《百奥》专题
-
 关于我花两周找到了产品实习(收获百度offer)
关于我花两周找到了产品实习(收获百度offer)2022/11/21 - 2022/12/5,通过官网/牛客内推/BOSS直聘,投递了字节,网易,腾讯,快手,京东,小米,滴滴,美团,作业帮,好未来,脉脉,新浪等20家公司规模大于500人以上的产品实习,base以北京为主,仅面试6家,最后收到百度offer. 针对我的经历和学历背景,觉得自己拿到这次实习,在寒冬中算是轻松又幸运的,但还是很担心,明年的秋招可以有offer吗(因为被今年秋招的同校师
-
 百度数据库云平台研发面经(23 秋招提前批)
百度数据库云平台研发面经(23 秋招提前批)三面挂,具体为啥挂的我也不是很清楚,猜测没hc被排序了 三面(08.09) 实习项目 对云的理解 实习公司的基建的理解 容器与虚拟机的区别 常见的网络攻击 自己的优缺点 有没有其他offer 一共问了30min,面完就挂了,可能hc没几个,排序挂了 二面(07.29) 问了40多min业务问题......(太顶了......) 算法:字典序排序 反问:后续流程还有三面经理面+HR 一面(07.25
-
 银泰百货-银泰星-数据开发岗一二三面凉经
银泰百货-银泰星-数据开发岗一二三面凉经一面 30min 电话面试 非常温柔,也很有水平的面试官,主要是挖简历。 结束的时候还和我说了我的简历中可以优化的地方。体验很好。 二面 1h 视频面试 先挖简历 大概15min 问了许多机器学习和建模的知识,比如SVM、聚类一些基础模型的步骤 过拟合产生的原因以及如何解决 大概30min 根据我的本科专业背景问了一个开放问题 15min 之后闲聊了几分钟 是部门交叉面试,这位面试官是算法部门的,
-
常用sub agg示例 - 响应时间的百分占比趋势图
时序图除了上节展示的最基本的计数以外,还可以在 Y 轴上使用其他数值统计结果。最常见的,比如访问日志的平均响应时间。但是平均值在数学统计中,是一个非常不可信的数据。稍微几个远离置信区间的数值就可以严重影响到平均值。所以,在评价数值的总体分布情况时,更推荐采用四分位数。也就是 25%,50%,75%。在可视化方面,一般采用箱体图方式。 Kibana4 没有箱体图的可视化方式。不过采用线图,我们一样可
-
百度统计SDK开发者个人信息保护合规指引
新手入门 - 百度统计SDK开发者个人信息保护合规指引 百度统计SDK开发者个人信息保护合规指引 亲爱的开发者: 感谢您在您的移动互联网应用程序(以下简称“APP”)中集成并使用百度统计SDK! 百度统计非常重视用户个人信息保护,包括集成百度统计SDK的移动互联网应用程序的最终用户(以下简称“最终用户”)个人信息保护,特制定《百度统计SDK个人信息保护合规开发者指引》,以供您在您的APP中集成并使
-
 10.22 大数据工程师 阿里国际 百度 面经(带答案)
10.22 大数据工程师 阿里国际 百度 面经(带答案)数据库底层索引的优劣势? 数据库底层索引的优势和劣势主要取决于具体的索引类型和使用场景: 优势: 提升查询性能:索引可以加快数据库的查询速度,通过跳过不需要的数据块,减少了磁盘I/O操作。 加速排序:索引可以帮助数据库对查询结果进行排序,从而提高排序的效率。 支持唯一性约束:索引可以保证某一列或多列的唯一性,保证数据的完整性。 提高并发性能:索引可以减少数据的锁竞争,提高数据库的并发性能。 支持数
-
 2023秋招offer阿里、百度、美团、快手、滴滴、华为面经
2023秋招offer阿里、百度、美团、快手、滴滴、华为面经我面的全都是机器学习/AI/计算机视觉算法岗,拿到了自己满意的offer,菜菜的小孙同学来牛客还愿啦,希望能帮助他其他小伙伴吖,祝愿大家都能拿到心仪的offer哇! 本人本硕985,研究大方向深度学习,小方向应用于计算机视觉的连续学习/增量学习/终身学习,同时涉猎了一点元学习、多任务学习、可解释性机器学习这部分的内容。研究生期间一共完成了三篇工作,一篇nips一作(oral),一篇aaai学生二作
-
 百度二面凉经,测开也要猛刷题,是真菜啊我
百度二面凉经,测开也要猛刷题,是真菜啊我1.实习相关 2.直接手撕三道,n*m能画出正方形的个数,两个子节点的最矮公共子树,登台阶问题 3.语音发送的测试用例 4.get和post的区别 5.python多线程 6.针对用id查名字做sql优化,只能针对这个过程 7.糖盐问题,提及相等的糖和盐,往盐里放勺糖,再从盐里取勺盐放回去,哪个含其他的东西多 反问:测开算法重要吗,因为楼主是个菜鸡,三道手撕就写全了一道,回答说就是看你解题思路。
-
 百度提前批一面二面加额外一面面经分享
百度提前批一面二面加额外一面面经分享base:北京 c++/php/go开发岗 一面: 45min 1.讲一下OSI的七层模型,以及每一层的含义和应用 2.三次握手和四次挥手 3.三次握手中如果数据发送失败,让你设计你会怎么处理 4.什么是TCP 5.知不知道拥塞控制,讲一下 6.进程和线程 7.进程间有哪些通信方式,讲一下 8.Mysql中的索引讲一下 9.索引覆盖 10.数据库的隔离级别 11.场景题:如果给数据库中的表加一列数
-
 百度 商业产品运营 B端 日常实习 一面面经
百度 商业产品运营 B端 日常实习 一面面经时长:17min 自我介绍 深挖简历(询问我的两个项目中的用户需求调研的具体方法与流程,看得到哪些具体的结论) 答:分别回答了问卷和访谈两个方法,按照项目背景、基本功能、主要调研的流程、数据分析的方法与结论来答的 反问阶段 这个实习岗位的具体工作有哪些 需要关注哪些数据指标 再次提问 经过岗位的初步介绍,你认为你对于这份岗位有怎样的优势 答:结合具体介绍的内容和自己自我介绍提到的技能掌握,分点阐述
-
 机械专业转算法岗位(百度Apollo决策规划面试)
机械专业转算法岗位(百度Apollo决策规划面试)Coding: 三道算法题。。。 这就是Apollo么 如何寻找二次曲线(离散的点连成的)的最小值 迷宫问题 二叉搜索树 技术面 我的项目是:使用PPO水了一篇文章;复现了IMPALA算法;熟悉一些强化学习算法 基本的强化学习算法:DQN系列,PPO,On-Policy Off-Policy等,问的很深 文章中的强化学习建模(状态、动作、奖励函数等),网络结构 对于A*的了解么?Hybrid A*
-
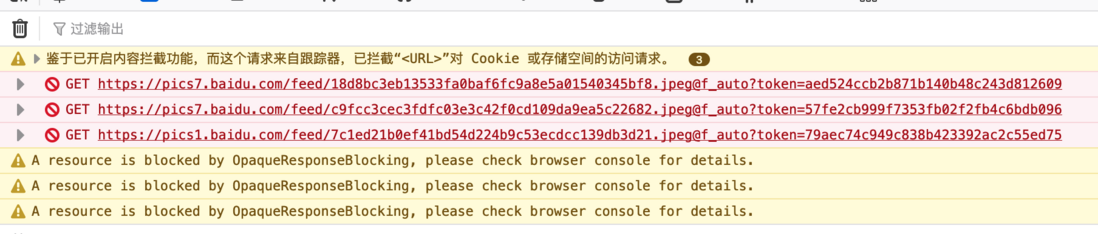 前端 - 为什么同样的 html ,线上打不开百度的 url?
前端 - 为什么同样的 html ,线上打不开百度的 url?为什么同样的 html ,线上打不开百度的 url 但是保存为本地 html,然后在浏览器打开本地 html 却可以显示百度 url 图片 鉴于已开启内容拦截功能,而这个请求来自跟踪器,已拦截“https://pics1.baidu.com/feed/7c1ed21b0ef41bd54d224b9c53ecdcc1...”对 Cookie 或存储空间的访问请求。 是百度在作恶吗?怎么解决呢? 我把
-
Jacoco eclipse插件和SonarQube中的代码覆盖率百分比值不同
问题内容: 我有一个Java项目。根据Jacoco eclipse插件(EclEmma Java代码覆盖率2.3.1.201405111647),该项目的代码覆盖率为22.3%。我生成.exec报告并将其提供给SonarQube,并使用声纳运行器进行分析。结果,SonarQube的Web界面上显示的代码覆盖率为20.2%。软件包级别的coverage值也不同于Jacoco的eclipse插件显示的
-
如何使用Linux命令获取可用的内存百分比?[关闭]
问题内容: 我想使用Linux命令行以百分比形式报告可用内存。 我使用了命令,但这只是给我数字,并且没有百分比选项。 问题答案: 使用命令: 基于此输出,我们使用awk选择特定字段并进行计算以获取内容。 这将报告正在使用的内存百分比 这将报告可用内存的百分比 您可以为此命令创建一个别名,或将其放入一个小的Shell脚本中。可以使用针对以下语句的print语句的格式化命令,根据您的需求量身定制特定的
-
在Linux中以百分比给出的CPU使用率的准确计算?
问题内容: 这个问题已经被问过很多次了,但是我找不到一个得到很好支持的答案。 很多人建议使用top命令,但是如果您运行一次top(因为您有一个脚本,例如每1秒收集一次Cpu使用情况),它将始终给出相同的Cpu使用情况结果(示例1,示例2)。 计算CPU使用率的一种更准确的方法是,从中读取值,但是大多数答案仅使用from中的前4个字段进行计算(此处是一个示例)。 从Linux内核2.6.33开始,每