《百奥》专题
-
 百度 java后端实习生 质量效能研发部 一二三面
百度 java后端实习生 质量效能研发部 一二三面lz大概7月份的时候在百度官网投递的,大概9月份突然某一天hr打电话过来面试,base上研大厦,然后现在已经在这干了差不多两个多月,现在有点空回过头来写个面经。总体比较简单,就是招人进来干活的。 一面 50min 自我介绍 Java基础 泛型 接口的意义 JVM垃圾回收算法 Mysql索引相关 算法题 1.括号匹配 2.合并两个有序数组 然后聊了些七七八八的 二面 30min 聊了下Kafka在之
-
 百度测开QA及运管组实习一面二面面经(已Offer)
百度测开QA及运管组实习一面二面面经(已Offer)一面2.23 0.自我介绍 1.实习经历,为什么要离开 2.Linux命令,如何查看进程,如何查看指定端口号 3.测试登录(账号密码按钮) 4.手撕sql 学生信息表和成绩表查询张三的成绩 5.手撕水仙花数 6.智力题:10箱苹果,每箱10个,其中9箱里50g/个,1箱40g/个,只称一次找到40g/个那箱 没准备过智力题,没答上来 7.反问 偏测试还是偏开发?答:都有,xxxxxx,你偏向哪个?
-
 百度移动软件研发提前批一面8.24下午2点:20min
百度移动软件研发提前批一面8.24下午2点:20min1.先问基础,贪心算法和动态规划算法的使用场景 2.大数据量的情况下,查找第100大元素 3.KMP算法的思想 4.HTTP和HTTPS的区别,加密是在哪层 5.正态分布得出的结论是什么(真不记得结论是什么了,不让说概念) 6.设计模式的六大原则,外观模式知道吗,装饰者模式知道吗,组合模式知道吗,一问三不知,我太菜了,只用过简历上的单例,享元,代理,原型,观察者。 7.java创建线程有哪些方式
-
python2爬取百度贴吧指定关键字和图片代码实例
本文向大家介绍python2爬取百度贴吧指定关键字和图片代码实例,包括了python2爬取百度贴吧指定关键字和图片代码实例的使用技巧和注意事项,需要的朋友参考一下 目的:在百度贴吧输入关键字和要查找的起始结束页,获取帖子里面楼主所发的图片 思路: 获取分页里面的帖子链接列表 获取帖子里面楼主所发的图片链接列表 保存图片到本地 注意事项: 问题:在谷歌浏览器使用xpath helper插件时有匹配结
-
iOS实现百度地图拖拽后更新位置以及反编码
本文向大家介绍iOS实现百度地图拖拽后更新位置以及反编码,包括了iOS实现百度地图拖拽后更新位置以及反编码的使用技巧和注意事项,需要的朋友参考一下 前言 最近在开发中遇到了百度地图的开发,功能类似于微信中的发送位置,拖拽从新定位,以及反编码,列表附近的位置。分析出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。 效果图: 百度地图拖拽更新位置.gif 实现思路 思路就是将一个UIImag
-
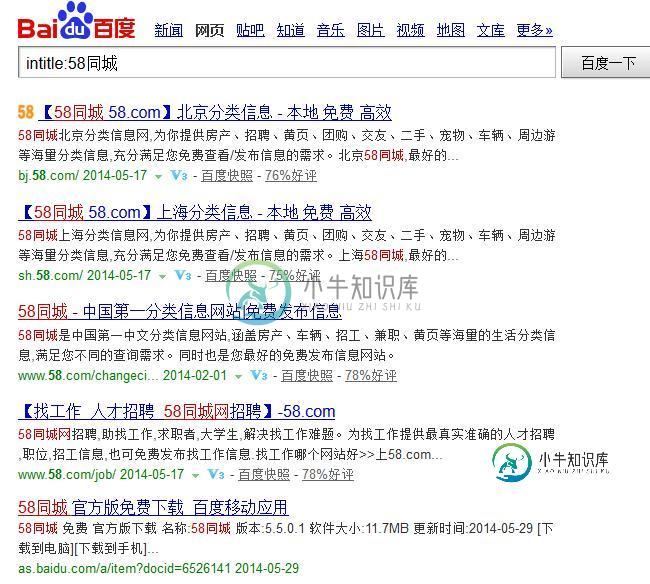 Python实现抓取百度搜索结果页的网站标题信息
Python实现抓取百度搜索结果页的网站标题信息本文向大家介绍Python实现抓取百度搜索结果页的网站标题信息,包括了Python实现抓取百度搜索结果页的网站标题信息的使用技巧和注意事项,需要的朋友参考一下 比如,你想采集标题中包含“58同城”的SERP结果,并过滤包含有“北京”或“厦门”等结果数据。 该Python脚本主要是实现以上功能。 其中,使用BeautifulSoup来解析HTML,可以参考我的另外一篇文章:Windows8下安装Be
-
PHP计算百度地图两个GPS坐标之间距离的方法
本文向大家介绍PHP计算百度地图两个GPS坐标之间距离的方法,包括了PHP计算百度地图两个GPS坐标之间距离的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP计算百度地图两个GPS坐标之间距离的方法。分享给大家供大家参考。 具体实现方法如下: 希望本文所述对大家的php程序设计有所帮助。
-
如何使百分比格式的输入在最新的AngularJS上工作?
问题内容: 我看到了这个解决方案http://jsfiddle.net/gronky/GnTDJ/,它可以正常工作。也就是说,当您输入25时,会将其推回模型为0.25 HTML: JavaScript: 我尝试使其在最新的AngularJS上运行,尽管http://jsfiddle.net/TrJcB/仍然无法正常工作,也就是说,当您输入25时,它也被推回25,因此它不能正确推入0.25模型的价值
-
将某些浮动数据帧列格式化为熊猫的百分比
我试图在IPython笔记本上写一篇论文,但在显示格式方面遇到了一些问题。假设我有以下数据帧,是否有方法将和格式化为2位小数,将格式化为百分比。 里面的数字不乘以100,例如-0.0057=-0.57%。
-
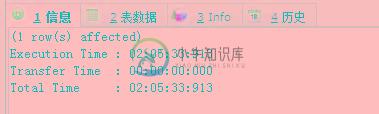 java中JDBC实现往MySQL插入百万级数据的实例代码
java中JDBC实现往MySQL插入百万级数据的实例代码本文向大家介绍java中JDBC实现往MySQL插入百万级数据的实例代码,包括了java中JDBC实现往MySQL插入百万级数据的实例代码的使用技巧和注意事项,需要的朋友参考一下 想往某个表中插入几百万条数据做下测试,原先的想法,直接写个循环10W次随便插入点数据试试吧,好吧,我真的很天真.... 执行CALL proc_initData()后,本来想想,再慢10W条数据顶多30分钟能搞定吧,结果
-
 使用Ajax模仿百度搜索框的自动提示功能实例
使用Ajax模仿百度搜索框的自动提示功能实例本文向大家介绍使用Ajax模仿百度搜索框的自动提示功能实例,包括了使用Ajax模仿百度搜索框的自动提示功能实例的使用技巧和注意事项,需要的朋友参考一下 啊啊,熬夜了。今天学习了ajax给我的感觉就是,”哇塞“ajax好酷炫哦,(额。。。后端狗,接触到了大前端的魅力了),这么晚了还是直奔主题把。Let's go! 百度搜索提示框,我想大家都很熟悉了把,是什么样子我也就不再赘述。直接看代码 来我们写一
-
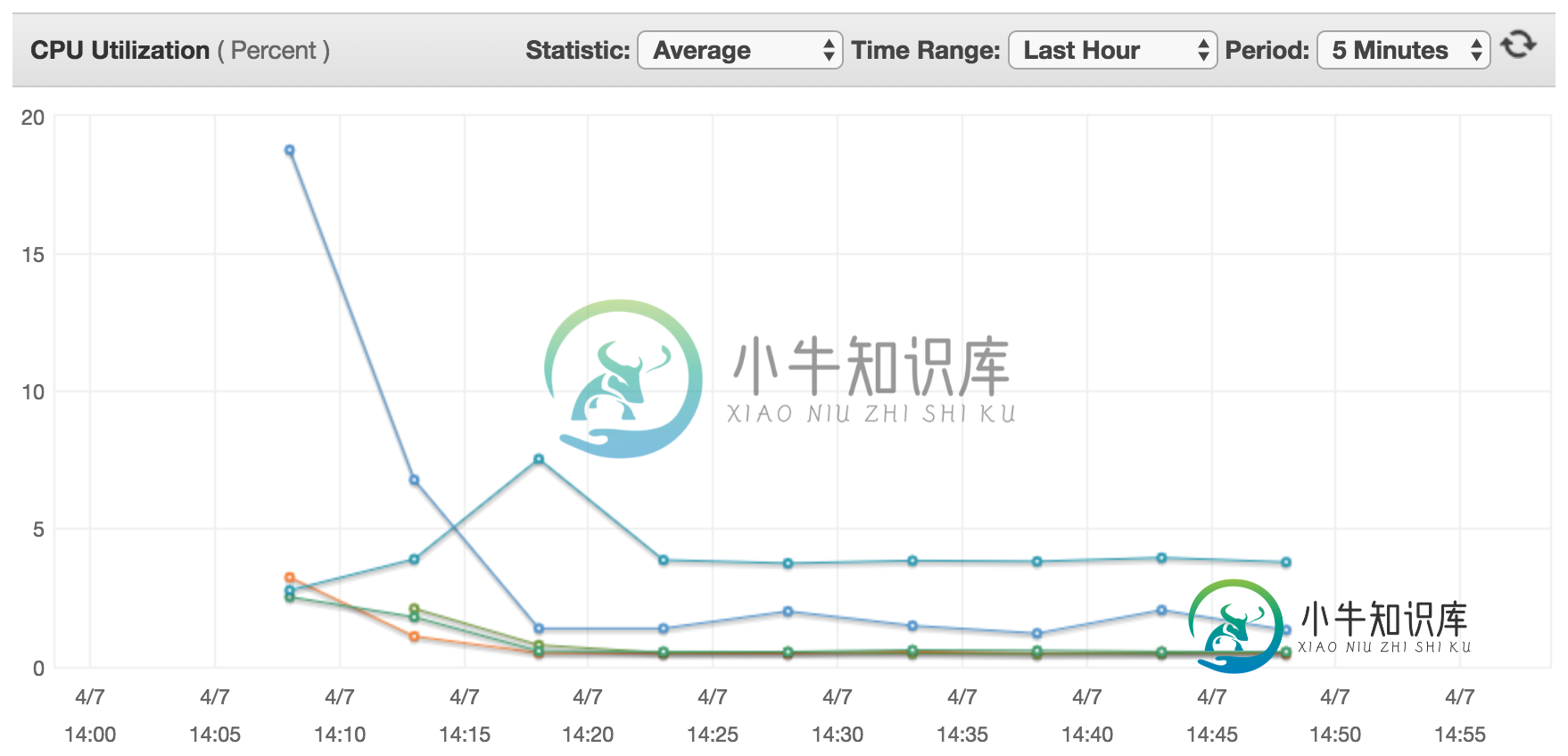 无法让Spark在AWS EMR上使用超过百分之几的资源
无法让Spark在AWS EMR上使用超过百分之几的资源我一直试图在集群模式下通过AWS EMR和YARN运行Spark作业,并且没有设置组合导致该作业最多使用可用总资源的百分之几。 以下是所有节点的典型CPU使用率图表(主节点是从20%开始,然后下降的节点,其他节点都是从节点): 上图是通过以下节点获得的: 使用以下设置运行: 我试着遵循所有典型的建议,包括Spark文档中的建议、AWS EMR文档中的建议以及Cloudera博客上这篇文章中的建议。
-
 python通过百度地图API获取某地址的经纬度详解
python通过百度地图API获取某地址的经纬度详解本文向大家介绍python通过百度地图API获取某地址的经纬度详解,包括了python通过百度地图API获取某地址的经纬度详解的使用技巧和注意事项,需要的朋友参考一下 前言 这几天比较空闲,就接触了下百度地图的API(开发者中心链接地址:http://developer.baidu.com),发现调用还是挺方便的,本文将给大家详细的介绍关于python通过百度地图API获取某地址的经纬度的相关内容
-
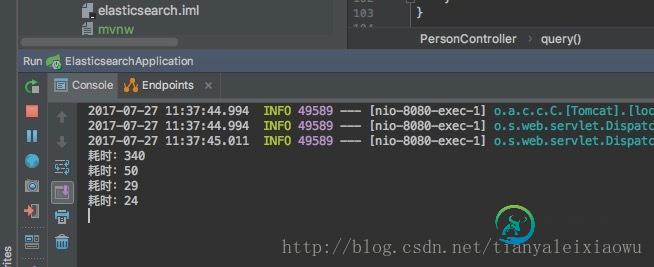 java 使用ElasticSearch完成百万级数据查询附近的人功能
java 使用ElasticSearch完成百万级数据查询附近的人功能本文向大家介绍java 使用ElasticSearch完成百万级数据查询附近的人功能,包括了java 使用ElasticSearch完成百万级数据查询附近的人功能的使用技巧和注意事项,需要的朋友参考一下 上一篇文章介绍了ElasticSearch使用Repository和ElasticSearchTemplate完成构建复杂查询条件,简单介绍了ElasticSearch使用地理位置的功能。 这一篇
-
如何导出百万记录DynamoDB表作为CSV使用数据管道?
我有一个百万记录的DynamoDB表。我正在使用数据管道将DynamoDb表导出到S3。但是数据管道以DynamoDB JSON格式将表导出为一组原始json文件。数据管道运行一小时后,由于超时异常,EMR失败。 有没有办法将DynamoDB表导出为CSV并增加数据管道中的EMR超时配置?