
Spark Kernel 的最主要目标:提供基础给交互应用程序联系和使用 Apache Spark。
几个主要特性:
-
定义和运行 Spark 任务
-
以类似 Scala REPL 和 Spark Shell 的方式,动态地执行 Scala 代码
-
-
收集数据存储的结果
-
通过 Spark Kernel,将执行结果和数据流返回到你的应用程序。
-
使用 Comm API —— 一个 IPython 协议的抽象 —— 在你的应用程序和 Spark Kernel 之间进行更详细的数据通信和同步。
-
-
脱离 Apache Spark 来主持(Host)和管理你的应用。
-
Spark Kernel 作为向 Apache Spark 集群发出的请求的一个代理。
-
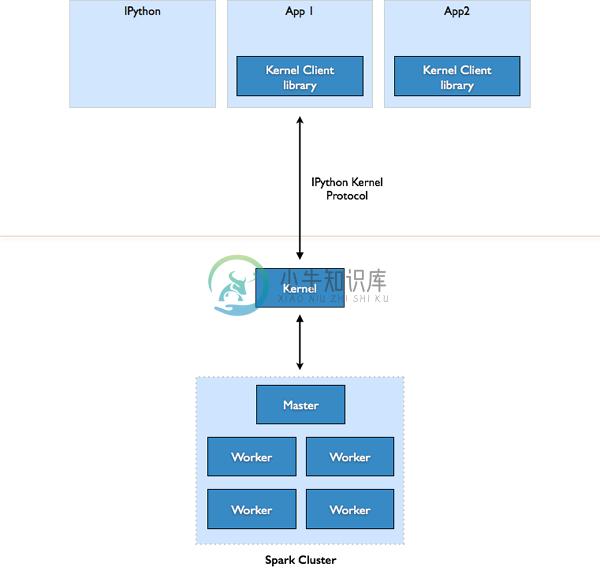
-
编译Spark方式: Spark官网提供了多种利用Maven编译Spark源码的方式,编译之前需要配置所需环境,Maven版本必须是3.3.9或者更高,JDK必须是1.8或者更高。 利用本地Maven编译:需要配置内存区的大小,配置如下:export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m" 利用Spark自带的Maven编译:在解压后的
-
原文:Tuning Spark Tuning Spark Data Serialization 序列化在分布式应用的性能中扮演重要角色,提供两种序列化: Java serialization: By default, Spark serializes objects using Java’s ObjectOutputStream framework, and can work with any c
-
:启动kafka MobaXterm_Personal_8.5.exe D:/Develop/kafka_2.10-0.8.2.1/bin/windows/zookeeper-server-start.bat D:/Develop/kafka_2.10-0.8.2.1/config/zookeeper.properties D:/Develop/kafka_2.10-0.8.2.1/bin/w
-
概念 关联 初始化streamingcontext 离散流 输入dstream dstream的转化 dstream的输出操作 缓存或者持久化 checkpointing 部署应用程序 监控应用程序 性能调优 减少批数据的执行事件 设置正确的批容量 内存调优 容错语义
-
原文:spark configuration Spark Properties 设置参数的3中具体方式 sparkconf bin/spark-submit conf/spark-defaults.conf文件 优先级:SparkConf>spark-submit or spark-shell>spark-defaults.conf file.最终的参数为3者的merge Spark prope
-
Spark Sql简介 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所有Spark
-
编写一个Spark 作业较为容易,但是编写一个高效的 spark 并不是一个容易的事。 本篇主要从暂存的角度 讲解下 ,如何去优化 Spark Job. 参考文章: 【转】Spark性能优化指南——基础篇 https://www.cnblogs.com/hark0623/p/5533803.html spark Streaming 存储级别定义StorageLevel ht
-
[root@node00 sbin]# spark-shell --master local[2] val file = spark.sparkContext.textFile("file:///usr/local/wc.txt") val wordCounts = file.flatMap(line => line.split(",")).map((word => (word,1))).redu
-
一、Spark Env内部组件 ### --- SparkEnv内部组件 ~~~ SparkEnv是spark计算层的基石,不管是 Driver 还是 Executor, ~~~ 都需要依赖SparkEnv来进行计算,它是Spark的执行环境对象, ~~~ 其中包括与众多Executor执行相关的对象。 ~~~ Spark 对任务的计算都依托于 Executor
-
编译安装 Local模式 [root@node00 java]# spark-shell --master local[2] http://192.168.106.100:4040/jobs/ Standalone模式 cp conf/spark-env.sh.template spark-env.sh vi spark-env.sh SPARK_MASTER_HOST=localhost SPA
-
前言:要学习spark程序开发,建议先学习spark-shell交互式学习,加深对spark程序开发的理解。spark-shell提供了一种学习API的简单方式,以及一个能够进行交互式分析数据的强大工具,可以使用scala编写(scala运行与Java虚拟机可以使用现有的Java库)或使用Python编写。 1.启动spark-shell spark-shell的本质是在后台调用了spar
-
转自:https://my.oschina.net/cjun/blog/509247 一、命令 注意./BnmsKpiCal-0.0.1.jar包一定要放在最后面,要不然jar包后面的参数不会生效 1.向spark standalone以client方式提交job。 ./spark-submit --master spark://hadoop3:7077 --deploy-mode client
-
我正在使用Spring Security 4.0.1,并希望使用多个身份验证提供程序使用基于Java的配置进行身份验证。如何指定提供程序顺序? 我希望使用AuthenticationManagerBuilder,因为这就是<code>WebSecurityConfigurerAdapter。configureGlobal()公开,但我看不到任何指定顺序的方法。我需要手动创建ProviderMana
-
我已经创建了身份提供程序,并且从浏览器中它工作正常。 参考:密钥斗篷身份提供程序后代理登录抛出错误 从浏览器,我可以使用外部IDP登录,如果外部IDP用户不在keycloak中,它会在keyclock中创建,这绝对没问题,并重定向到仪表板。 但我的问题是,我们如何用keycloak rest api实现这个流程? 是否有任何api用于使用外部IDP登录,并将获得外部IDP的令牌以及密钥斗篷的令牌?
-
本文向大家介绍F# 使用CSV类型提供程序,包括了F# 使用CSV类型提供程序的使用技巧和注意事项,需要的朋友参考一下 示例 给定以下CSV文件: 您可以使用以下脚本读取数据:
-
我正在尝试使用pact来验证spring boot微服务。我已经从consumer生成了pact文件,并在provider端使用pact Broker验证了它。 我有另一个用例,在根据实际的服务响应验证pact文件之前,我需要执行一些代码。我读过关于状态改变URL和状态改变与闭包来实现它,但没有得到一个如何实现这一点的例子。有人能帮忙吗? 如果这个客户不存在,那么我将需要通过读取pact文件中的更
-
我已经在文件中添加了所有相关build.gradle依赖项。尽管如此,当我尝试运行调用SOAP服务时,还是会出现以下错误。共享依赖项部分和错误详细信息。使用Java11。网上已经有很多答案,但似乎都不起作用。任何帮助/建议将是值得赞赏的。 低于错误跟踪
-
下面是我的app.js文件 下面是我的状态文件 我有一个模板,我想从那里导航到下一个状态 但是只要我点击这个锚标签,它就会把我导航回主页。(不去我打算去的州)。主要问题是URL(我猜)任何帮助都会很感激。
-
问题内容: 我试图通过遵循Hibernate EntityManager 文档中的信息来建立一个简单的jpa 2.0项目。我已经花了几个小时了,但是无论我做什么,当我尝试创建EntityManagerFactory时总是会遇到此异常: 关于此异常,我发现了很多类似的问题,但是没有能够解决的解决方案。我在这里做错了什么? 目录结构 我的 persistence.xml 我的 pom.xml User
-
hybris为面值提供了Solr Sort属性。我可以在HMC中看到每个solr项属性,我们可以设置它的排序行为。 我想用弹劾来设定这种类型。有一个属性(字符串类型),它保存着所选提供者的值,因为我必须在Impex中提供字符串类型,这样它才能工作。 请帮忙。