题
-
神经网络
神经网络 (Neural Network) 是机器学习的一个分支,全称人工神经网络(Artificial Neural Network,缩写 ANN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。 Perceptron (感知器) 一个典型的神经网络由输入层、一个或多个隐藏层以及输出层组成,其中箭头代表着数据流动的方向,而圆圈代表激活函数(最常用的激活函数为
-
全才神话
全才神话 这是个需要设计和开发一个web解决方案的角色, 不仅需要有很深厚的技术栈, 而且需要在视觉设计, UI/交互设计, 前端开发和后端开发有大量的经验. 任何可以以一个专业的水平承担这 4 个角色中的一个或多个的人(又称全才或全栈开发者)是很少的. 务实一点, 你应该寻求, 或者雇佣一个在其中一个角色堪称专家的人. 那些声称在一个或多个角色上是专家的人是非常罕见的,
-
神经网络
译者:bat67 最新版会在译者仓库首先同步。 可以使用torch.nn包来构建神经网络. 我们以及介绍了autograd,nn包依赖于autograd包来定义模型并对它们求导。一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。 例如,下面这个神经网络可以对数字进行分类: 这是一个简单的前馈神经网络(feed-forward network)。它接受一
-
搜图神器
这是一款Android开源的图片搜索APP Material Design风格。使用Rxjava,MVP快速开发框架,封装的RecyclerView,retrofit 2.0网络请求库,Fresco图片加载库,图片瀑布流和错位式布局。具有热门推荐、每日一笑、板块分类、一键下载图片、分享图片、收藏图片、设为桌面壁纸、设为锁屏壁纸等功能。 界面截图:
-
Spring RestTemplate:指数退避重试策略
null 有没有一种方法可以在Spring RestTemplate中使用指数退避?
-
大数据处理 - Hive中处理大量数据频繁变动的增量更新策略?
hive怎么进行增量更新呢?看到很多人是先分区例如根据create_time分区。每天根据create_time 新增数据。但是如果我的数据是会经常变动的呢?例如去年的数据,今年修改了。我应该如何更新这条数据进去。假设我现在数据是上亿的,应该怎么处理。 假设数据初始数据: 1 2024-08-10 15:18:00.000 wang 2 2024-08-10 15:18:00.000 xxx 3
-
关于数据库连接池大小的决策的思考
问题内容: 我正在基于开源Java的应用程序,即xwiki。Insie hibernate.cfg.xml我可以看到参数connection.pool_size和statement_cache.siz的值为2(每个)。我的应用程序在某个时间点的最大负载为100个用户。现在,我的问题是什么才是理想的连接池大小。对我来说2号看起来要少得多。如果一次有100个用户连接,则98个用户必须等待释放连接?我是
-
将Redis数据同步到MySQL的最佳策略是什么?
问题内容: 用例是使用Redis作为MySQL的本地缓存 MySQL中的数据格式为:单个主键和其他几个字段。不会有查询数据库的交叉表 Redis键是MySQL中的主键,值是包含MySQL中其他字段的哈希 关闭电源后,少于一分钟的数据丢失是可以接受的。 我的解决方案是: Redis写入AOF文件,某些进程将监视此文件并将更新的数据同步到MySQL Hack Redis可以在多个文件中写入AOF,就像
-
 线性代数笔记
线性代数笔记来自 MIT 课程线性代数的笔记,可以在 麻省理工公开课:线性代数(http://open.163.com/special/opencourse/daishu.html)观看。
-
 广州银行信用卡中心策略数据分析实习生面试
广州银行信用卡中心策略数据分析实习生面试刚刚面试完,第一部分自我介绍,第二部分根据简历提问,第三部分反问。 重点第二部分,问得好细,从学校专业开始问(俺经管的),为什么会选择数据分析;第二部分揪比赛经历,也问的好细,那个比赛都是老历史了,俺真的不记得那么多了,问我比赛选题的自变量有哪些,y是啥多重结果?真的,现在让我翻聊天记录都找不到答案。第三个是实习经历,问了我写在简历上的每一个字!!!问的我都以为他想跳槽去我前东家的工作了 中间的过
-
根据策略无效:策略条件失败:[“eq”,“$ACL”,“public-read”]from postman
嘿,我使用这个设置直接上传使用预签名的url到S3。https://devcenter.heroku.com/articles/s3-upload-python在我保留的Cors策略中:允许起源*rest一切都一样。 在我得到一个预签名的响应后,我使用postman尝试将一个图像文件上传到S3。但似乎出现了一个错误: 我想我把科斯的政策搞砸了。 桶策略也是空的..我需要在那里添加一些东西吗。(对不
-
无法将pyspark数据帧加载到决策树算法。它说不能使用pyspark数据帧
我在IBM的数据平台上工作。我能够将数据加载到pyspark数据框架中,并创建了一个spark SQL表。分割数据集后,将其输入分类算法。它会出现诸如spark SQL数据无法加载之类的错误。规定的日期。 错误: TypeError:预期的序列或类似数组,已获取{ 在这个错误之后,我做了这样的事情: 错误: 属性错误回溯(最近一次调用最后一次)在()5 X_序列,y_序列,X_测试,y_测试=序列
-
ios学习笔记之基础数据类型的转换
本文向大家介绍ios学习笔记之基础数据类型的转换,包括了ios学习笔记之基础数据类型的转换的使用技巧和注意事项,需要的朋友参考一下 前言 前几天在做一些小功能的时候,忽然发现有的基础数据转换都忘记了,于是赶紧整理下记下来!方便自己以后查阅,也给有需要的朋友们一些参考,下面话不多说,来看详细的内容。 一、NSString 字符串拼接: 字符串与int 字符串与float NSData与字符串 二、N
-
本地保存来自远程iPython笔记本的数据
我使用的是在远程服务器上运行的ipython笔记本电脑。我想在本地保存笔记本中的数据(例如熊猫数据框)。 目前,我正在将数据保存为远程服务器上的. csv文件,然后通过scp将其移动到我的本地机器。有没有更优雅的直接从笔记本电脑获取的方法?
-
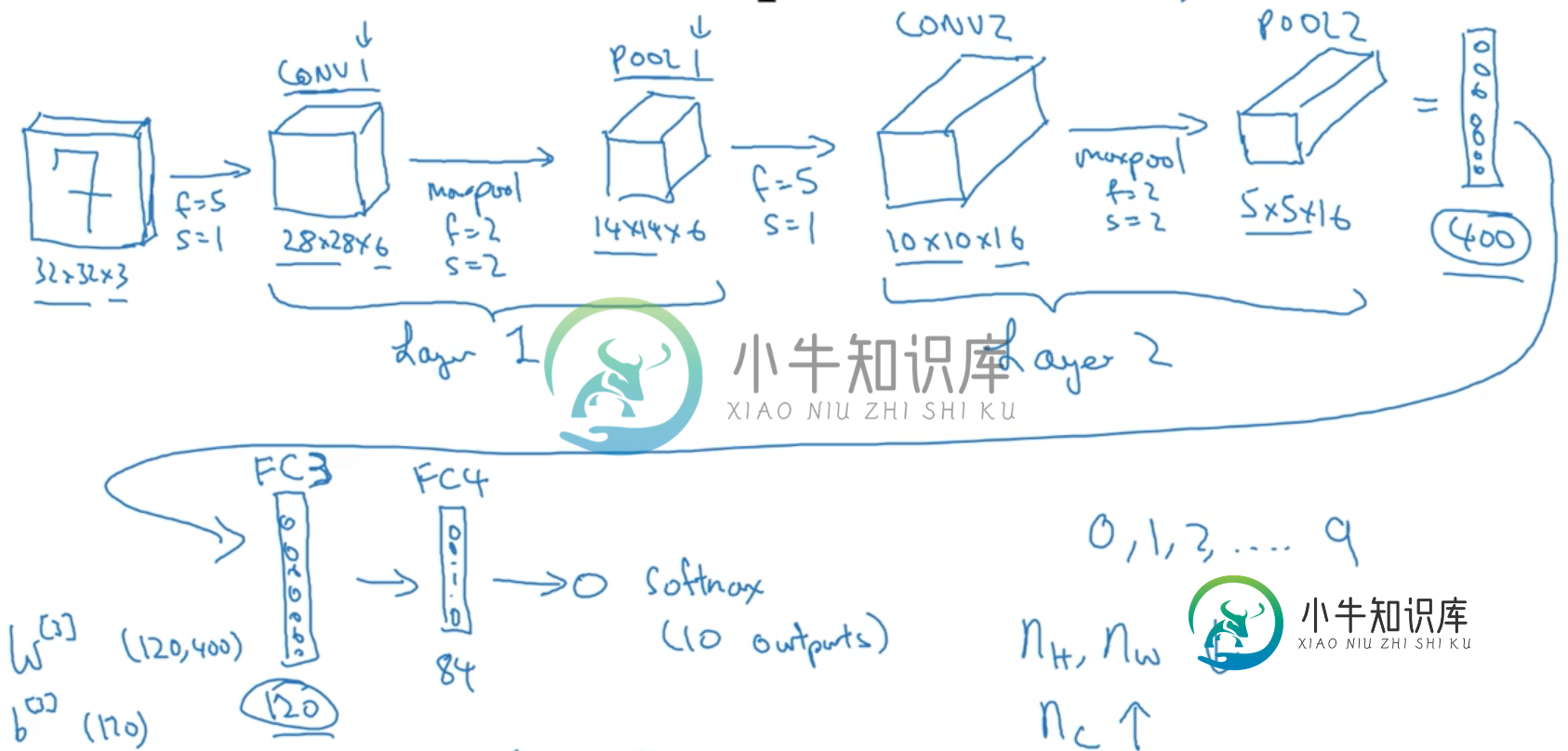 卷积神经网络中参数个数的计算
卷积神经网络中参数个数的计算我是CNN研究的新手,我从看Andrew'NG的课程开始。有一个例子我不明白: 他是如何计算#参数值的?