《神策数据》专题
-
Drools基于数据的策略服务器规则引擎
这是我的用例。我们正在尝试使用Drools实现策略服务器。可能有几十万(~200K)条规则,都是基于数据驱动的。一些示例规则: 注意:我在这里只使用了4个参数,但在任何给定的规则中最多可以有20个参数 策略#1和策略#2看起来简单明了。然而,策略#3很棘手。策略#3的最后一个条件(BORN\u STATE\u supporting=TRUE)表示策略上的状态是“包含的”,这意味着,如果规则匹配,结
-
6. 大规模计算的策略: 更大量的数据
校验者: @文谊 翻译者: @ゞFingヤ 对于一些应用程序,需要被处理的样本数量,特征数量(或两者)和/或速度这些对传统的方法而言非常具有挑战性。在这些情况下,scikit-learn 有许多你值得考虑的选项可以使你的系统规模化。 6.1. 使用外核学习实例进行拓展 外核(或者称作 “外部存储器”)学习是一种用于学习那些无法装进计算机主存储(RAM)的数据的技术。 这里描述了一种为了实现这一目的
-
 【字节跳动】【番茄小说】数据策略工程师
【字节跳动】【番茄小说】数据策略工程师字节跳动 字节的面试算是体验最好的,泪目了。 投递2024-02-27 内推投递。 番茄小说,数据策略工程师。 一面2024-03-01 1小时30分 自我介绍 看了你的博客,感觉你对技术有追求(大概是这个意思)。你一般怎么样去学习新的知识? 目前有哪些正在学习的东西? 介绍项目1。 4.1. 介绍数据、模型、介绍LRP的流程。 4.2. 是否有除了GNN外提取特征的方法(在你们的数据上)。 介绍
-
神经网络中的哪些层使用激活函数?
神经网络的输入层使用激活函数,还是仅仅是隐藏层和输出层?
-
神经网络:为什么我们需要激活函数?
我试着运行一个没有任何激活函数的简单神经网络,并且网络不会收敛。我正在使用MSE成本函数进行MNIST分类。 然而,如果我将校正线性激活函数应用于隐藏层(输出=max(0,x),其中x是加权和),那么它会很好地收敛。 为什么消除前一层的负面输出有助于学习?
-
神经网络中的线性函数输出值很大
我正在对虹膜数据集进行回归以预测其类型。我已经成功地使用相同的数据和相同的神经网络进行了分类。对于分类,我在所有层中都使用tanh作为激活函数。但是对于回归,我在隐藏层使用tanh函数,在输出层使用恒等式函数。 数据集是这样的。这里,前4列是功能,最后一列包含目标值。数据集中有150条这样的记录。 在每个纪元之后,预测值呈指数级增长。并且,在50个纪元内,代码给出INF或-INF作为输出。代替恒等
-
带有警告'100'的CheckStyle是一个神奇的数字
在我的代码中,它显示消息100的警告是一个神奇的数字。请参阅以下代码, 我在这里读到了什么是神奇的数字,为什么它不好?但我怀疑通过创建静态变量来声明100会占用更多空间,因为我在一个地方使用它。这是解决这个问题的正确方法吗? 有什么建议吗?
-
第一章 使用神经网络识别手写数字
人类视觉系统是世界上众多奇迹之一。看看下面的手写数字序列: 大多数人毫不费力就能够认出这些数字为 504192. 这么容易反而让人觉着迷惑了。在人类的每个脑半球中,有着一个初级视觉皮层,常称为 V1,包含 1 亿 4 千万个神经元及数百亿条神经元间的连接。但是人类视觉不是就只有 V1,还包括整个视觉皮层——V2、V3、V4 和 V5——他们逐步地进行更加复杂的图像处理。人类的头脑就是一台超级计算机
-
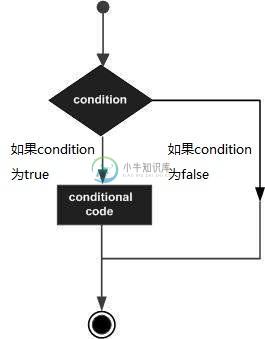 Objective-C决策
Objective-C决策决策结构要求程序员指定一个或多个要由程序评估或测试的条件,以及在条件被确定为真时要执行的一个或多个语句,以及可选的,如果条件要执行的其他语句 被认定是假的。 以下是大多数编程语言中的典型决策结构的一般形式 - Objective-C编程语言将任何非零和非假定为,如果它为零或,则将其假定为。 Objective-C编程语言提供以下类型的决策制定语句。 单击以下链接查看其详细信息 - 编号 语句 描述
-
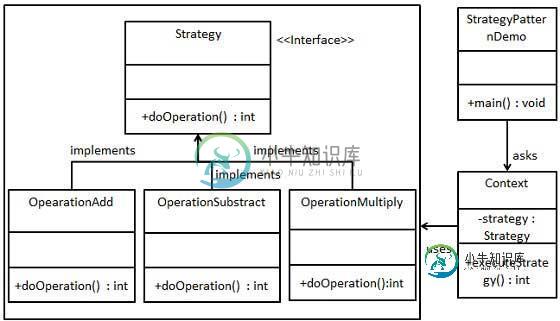 策略模式
策略模式主要内容:介绍,实现,Strategy.java,OperationAdd.java,OperationSubtract.java,OperationMultiply.java,Context.java,StrategyPatternDemo.java在策略模式(Strategy Pattern)中,一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。 在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 contex
-
隐私政策
引言 小牛知识库(以下或称“我们”)非常重视您的隐私保护,您在使用我们的业务平台(xnip.cn)的产品和服务时,我们可能会收集和使用您的相关信息。我们希望通过本《隐私政策》向您说明,我们如何收集、使用、存储及共享您的个人信息,以及您如何访问、更新、控制和保护您的个人信息。 本《隐私政策》与您使用我们的服务关系紧密,希望您仔细阅读并理解,做出您认为适当的选择。您使用或继续使用我们的服务,即意味着您
-
测试策略
Ansible Playbooks 的集成测试 很多时候, 人们问, “我怎样才能最好的将 Ansible playbooks 和测试结合在一起?” 这有很多选择. Ansible 的设计实际上是一个”fail-fast”有序系统, 因此它可以很容易地嵌入到 Ansible playbooks. 在这一章节, 我们将讨论基础设施的集成测试及合适的测试等级. Note 这是一个关于测试你部署应用程序
-
1.18 决策树
接下来就要讲决策树了,这是一类很简单但很灵活的算法。首先要考虑决策树所具有的非线性/基于区域(region-based)的本质,然后要定义和对比基于区域算则的损失函数,最后总结一下这类方法的具体优势和不足。讲完了这些基本内容之后,接下来再讲解通过决策树而实现的各种集成学习方法,这些技术很适合这些场景。 1 非线性(Non-linearity) 决策树是我们要讲到的第一种内在非线性的机器学习技术(i
-
ElementTree Iterparse策略
问题内容: 我必须处理足够大(最大1GB)的xml文档,并使用python解析它们。我正在使用iterparse()函数(SAX样式解析)。 我关注的是以下内容,假设您有一个像这样的xml 问题是,当然知道我何时获得姓氏(如辛普森一家)以及何时获得该家庭成员之一的姓名(例如荷马) 到目前为止,我一直在使用“开关”,它会告诉我是否在“成员”标签中,代码看起来像这样 这很好,因为输出是 我担心的是,在
-
骆驼政策
我有一条小路线,我想使用自定义的重新传递策略来重复向endpoint发送消息,但这种行为非常奇怪。看起来,重新交付政策只是在重复一个错误。我试图将所有交换发送到路由的开头,但策略不起作用,因为每次都在创建: 我做错了什么?当错误发生时,我想以间隔重复我的请求。我的骆驼版本是2.6 日志: