《神策数据》专题
-
帮助Neuroph神经网络
问题内容: 对于我的研究生研究,我正在创建一个训练识别图像的神经网络。就像许多示例一样,我要比仅对RGB值进行栅格化,下采样并将其发送到网络的输入要复杂得多。实际上,我使用了100多个经过独立训练的神经网络来检测特征,例如线条,阴影图案等。更像是人眼,到目前为止,它的效果非常好!问题是我有很多训练数据。我向它展示了汽车的100多个示例。然后是一个人的100个例子。然后是100多只狗的样子,等等。这
-
 TensorFlow递归神经网络
TensorFlow递归神经网络主要内容:使用TensorFlow实现递归神经网络递归神经网络是一种面向深度学习的算法,遵循顺序方法。在神经网络中,我们总是假设每个输入和输出都独立于所有其他层。这些类型的神经网络称为循环,因为它们以顺序方式执行数学计算。 考虑以下步骤来训练递归神经网络 - 第1步 - 从数据集输入特定示例。 第2步 - 网络将举例并使用随机初始化变量计算一些计算。 第3步 - 然后计算预测结果。 第4步 - 生成的实际结果与期望值的比较将产生错误。 第5步 -
-
 TensorFlow卷积神经网络
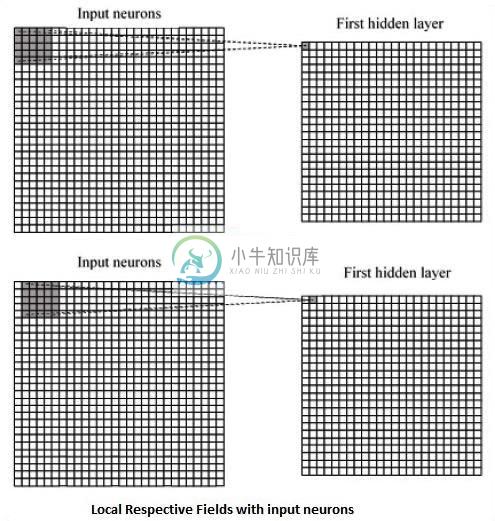
TensorFlow卷积神经网络在了解了机器学习概念之后,现在可以将注意力转移到深度学习概念上。深度学习是机器学习的一个分支。深度学习实现的示例包括图像识别和语音识别等应用。 以下是两种重要的深度神经网络 - 卷积神经网络 递归神经网络 在本章中,我们将重点介绍CNN - 卷积神经网络。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。CNN与其他普通神经网络之间的主要区别在于
-
 PyTorch递归神经网络
PyTorch递归神经网络深度神经网络具有独特的功能,可以帮助机器学习突破自然语言的过程。 据观察,这些模型中的大多数将语言视为单词或字符的平坦序列,并使用一种称为递归神经网络或RNN的模型。 许多研究人员得出的结论是,对于短语的分层树,语言最容易被理解。 此类型包含在考虑特定结构的递归神经网络中。 PyTorch有一个特定的功能,有助于使这些复杂的自然语言处理模型更容易。 它是一个功能齐全的框架,适用于各种深度学习,并为
-
 PyTorch递归神经网络
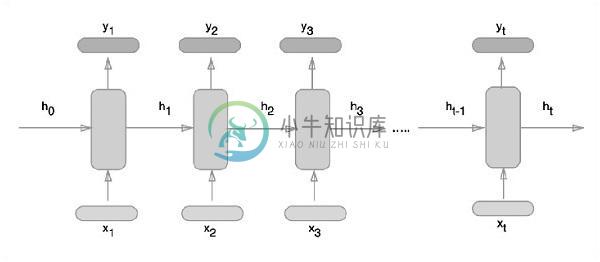
PyTorch递归神经网络递归神经网络是一种遵循顺序方法的深度学习导向算法。在神经网络中,我们总是假设每个输入和输出都独立于所有其他层。这些类型的神经网络被称为循环,因为它们以顺序方式执行数学计算,完成一个接一个的任务。 下图说明了循环神经网络的完整方法和工作 - 在上图中,,,和是包括一些隐藏输入值的输入,即输出的相应输出的,和。现在将专注于实现PyTorch,以在递归神经网络的帮助下创建正弦波。 在训练期间,将遵循模型
-
 PyTorch卷积神经网络
PyTorch卷积神经网络主要内容:卷积神经网络深度学习是机器学习的一个分支,它是近几十年来研究人员突破的关键步骤。深度学习实现的示例包括图像识别和语音识别等应用。 下面给出了两种重要的深度神经网络 - 卷积神经网络 递归神经网络。 在本章中,我们将关注第一种类型,即卷积神经网络(CNN)。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。 CNN与任何其他普通神经网络之间的主要区别在于CNN
-
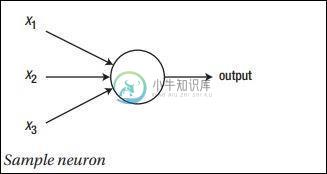 PyTorch神经网络基础
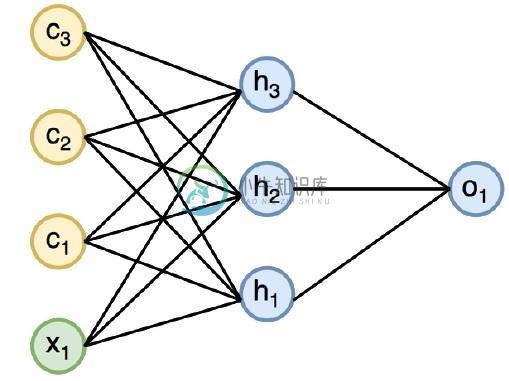
PyTorch神经网络基础神经网络的主要原理包括一系列基本元素,即人工神经元或感知器。它包括几个基本输入,如:x1,x2 …… .. xn,如果总和大于激活潜在量,则产生二进制输出。 样本神经元的示意图如下所述 - 产生的输出可以认为是具有激活潜在量或偏差加权和。 典型的神经网络架构如下所述 - 输入和输出之间的层称为隐藏层,层之间的连接密度和类型是配置。例如,完全连接的配置使层L的所有神经元连接到的神经元。对于更明显的定
-
ClassNotFoundException神奇地未选中
stacktrace示例(已消毒):
-
Maven:丢失的神器presto
我想在pom.xml中添加一个新的依赖项。eclipse显示错误:“Missing artifact presto:presto-jdbc:jar:0.93”我试图强制更新快照。没办法。 groupId、artifactId是任意命名的吗?如何解决这个问题?(Eclipse中Maven中没有更新依赖项。)
-
RestEasy,JBoss Seam神秘异常
我在一个JBoss Seam应用程序中使用RestEasy,我得到了一个奇怪的异常,这个异常信息不是很丰富。我的Seam 2.2.2.ga应用程序中有以下罐子: jaxrs-api-2.2.0.ga.jar resteasy-jaxrs-2.2.0.ga.jar jboss-seam-resteasy-2.2.0.ga.jar
-
Deeplearning4J-神经网络结构
在过去的几天里,我开始使用deeplearning4j库,我遇到了一个问题。 我的测试和输入数据由25个二进制值组成。训练集包含40行。网络有4个输出值。我的目标是训练网络有尽可能少的错误。 我的神经网络配置: 我会非常感激任何帮助。问候,
-
神经网络异或-python
我已经实现了下面的神经网络来解决Python中的异或问题。我的神经网络由3个神经元的输入层、1个2个神经元的隐层和1个神经元的输出层组成。我使用Sigmoid函数作为隐藏层和输出层的激活函数: backpropogation似乎是正确的,但我一直得到这个错误,所有的值都变成了“nan”,输出: 你能帮我解决这个问题吗?谢谢你。
-
2.8 递归神经网络
介绍 可以在 this great article 查看循环神经网络(RNN)以及 LSTM 的介绍。 语言模型 此教程将展示如何在高难度的语言模型中训练循环神经网络。该问题的目标是获得一个能确定语句概率的概率模型。为了做到这一点,通过之前已经给出的词语来预测后面的词语。我们将使用 PTB(Penn Tree Bank) 数据集,这是一种常用来衡量模型的基准,同时它比较小而且训练起来相对快速。 语
-
2.6 卷积神经网络
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组32x32RGB的图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Krizhev
-
全连接神经网络
辅助阅读:TensorFlow中文社区教程 - 英文官方教程 代码见:full_connect.py Linear Model 加载lesson 1中的数据集 将Data降维成一维,将label映射为one-hot encoding def reformat(dataset, labels): dataset = dataset.reshape((-1, image_size * imag