
Python实现抓取百度搜索结果页的网站标题信息

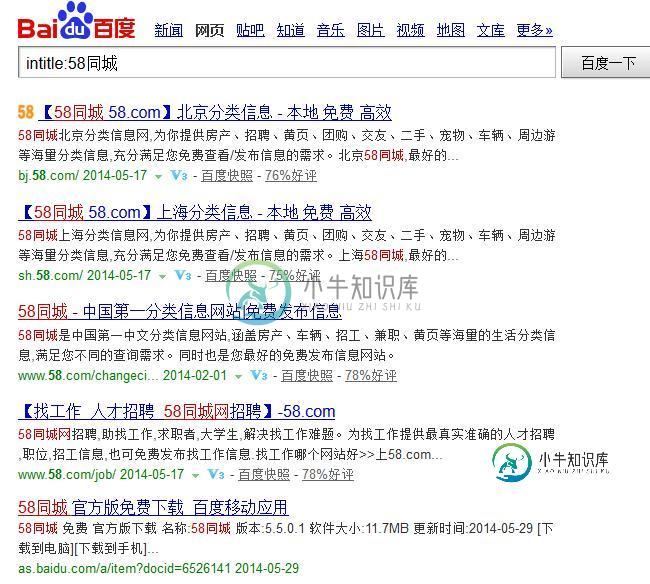
比如,你想采集标题中包含“58同城”的SERP结果,并过滤包含有“北京”或“厦门”等结果数据。
该Python脚本主要是实现以上功能。
其中,使用BeautifulSoup来解析HTML,可以参考我的另外一篇文章:Windows8下安装BeautifulSoup
代码如下:
__author__ = '曾是土木人' # -*- coding: utf-8 -*- #采集SERP搜索结果标题 import urllib2 from bs4 import BeautifulSoup import time #写文件 def WriteFile(fileName,content): try: fp = file(fileName,"a+") fp.write(content + "\r") fp.close() except: pass#获取Html源码 def GetHtml(url): try: req = urllib2.Request(url) response= urllib2.urlopen(req,None,3)#设置超时时间 data = response.read().decode('utf-8','ignore') except:pass return data
#提取搜索结果SERP的标题 def FetchTitle(html): try: soup = BeautifulSoup(''.join(html)) for i in soup.findAll("h3"): title = i.text.encode("utf-8") if any(str_ in title for str_ in ("北京","厦门")): continue else: print title WriteFile("Result.txt",title) except: pass
keyword = "58同城" if __name__ == "__main__": global keyword start = time.time() for i in range(0,8): url = "http://www.baidu.com/s?wd=intitle:"+keyword+"&rn=100&pn="+str(i*100) html = GetHtml(url) FetchTitle(html) time.sleep(1) c = time.time() - start print('程序运行耗时:%0.2f 秒'%(c))
-
本文向大家介绍python实现提取百度搜索结果的方法,包括了python实现提取百度搜索结果的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现提取百度搜索结果的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的Python程序设计有所帮助。
-
我尝试用BS4 python来抓取动态网站: https://www.nadlan.gov.il/?search=תל אביב יפו 我试过: 我有两个问题: > 当我打开站点时,数据加载需要几秒钟: 硒如何解决这些问题?
-
本文向大家介绍python抓取百度首页的方法,包括了python抓取百度首页的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python抓取百度首页的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的Python程序设计有所帮助。
-
问题内容: 最近我一直在学习很多python,以便在工作中的某些项目上工作。 目前,我需要对Google搜索结果进行一些网页抓取。我发现了几个站点,这些站点演示了如何使用ajax google api进行搜索,但是在尝试使用它之后,似乎不再受支持。有什么建议? 我一直在寻找一种方法,但似乎找不到当前有效的解决方案。 问题答案: 您随时可以直接抓取Google搜索结果。为此,您可以使用将返回前10个
-
我是python新手,正在尝试从以下站点获取数据。虽然这段代码适用于不同的站点,但我无法让它适用于nextgen stats。有人想知道为什么吗?下面是我的代码和我得到的错误 下面是我得到的错误 df11=pd。读取html(urlwk1)回溯(上次调用):文件“”,第1行,在文件“C:\Users\USERX\AppData\Local\Packages\PythonSoftwareFounda
-
我试图为所有大学足球队的名单收集数据,因为我想根据他们的名单组成对球队表现进行一些分析。 我的脚本在第一页上工作,它迭代每个团队,并可以打开每个团队的名册链接,但是然后我在名册页面上为一个团队运行的美丽汤命令继续抛出索引错误。当我查看超文本标记语言时,似乎我正在编写的命令应该工作,但当我从美丽的汤中打印页面源时,我在Chrome的开发人员工具中看不到什么。这是JS被用来提供内容的一些实例吗?如果是