
java 使用ElasticSearch完成百万级数据查询附近的人功能

上一篇文章介绍了ElasticSearch使用Repository和ElasticSearchTemplate完成构建复杂查询条件,简单介绍了ElasticSearch使用地理位置的功能。
这一篇我们来看一下使用ElasticSearch完成大数据量查询附近的人功能,搜索N米范围的内的数据。
准备环境
本机测试使用了ElasticSearch最新版5.5.1,SpringBoot1.5.4,spring-data-ElasticSearch2.1.4.
新建Springboot项目,勾选ElasticSearch和web。
pom文件如下
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.tianyalei</groupId> <artifactId>elasticsearch</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>elasticsearch</name> <description>Demo project for Spring Boot</description> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.4.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.sun.jna</groupId> <artifactId>jna</artifactId> <version>3.0.9</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
新建model类Person
package com.tianyalei.elasticsearch.model;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.GeoPointField;
import java.io.Serializable;
/**
* model类
*/
@Document(indexName="elastic_search_project",type="person",indexStoreType="fs",shards=5,replicas=1,refreshInterval="-1")
public class Person implements Serializable {
@Id
private int id;
private String name;
private String phone;
/**
* 地理位置经纬度
* lat纬度,lon经度 "40.715,-74.011"
* 如果用数组则相反[-73.983, 40.719]
*/
@GeoPointField
private String address;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
我用address字段表示经纬度位置。注意,使用String[]和String分别来表示经纬度时是不同的,见注释。
import com.tianyalei.elasticsearch.model.Person;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface PersonRepository extends ElasticsearchRepository<Person, Integer> {
}
看一下Service类,完成插入测试数据的功能,查询的功能我放在Controller里了,为了方便查看,正常是应该放在Service里
package com.tianyalei.elasticsearch.service;
import com.tianyalei.elasticsearch.model.Person;
import com.tianyalei.elasticsearch.repository.PersonRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.IndexQuery;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class PersonService {
@Autowired
PersonRepository personRepository;
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
private static final String PERSON_INDEX_NAME = "elastic_search_project";
private static final String PERSON_INDEX_TYPE = "person";
public Person add(Person person) {
return personRepository.save(person);
}
public void bulkIndex(List<Person> personList) {
int counter = 0;
try {
if (!elasticsearchTemplate.indexExists(PERSON_INDEX_NAME)) {
elasticsearchTemplate.createIndex(PERSON_INDEX_TYPE);
}
List<IndexQuery> queries = new ArrayList<>();
for (Person person : personList) {
IndexQuery indexQuery = new IndexQuery();
indexQuery.setId(person.getId() + "");
indexQuery.setObject(person);
indexQuery.setIndexName(PERSON_INDEX_NAME);
indexQuery.setType(PERSON_INDEX_TYPE);
//上面的那几步也可以使用IndexQueryBuilder来构建
//IndexQuery index = new IndexQueryBuilder().withId(person.getId() + "").withObject(person).build();
queries.add(indexQuery);
if (counter % 500 == 0) {
elasticsearchTemplate.bulkIndex(queries);
queries.clear();
System.out.println("bulkIndex counter : " + counter);
}
counter++;
}
if (queries.size() > 0) {
elasticsearchTemplate.bulkIndex(queries);
}
System.out.println("bulkIndex completed.");
} catch (Exception e) {
System.out.println("IndexerService.bulkIndex e;" + e.getMessage());
throw e;
}
}
}
注意看bulkIndex方法,这个是批量插入数据用的,bulk也是ES官方推荐使用的批量插入数据的方法。这里是每逢500的整数倍就bulk插入一次。
package com.tianyalei.elasticsearch.controller;
import com.tianyalei.elasticsearch.model.Person;
import com.tianyalei.elasticsearch.service.PersonService;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.GeoDistanceQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.sort.GeoDistanceSortBuilder;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
@RestController
public class PersonController {
@Autowired
PersonService personService;
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@GetMapping("/add")
public Object add() {
double lat = 39.929986;
double lon = 116.395645;
List<Person> personList = new ArrayList<>(900000);
for (int i = 100000; i < 1000000; i++) {
double max = 0.00001;
double min = 0.000001;
Random random = new Random();
double s = random.nextDouble() % (max - min + 1) + max;
DecimalFormat df = new DecimalFormat("######0.000000");
// System.out.println(s);
String lons = df.format(s + lon);
String lats = df.format(s + lat);
Double dlon = Double.valueOf(lons);
Double dlat = Double.valueOf(lats);
Person person = new Person();
person.setId(i);
person.setName("名字" + i);
person.setPhone("电话" + i);
person.setAddress(dlat + "," + dlon);
personList.add(person);
}
personService.bulkIndex(personList);
// SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.queryStringQuery("spring boot OR 书籍")).build();
// List<Article> articles = elas、ticsearchTemplate.queryForList(se、archQuery, Article.class);
// for (Article article : articles) {
// System.out.println(article.toString());
// }
return "添加数据";
}
/**
*
geo_distance: 查找距离某个中心点距离在一定范围内的位置
geo_bounding_box: 查找某个长方形区域内的位置
geo_distance_range: 查找距离某个中心的距离在min和max之间的位置
geo_polygon: 查找位于多边形内的地点。
sort可以用来排序
*/
@GetMapping("/query")
public Object query() {
double lat = 39.929986;
double lon = 116.395645;
Long nowTime = System.currentTimeMillis();
//查询某经纬度100米范围内
GeoDistanceQueryBuilder builder = QueryBuilders.geoDistanceQuery("address").point(lat, lon)
.distance(100, DistanceUnit.METERS);
GeoDistanceSortBuilder sortBuilder = SortBuilders.geoDistanceSort("address")
.point(lat, lon)
.unit(DistanceUnit.METERS)
.order(SortOrder.ASC);
Pageable pageable = new PageRequest(0, 50);
NativeSearchQueryBuilder builder1 = new NativeSearchQueryBuilder().withFilter(builder).withSort(sortBuilder).withPageable(pageable);
SearchQuery searchQuery = builder1.build();
//queryForList默认是分页,走的是queryForPage,默认10个
List<Person> personList = elasticsearchTemplate.queryForList(searchQuery, Person.class);
System.out.println("耗时:" + (System.currentTimeMillis() - nowTime));
return personList;
}
}
看Controller类,在add方法中,我们插入90万条测试数据,随机产生不同的经纬度地址。
在查询方法中,我们构建了一个查询100米范围内、按照距离远近排序,分页每页50条的查询条件。如果不指明Pageable的话,ESTemplate的queryForList默认是10条,通过源码可以看到。
启动项目,先执行add,等待百万数据插入,大概几十秒。
然后执行查询,看一下结果。
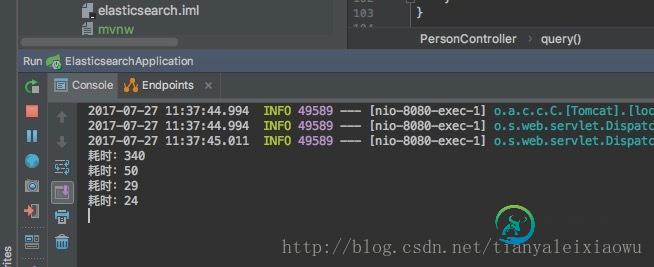
第一次查询花费300多ms,再次查询后时间就大幅下降,到30ms左右,因为ES已经自动缓存到内存了。
可见,ES完成地理位置的查询还是非常快的。适用于查询附近的人、范围查询之类的功能。
后记,在后来的使用中,Elasticsearch2.3版本时,按上面的写法出现了geo类型无法索引的情况,进入es的为String,而不是标注的geofiled。在此记录一下解决方法,将String类型修改为GeoPoint,且是org.springframework.data.elasticsearch.core.geo.GeoPoint包下的。然后需要在创建index时,显式调用一下mapping方法,才能正确的映射为geofield。
如下
if (!elasticsearchTemplate.indexExists("abc")) {
elasticsearchTemplate.createIndex("abc");
elasticsearchTemplate.putMapping(Person.class);
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
我在表里添加了500W的测试数据,表中数据如下 一次性读取 500w 数据到 JVM 内存中 必然会造成OOM现象,所以我分别试验了2个读取百万数据的方式,并用Junit分析内存占用 分页多次查询,并进行深度分页优化 Mybatis的流式查询 我从网上看了许多博客,说流式查询可以很好避免OOM问题。 但是为什么在分析堆内存占用中,反而是 多次分页查询的内存占用更小,平均只有400MB 而流式查询却
-
开启十个线程,每个线程都会去查询500W的数据。 单独一个线程,堆内存占用500M。 十个线程,堆内存占用最高也不过1400MB,为什么会这样呢?这些内存占用居然不会叠加的吗?
-
注意:我无法访问与此问题相关的源代码/数据库。这两个表位于不同的服务器上。 我在一家第三方公司工作,该公司的系统与我们自己的系统集成。他们有一个运行类似这样的查询; 它在
-
本文向大家介绍MySQL百万级数据量分页查询方法及其优化建议,包括了MySQL百万级数据量分页查询方法及其优化建议的使用技巧和注意事项,需要的朋友参考一下 数据库SQL优化是老生常谈的问题,在面对百万级数据量的分页查询,又有什么好的优化建议呢?下面将列举了一些常用的方法,供大家参考学习! 方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM
-
问题内容: 我找不到有关如何使用PHP(elasticsearch-php)中的完成建议器查询Elasticsearch的有效示例。 通过CURL查询,例如 可以,所以唯一的问题是PHP中的查询部分。 如何使用API通过完成建议器查询Elasticsearch? 问题答案: PHP ES客户端具有一种称为的方法,您可以将其用于该目的:
-
我是elasticsearch的新手,尝试使用查询、日期直方图和facets从elasticsearch检索索引数据。我有elasticsearch和kibana在服务器上正常运行。现在,我想从elasticsearch中提取特定的索引数据,并在另一个自主开发的应用程序(SpringWeb应用程序)中将其绘制为图形。因此,考虑使用spring数据elasticsearch,但通过互联网找到了使用e