《字节跳动二面》专题
-
动态maven人工关节
POM是否可以声明(或至少发布)包含系统属性的?我指的是实际项目的工件,而不是依赖项。 我正在使用maven构建一个scala项目,因此,为了允许为不同的scala版本发布项目,pom.xml我想声明:
-
未启动数据节点
我正尝试使用以下指南在伪分布式配置中设置Hadoop 0.20.203.0版本: http://www.javacodegeeks.com/2012/01/hadoop-modes-explained-standalone.html 运行脚本后,运行“jps”。 我有个错误: 我不完全确定,但我相信这可能与datanode没有运行有关。 有谁知道我做错了什么,或者怎么解决这个问题吗? 编辑:这是d
-
C#无符号字节加密到Java有符号字节解密
问题内容: 我在C#中有一个应用程序,它使用RijndaelManaged 加密 部分文件 (因为它们是大文件)。因此,我将文件转换为字节数组并仅对其一部分进行加密。 然后,我想使用Java解密文件。因此,我只需要解密用C#加密 的文件的一部分 (意味着那些字节)。 问题来了。因为在C#中,我们 有无符号字节 ,在Java中,我们有 符号字节 。因此,我的加密和解密无法按照我想要的方式工作。 在C
-
如何修复1字节UTF-8序列的无效字节1
问题内容: 我正在尝试使用Java方法从数据库中获取以下xml,但出现错误 用于解析xml的代码 数据 错误 我读了一些线程,这是因为xml中有一些特殊字符。如何解决这个问题? 问题答案: 如何解决这个问题? 使用正确的字符编码读取数据。错误消息表示您正在尝试以UTF-8格式读取数据(故意或因为这是未指定的XML文件的默认编码),但实际上它采用的是其他编码,例如ISO-8859-1或Windows
-
字节伙伴(字节码操作)拦截器不工作:没有
我必须将注释XmlElementWrapper和XmlElement添加到列表类型的字段,但是这些注释需要名称。我想把属性名设置为字段名。我愿意: 这是我的拦截器: 这是目标类的一部分: 但我有一个例外: [public static void factory.framework.SetterListInterceptor.getter(java.lang.reflect.Method)、publ
-
如何追加字节,多字节和缓冲区到ArrayBuffer在javascript?
Javascript ArrayBuffer或TypedArrays没有任何类型的appendByte()、appendBytes()或appendBuffer()方法。所以,如果我想一次填充一个数组缓冲一个值,我该怎么做呢?
-
1.15 第十四部分 线性二次调节,微分动态规划,线性二次高斯分布
第十四部分 线性二次调节,微分动态规划,线性二次高斯分布 上面三个名词的英文原版分别为: Linear Quadratic Regulation,缩写为LQR; Differential Dynamic Programming,缩写为DDP; Linear Quadratic Gaussian,缩写为LQG。 1 有限范围马尔科夫决策过程(Finite-horizon MDPs) 前面关于强化学习
-
Oozie蜂巢行动悬而未决,心脏永远跳动
我试图通过我在顺化中创建的Oozie工作流运行Hive操作,但是操作“心跳”是永远的,并且不会执行HiveSQL。 我读过其他关于心脏永远跳动的文章,但这篇文章似乎发生在另一个地方,在SQL语句被解析之后。我检查了集群中每个节点的内存,并验证了任务计数参数是否合理。 以下是hive-config.xml文件: 我知道Hive连接正在工作,因为如果提供了错误的SQL语句、错误的URL或错误的驱动程序
-
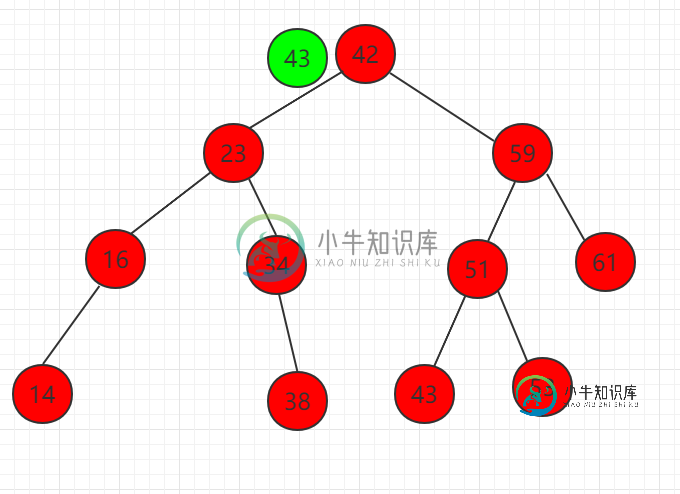 二分搜索树节点的查找
二分搜索树节点的查找主要内容:src/runoob/binary/BinarySearchTreeSearch.java 文件代码:二分搜索树没有下标, 所以针对二分搜索树的查找操作, 这里定义一个 contain 方法, 判断二分搜索树是否包含某个元素, 返回一个布尔型变量, 这个查找的操作一样是一个递归的过程, 具体代码实现如下: ... // 查看以node为根的二分搜索树中是否包含键值为key的节点, 使用递归算法 private boolean contain (Node node, Key key )
-
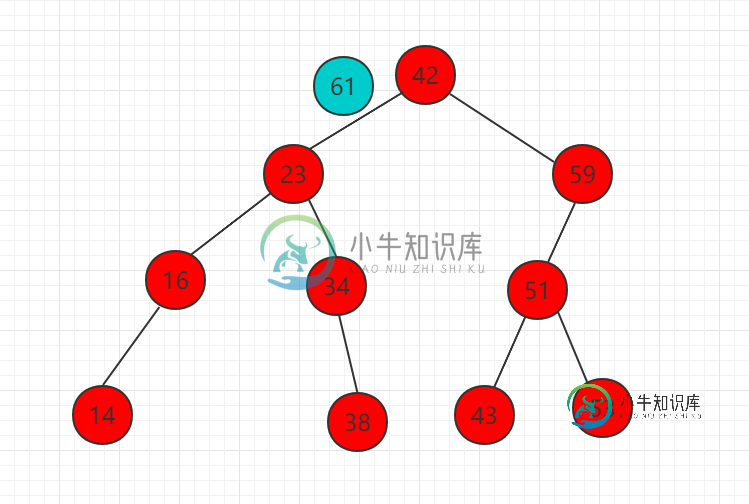 二分搜索树节点的插入
二分搜索树节点的插入主要内容:src/runoob/binary/BinarySearchTreeInsert.java 文件代码:首先定义一个二分搜索树,Java 代码表示如下: public class BST < Key extends Comparable <Key >, Value > { // 树中的节点为私有的类, 外界不需要了解二分搜索树节点的具体实现 private class Node { private Key key ; private Val
-
二进制搜索树节点大小
我对如何在二叉查找树中排列节点的顺序有点困惑。左边的二叉查找树中的子树节点能比根节点大吗? 例如,以下内容会是二叉搜索树吗? 上面让我困惑的是1(3)的右子树是否可以大于原始根节点(2)。
-
合并两个二叉树节点和
我正在研究合并两个二叉树的问题(https://www.geeksforgeeks.org/merge-two-binary-trees-node-sum/)我很难理解一些递归。为什么要将递归语句设置为和?当你这样做的时候,是否等于两个值? 我只是不确定为什么我们要将递归语句设置为t1.leftt1.right'
-
二叉树中的非边界节点
我有一个二叉树,我想打印所有非边界节点。边界节点:-所有叶节点从根到最左节点路径上的所有节点所有节点从根到最右节点。 我在树结构中使用了一个额外的布尔值来确定它是否是边界节点,如果不是边界节点,则进行遍历和打印。有人能想出一个更好的方法吗,因为它使用了一些额外的空间(虽然很少)。
-
删除节点二进制搜索树
目前,我在理解如何在没有传递节点时从二进制搜索树中删除节点时遇到了一个问题。我有两个类,BSTSet和BSTNode,每个类都有一个remove方法。。 当我被传递一个节点时,我理解删除方法,但当我在根上调用remove方法并试图从node类中删除节点时,我不知道从何处开始。有人能告诉我吗?谢谢如果您想了解更多信息,请询问。
-
全二叉树中的叶节点数
问题查找具有n个节点的完整二叉树中的叶节点数。 我为上述问题编写了一个递归程序,每当我到达一个没有子节点的节点时,遍历树并增加叶节点的数量。但由于这棵树是一棵完整的二叉树,我认为这会使问题变得更容易,但我不知道如何解决。它是否可以简化为紧凑形式(类似于公式)。