
无法让Spark在AWS EMR上使用超过百分之几的资源

我一直试图在集群模式下通过AWS EMR和YARN运行Spark作业,并且没有设置组合导致该作业最多使用可用总资源的百分之几。
val queries = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("input_file.csv")
.rdd
val result = queries.map(q => doSomethingWith(q))
以下是所有节点的典型CPU使用率图表(主节点是从20%开始,然后下降的节点,其他节点都是从节点):
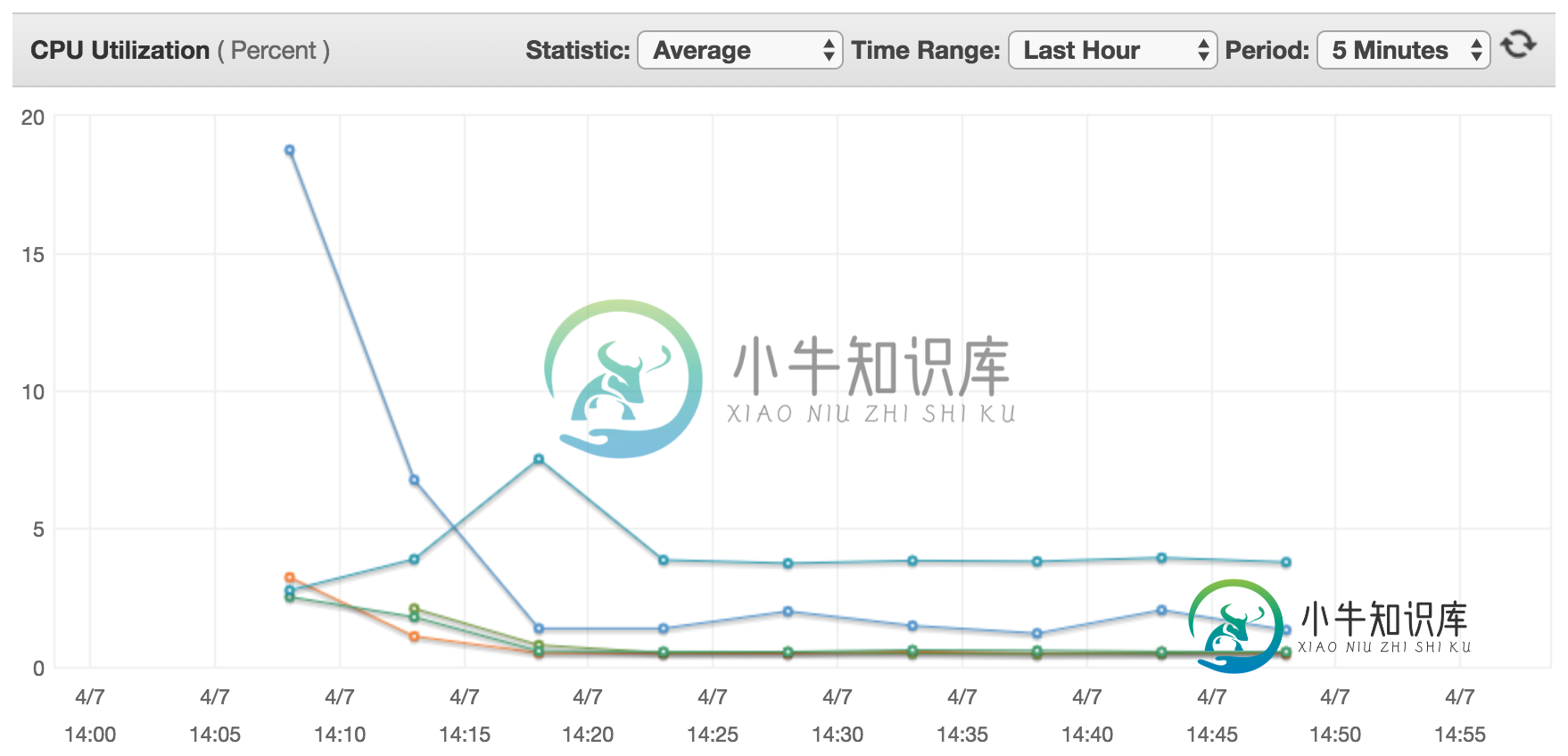
上图是通过以下节点获得的:
Master: 1x r4.2xlarge (8 cores, 61GB RAM)
Slaves: 4x r4.8xlarge (32 cores, 244GB RAM)
使用以下设置运行:
spark-submit --deploy-mode cluster --class Run --master yarn s3://app.jar
Classification Property Value
spark maximizeResourceAllocation true
spark-defaults spark.executor.cores 10
spark-defaults spark.dynamicAllocation.enabled true
spark-defaults spark.executor.instances 12
spark-defaults spark.executor.memory 76g
yarn-site yarn.nodemanager.resource.memory-mb 245760
yarn-site yarn.nodemanager.resource.cpu-vcores 30
我试着遵循所有典型的建议,包括Spark文档中的建议、AWS EMR文档中的建议以及Cloudera博客上这篇文章中的建议。
所有这些文章都一致认为Spark不擅长自动使用资源,并且他们指出你必须告诉他(和YARN)它必须使用多少资源。
到目前为止,我的经验是,无论参数和值是什么,火花/纱线都不在乎,CPU使用率图表总是一样的(与上图类似)。
共有1个答案

听起来您在工作分区的程度上受到限制:如果文件(. gz?)或数据无法拆分,您将无法获得任何并行性。
如果打开了inferSchema,则Spark将读取整个文件一次,以确定模式是什么,然后返回并重新读取;这在S3上(字面上)很昂贵。spark master将在安排任何工作之前进行端到端的工作。
要尝试的一件事:将初始作业变成一个简单的ETL:load(). write()。分区通过(“日期”)。格式(“拼花)。保存(hdfs://),然后使用该组分区文件用于未来的工作。多个文件-
-
我正在尝试为一个简单的任务最大化集群使用。 集群容量为12×m3。xlarge、runnning Spark 1.3.1、Hadoop 2.4、Amazon AMI 3.7 该任务读取文本文件的所有行,并将它们解析为csv。 当我以纱线簇模式spark提交任务时,会得到以下结果之一: 0执行器:作业无限等待,直到我手动杀死它 1个执行器:仅有1台机器工作的情况下使用资源的作业 OOM当我没有为驱动
-
问题内容: 我在Spark上使用Python时遇到问题。我的应用程序具有一些依赖项,例如numpy,pandas,astropy等。我无法使用virtualenv创建具有所有依赖项的环境,因为群集上的节点除HDFS外没有任何公共的挂载点或文件系统。因此,我坚持使用。我将站点程序包的内容打包到一个ZIP文件中,然后提交与option一样的作业(如在Spark executor节点上安装Python依
-
我在Spark上从事一个项目,最近从使用Spark Standalone切换到使用Mesos进行集群管理。现在,我发现自己对在新系统下提交作业时如何分配资源感到困惑。 在独立模式下,我使用的是这样的东西(以下是Cloudera博客文章中的一些建议: 这是一个集群,其中每台机器有16个内核和大约32 GB RAM。 这样做的好处是,我可以很好地控制运行的执行器的数量以及分配给每个执行器的资源。在上面
-
正如标题所预期的,我在向docker上运行的spark集群提交spark作业时遇到了一些问题。 我在scala中写了一个非常简单的火花作业,订阅一个kafka服务器,安排一些数据,并将这些数据存储在一个elastichsearch数据库中。 如果我在我的开发环境(Windows/IntelliJ)中从Ide运行spark作业,那么一切都会完美工作。 然后(我一点也不喜欢java),我按照以下说明添
-
假设我有一个1.2 GB的文件,那么考虑到128 MB的块大小,它将创建10个分区。现在,如果我将其重新分区(或合并)为4个分区,这意味着每个分区肯定会超过128 MB。在这种情况下,每个分区必须容纳320 MB的数据,但块大小是128 MB。我有点糊涂了。这怎么可能?我们如何创建一个大于块大小的分区?
-
这是我的java代码,我在其中使用Apache Spark sql从Hive查询数据。 当我运行此代码时,它抛出java.lang.OutOfMemoryError:超出GC开销限制。如何解决此问题或如何在Spark配置中增加内存。