《音视频》专题
-
音频会话:在应用程序中录制音频,同时允许音乐应用程序通过蓝牙播放
我一直无法让应用程序录制音频,同时让iPhone音乐应用程序通过蓝牙扬声器播放。 例如,如果我这样做: 然后音乐应用程序将开始通过iPhone内置的扬声器播放音乐,而不是通过蓝牙。换句话说,似乎没有办法在应用程序中录制音频的同时还允许通过蓝牙播放音乐。 如果我删除AVAudioSessionColloryOptionDefaultToSpeaker,那么音频路由将切换到接收器。这比让它通过iPho
-
使用sox和python根据时间戳列表使音频区域静音
问题内容: 我有一个音频文件。 我有一堆[开始,结束]时间戳片段。 我想实现的目标: 说音频长6:00分钟。 我拥有的细分是:[[0.0,4.0],[8.0,12.0],[16.0,20.0],[24.0,28.0]] 在将这两个参数传递给sox + python之后,输出应该是6分钟长的音频,但仅在分段传递的时间内才具有音频。 即我想将原始音频传递给SOX + python,以便生成除所有与传递
-
有没有办法使用Web音频API对音频流重新采样?
我目前正在使用Web音频API。我设法“读懂”了一个麦克风,并将它播放给我的扬声器,这非常无缝。 使用Web Audio API,我现在想重新取样传入的音频流(又名麦克风)从44.1kHz到16kHz。16kHz,因为我正在使用一些需要16kHz的工具。由于44.1kHz除以16kHz不是整数,我相信我不能简单地使用低通滤波器和“跳过样本”,对吗? 我还看到一些人建议使用,但由于它已被弃用,我觉得
-
ios核心音频:如何使用交织音频从AudioBuffer获取样本
我使用函数将音频文件读入。 这是音频的和ASBD: 因此,我们获得并交织了2个声道的音频,每个声道的16位符号为int init: 并读入缓冲区: 是的和实例,它在前面的代码中启动,为了节省空间,我没有粘贴到这里。 我试图完成的是在渲染回调中修改音频样本。 是否有可能从音频数据的UInt32阵列中获得Sint16左右声道样本?
-
Flash流音频问题:音频只能在帧变化时多次播放
好吧,事情是这样的:我在做一个智力竞赛游戏,我决定给它放一张配乐。它是一个单一的音频文件,我上传到我的自定义域,并通过代码流。我还添加了播放/暂停按钮,这样播放器就可以播放和暂停音乐。音乐在框架1上自动播放,我的游戏的“开始”按钮在那里。但是,如果玩家答错了一个问题,他会回到第一帧。问题是音乐的另一个“实例”开始播放,导致两个音乐在同一时间播放。如果他再答错,就会有三首音乐回放,以此类推....我
-
ffmpeg 4:在视频播放过程中使用stream_loop参数循环音频,最终导致无限循环
> 上下文 我使用的软件 问题 结果 4.1。实际结果 4.2.预期成果 我尝试了什么来修复这个错误? 如何重现此缺陷:提供所需数据的最小且可测试的示例 这个问题 来源 我想将音频WAV设置为视频WEBM的背景声音。视频可以比音频短,也可以比音频长。在我将音频添加到视频的那一刻,我不知道两个流的长度。音频必须重复,直到视频结束(如果视频在最后一次音频重复结束之前结束,音频可能会被截断)。 我使用f
-
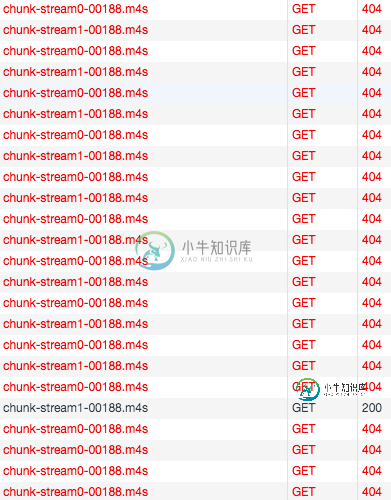 FFMPEG/DASH-LL以不同的速率创建音频和视频块;玩家感到困惑(404个错误)
FFMPEG/DASH-LL以不同的速率创建音频和视频块;玩家感到困惑(404个错误)我试图从静态文件创建一个MPEG-DASH“实时”流,以测试各种低延迟模式。FFmpeg中的DASH混音器创建两个适应集,一个用于视频块,一个用于音频块。 但是,音频和视频块文件的创建速率并不相同(应该是吗?)。也就是说,是视频块,是音频块。运行几秒钟后,webroot目录包含: 流不会在或shaka player,视频块有很多错误。玩家依次从stream0和stream1请求块,即stream0
-
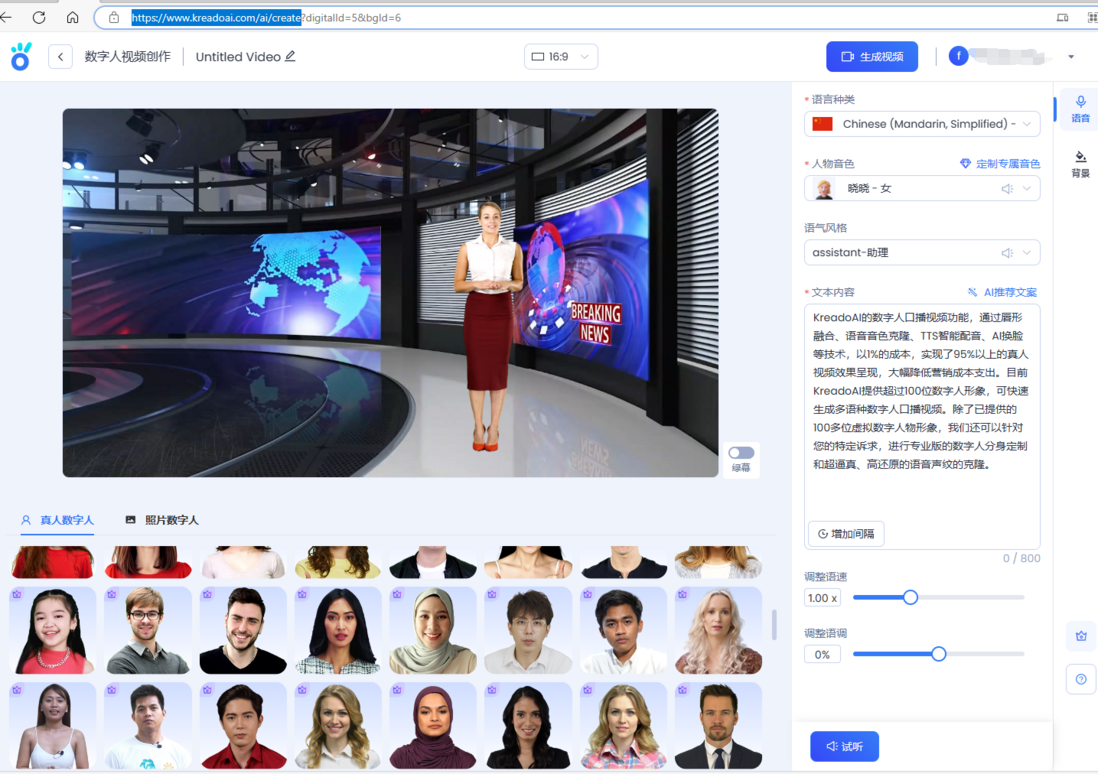 人工智能 - 请问数字人+背景图片+音频生成一段视频是如何实现的?
人工智能 - 请问数字人+背景图片+音频生成一段视频是如何实现的?网站:https://www.kreadoai.com/ai/create
-
视图 - 内置视图
英文原文:http://emberjs.com/guides/views/built-in-views/ Ember中定义了一套用于构建一些非常基础的控件的视图,比如文本输入框、勾选框和选择列表。 这些视图有: Ember.Checkbox 1 2 3 4 <label> {{view Ember.Checkbox checked=model.isDone}} {{model.title
-
视图 - 定义视图
英文原文:http://emberjs.com/guides/views/defining-a-view/ 你可以使用Ember.View来渲染一个Handlebars模板并将它插入到DOM中。 为了告诉视图要用哪个模板,可以设置它的temaplateName属性。例如,如果我有一个像这样的<script>标签: 1 2 3 4 5 6 7 <html> <head> <script
-
视差滚动视图
利用UIScrollView实现视差滚动效果。在demo中,滑动ScrollView,背景图和文字的滚动速度不一样。直接用ScrollView 的协议,对其子视图的坐标进行随机系数比例的位置移动修正,从而实现视差滚动效果。没有用其他的框架,代码简单。 作者说:原创Demo 转载请注明出处。 [Code4App.com]
-
python语音识别实践之百度语音API
本文向大家介绍python语音识别实践之百度语音API,包括了python语音识别实践之百度语音API的使用技巧和注意事项,需要的朋友参考一下 百度语音对上传的语音要求目前必须是单声道,16K采样率,采样深度可以是16位或者8位的PCM编码。其他编码输出的语音识别不出来。 语音的处理技巧: 录制为MP3的语音(通常采样率为44100),要分两步才能正确处理。第一步:使用诸如GoldWave的软件,
-
Vala的语音识别和文本语音转换
[][1]我正在尝试用Vala语言做一个类似siri的应用程序。然而,我找不到任何语音识别或文本到语音库的vala,这是必不可少的。瓦拉有语音识别和语音文字转换吗?如果是的话,你能说出他们的名字吗? 顺便说一句,我是新的vala编程,所以也请做一些例子... 非常感谢。
-
如何使用语音控制音乐播放器
我正在开发一个应用程序,它可以使用语音控制音乐播放器。例如,当我说"play"音乐播放器播放歌曲,或者说"Next"音乐播放器将播放下一首歌曲,等等。我已经谷歌了,但没有找到任何想法或源代码。 问题: > 使用语音控制音乐播放器的想法 源代码示例。 提前感谢。 可能相关:Android-语音控制-媒体意图
-
将语音转换为发音的最佳方法
我想构建一个Android应用程序,它可以识别语音并将其转换为发音文本(即比较特殊单词和用户语音之间的真实发音或口音)。我只知道可以创建语音到文本。我想转换用户说的任何单词。 有没有API来做?如果没有,请帮助我如何实现它。