《神策数据笔试》专题
-
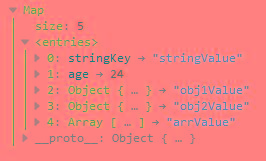 ES6学习笔记之新增数据类型实例解析
ES6学习笔记之新增数据类型实例解析本文向大家介绍ES6学习笔记之新增数据类型实例解析,包括了ES6学习笔记之新增数据类型实例解析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了ES6学习笔记之新增数据类型。分享给大家供大家参考,具体如下: 1、数据解构赋值 1、数组的解构赋值 基本用法:let [key1,key2...]=[value1,value2...] 注意左右的key与value格式要匹配对应,键值可以缺省,但
-
了不起的node.js读书笔记之mongodb数据库交互
本文向大家介绍了不起的node.js读书笔记之mongodb数据库交互,包括了了不起的node.js读书笔记之mongodb数据库交互的使用技巧和注意事项,需要的朋友参考一下 这周的学习主要是nodejs的数据库交互上,并使用jade模板一起做了一个用户验证的网站。主要是遇到了一下几个问题。 1.mongodb版本过低 npm ERR! Not compatible with your op
-
以编程方式导入/导出(Azure)数据块笔记本
我有一个数据砖笔记本,它将表的位置作为输入,然后生成图形。 我可以从包装笔记本中为许多不同的表运行此笔记本。 是否有可能每次笔记本运行时,我都会将结果保存为databricks文件系统中的html。 实质上,我想以编程方式导出笔记本,就像我手动执行文件一样 这可能吗?如果是,如何实现? 注意:我在想,如果没有开箱即用的东西,我想笔记本会保存在驱动程序内部的某个地方。我可以从那里获取它,并使用dbu
-
张量流卷积神经网络负维数
我正在制作这个CNN模型 ''' 但这是给我一个错误:-InvalidArgumentError:负尺寸造成的减去2从1'{{nodeconv2d_115/Conv2D}}=Conv2D[T=DT_FLOAT,data_format="NHWC",膨胀=[1,1,1,1],explicit_paddings=[],填充="VALID",步幅=[1,2,2,1],use_cudnn_on_gpu=t
-
使用Keras函数API调整神经网络超参数
我有一个包含两个分支的神经网络。一个分支接受卷积神经网络的输入。另一个分支是一个完全连接的层。我合并这两个分支,然后使用softmax获得输出。我不能使用顺序模型,因为它已被弃用,因此必须使用函数式API。我想调整卷积神经网络分支的超参数。例如,我想弄清楚我应该使用多少卷积层。如果是顺序模型,我会使用for循环,但由于我使用的是函数式API,我真的不能这样做。我已经附加了我的代码。有人能告诉我如何
-
如何计算卷积神经网络的参数个数?
我正在使用千层面为MNIST数据集创建CNN。我将密切关注这个示例:卷积神经网络和Python特征提取。 我目前拥有的CNN架构(不包括任何退出层)是: 这将输出以下图层信息: 并输出可学习参数的数量为217,706 我想知道这个数字是如何计算的?我已经阅读了许多资源,包括这个StackOverflow的问题,但没有一个明确概括了计算。 如果可能,每层可学习参数的计算是否可以泛化? 例如,卷积层:
-
Matlab神经网络到C神经网络的转换
我用newff在Matlab中创建了一个用于手写数字识别的神经网络。 我只是训练它只识别0 输入层有9个神经元,隐层有5个神经元,输出层有1个神经元,共有9个输入。 我的赔率是0.1 我在Matlab中进行了测试,网络运行良好。现在我想用c语言创建这个网络,我编写了代码并复制了所有的权重和偏差(总共146个权重)。但当我将相同的输入数据输入到网络时,输出值不正确。 你们谁能给我指点路吗? 这是我的
-
根据安全策略创建Java沙箱
问题内容: 我需要创建环境来运行可能不受信任的代码。程序允许连接到预配置的地址:端口,而无其他要求(甚至读取系统时间)。我已经编译了班白名单。我搜索了类似的问题,但仅找到基于不推荐使用AFAIK的SecurityManager的模板。有人可以给我一个简单的示例,如何基于安全策略和AccessController在沙箱中运行代码吗? 问题答案: 据我所知,仍然是运行安全检查的SecurityMana
-
神经网络中的输入形状和神经元数量可以不同吗?[复制]
在Francois Chollet的《使用Python进行深度学习》一书中,我发现了一段代码,输入形状为784,单位为32? 我想知道他们有什么不同。 下面是确切的代码:
-
模块化应用程序堆栈中的虚拟数据和单元测试策略
问题内容: 您如何管理用于测试的虚拟数据?保留它们各自的实体?在单独的测试项目中?从外部资源使用串行器加载它们?或者只是在需要的地方重新创建它们? 我们有一个应用程序堆栈,其中包含多个模块,每个模块都包含一个模块,每个模块包含一个实体。每个模块都有其自己的测试,需要虚拟数据来运行。 现在,具有很多依赖关系的模块将需要来自其他模块的大量伪数据。但是,那些对象不会发布其虚拟对象,因为它们是测试资源的一
-
及策
及策 及策是一个基于用户行为和用户属性对用户进行精细化运营和再营销的实时分析平台,能够帮助用户最高效解决用户拉新、活跃和再营销转化问题。主要包含App归因分析、App用户运营解决方案、Web用户运营解决方案、微信小程序用户运营解决方案在传统网站分析的基础上更专注于每一个用户的互动行为和其本身属性,深入理解每一个用户并引导其达成转化。最终我们希望结合一系列用户标属性和签体系进行聚类分析依托强大的第一
-
对于主要数据库,“GenerationType.Auto”实际上选择了什么策略?
Hibernate文档(5.1.2.2.Identifier generator)状态 但是我找不到文档/概述,在将特定数据库定义为GenerationType.auto时,@GeneratedValue策略用于这些数据库。 有人知道是否有人为主要数据库(例如Oracle、DB2、PostgreSQL、MySQL、MSSQL、…)维护了实际生成策略的列表吗?到哪里去找?
-
 游戏数分笔试经验贴(09.25)~
游戏数分笔试经验贴(09.25)~一家体验还不错的游戏数分笔试!!! 10道题,5道单选+5道业务题 单选考察的都是统计学内容,具体5道业务题如下: 第一题 某游戏的整体好评率在下跌,但按性别维度拆分时发现。男,女好评率都上涨了,请问是什么情况? 辛普森悖论,AB测试中男女比例不同所导致的差异。 解决措施:用户人群分层消除性别因素带来的影响 第二题 给出注册表,登出表来统计不同等级段,职业级别,留存情况 子查询,表连接,窗口函数
-
 富途网络科技-数分笔试
富途网络科技-数分笔试37道题,35道单选基本是关于数学的排列组合概率统计,两道关于sql的编程操作,一个是取数操作,一个是判断数据完整。只把第一道编程过了,第二道题没时间搞了。感觉整体难度还好,但准备的还不够充分,看运气吧
-
 今日数分笔试 (京东+顺丰)
今日数分笔试 (京东+顺丰)JD 20个选择题 全是大数据 概率论 怀疑是数开的题目 三道编程: 贪心 SQL 一道简单 顺丰:四十个选择题 还是全是概率论和大数据 一道简答:设计箱子 一道编程:堆 维护k个最小值