《神策数据》专题
-
2.6 卷积神经网络
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组32x32RGB的图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Krizhev
-
全连接神经网络
辅助阅读:TensorFlow中文社区教程 - 英文官方教程 代码见:full_connect.py Linear Model 加载lesson 1中的数据集 将Data降维成一维,将label映射为one-hot encoding def reformat(dataset, labels): dataset = dataset.reshape((-1, image_size * imag
-
卷积神经网络(LeNet)
在“多层感知机的从零开始实现”一节里我们构造了一个含单隐藏层的多层感知机模型来对Fashion-MNIST数据集中的图像进行分类。每张图像高和宽均是28像素。我们将图像中的像素逐行展开,得到长度为784的向量,并输入进全连接层中。然而,这种分类方法有一定的局限性。 图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。 对于大尺寸的输入图像,使用全连接层容易造成模型过大
-
 一次神奇的经历
一次神奇的经历英威腾: 前天晚上24点投的简历 第二天早上十点电话来了加微信 下午2电话人事面 4点专业面 6点oc 待遇也还行,对我这学历很友好了 主要是工作内容是我喜欢的,我也打算签了 辛辛苦苦秋招忙了近俩月,不如一晚上来的痛快 哈哈哈哈 专业面: 1、唠家常 2、英语自我介绍及简单英语对话 3、介绍项目并围绕项目提问知识点(超基础) 4、围绕岗位聊了一堆 风评也不卷,太走运了😙😙😙
-
 神奇的腾讯一面
神奇的腾讯一面面的后台开发,又被写go的捞了,腾讯的后台开发是全面转go了吗,不晓得了 20分钟就结束了,以为是kpi面,竟然过了。 经典八股 进程线程协程区别 tls握手 谈谈http2.0 面试官是懂cpp的,但没问cpp就离谱
-
 神玥软件测试岗
神玥软件测试岗boss上投的,hr给你介绍公司 薪资6/6.5/7,7k西安封顶 hr电话跟你沟通确认面试时间,线下面试,两轮复试 (面试包含笔试) 笔试部分: 上来先给你三页题 数据库sql,测试基本知识,设计测试用例 问你工作中走的测试流程,接口测试的请求方式 面试部分: 还是要求有代码基础,jmeter压测会详细问 Postman会问你怎么根据上个接口返回测下个接口 sql语句问了分组和排序等 面试1-2
-
神经网路中使用relu函数要好过tanh和sigmoid函数?
本文向大家介绍神经网路中使用relu函数要好过tanh和sigmoid函数?相关面试题,主要包含被问及神经网路中使用relu函数要好过tanh和sigmoid函数?时的应答技巧和注意事项,需要的朋友参考一下 1.使用sigmoid函数,算激活函数时(指数运算),计算量大,反向传播误差梯度时,求导涉及除法和指数运算,计算量相对较大,而采用relu激活函数,整个过程的计算量节省很多 2.对于深层网络,
-
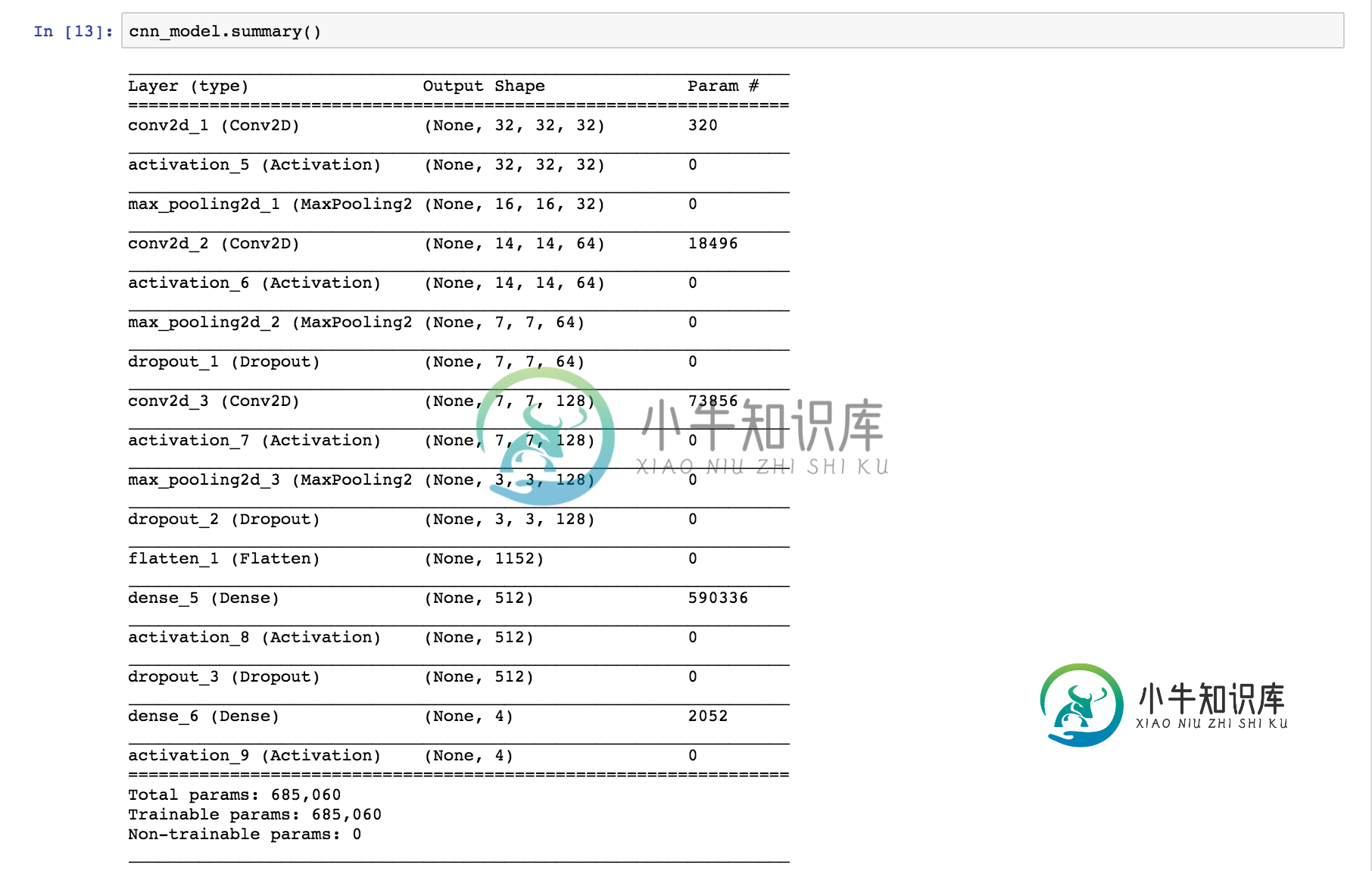 如何计算卷积神经网络中的参数总数?[重复]
如何计算卷积神经网络中的参数总数?[重复]如何计算CNN网络中的参数总数 代码如下: 如何获取320、18496、73856、590336、2052,有人能解释一下吗?
-
 网易雷火数值策划笔试题
网易雷火数值策划笔试题毫无建设性意义,也没办法刷题准备,单纯给游戏爱好者们看个乐,就当秋招放松下好了 1.游戏常识单选 1)魔兽世界职业和技能消耗资源对应哪个不正确? 战士 怒气 类似的选项 2)原神哪个动作一般情况下做不出来? 我选的下落重击,没玩过原神只玩过塞尔达 3)哪个角色用的武器是刀剑? 都不太熟悉 不记得了 4)哪个梗和游戏对应不上? 犹豫就会败北、赞美太阳、猛男捡树枝(游戏名小森生活,选了)、应急食品 5
-
 数策股份|软件测试|一面6.13
数策股份|软件测试|一面6.13岗位是跟车企算法大模型有关的,视频一面。(33分钟) btw面试官是一个xsg哈哈哈,许愿一下二面~ 1.实习做的项目具体是做什么,解决了什么问题? 2.用例是怎么写的?写什么样的用例?是标准确的格式么?(针对项目具体提问) 3.输出的用例是用来干嘛的? 4.你在项目里面主要做什么? 5.你这个里面我看你写到一些SQL,你有需要用到一些 SQL 吗? 6.我看你有一个CSDN,然后你的意思你这个里
-
 冰川网络数值策划hr面挂。。
冰川网络数值策划hr面挂。。hr面过了两周通知挂了,感觉专业面和hr面都聊的不错,难道是匹配度不够吗。。
-
前馈神经网络和递归神经网络的根本区别?
我经常读到,前馈和递归神经网络(RNNs)之间存在着根本的区别,这是由于前馈网络缺乏内部状态和短期记忆。乍一看,我觉得这似乎有理。 然而,当学习一个递归神经网络的反向传播通过时间算法时,递归网络转化为等价的前馈网络,如果我理解正确的话。 这就意味着,事实上没有根本的区别。为什么RNN在某些任务(图像识别、时间序列预测等)中比深度前馈网络表现得更好?
-
4. 策略 - 4.3 常用的策略事件
OnStrategyStart – 在策略启动时调用,在第一笔行情到达之前 OnStrategyStop – 在策略结束时调用,在最后一笔行情之后 OnBarOpen – 在Bar行情最前沿调用(如,在日线数据开盘时买入) OnBar – 在所有行情的后沿调用(如,在日线数据收盘时买入) OnPositionOpened – 当一个新的交易开仓确认后调用 OnPositionChanged – 当
-
4. 策略 - 4.1 开始第一个策略
Solution:解决方案 Project:项目 一个解决方案下可以有多个项目,但是只有一个启动项 双击cs文件可以打开编辑代码 新建策略 在菜单栏File->New->Solution,新建一个解决方案 选择新建SmartQuant Instrument Strategy Solution模式的解决方案 Solution的类型 说明 SmartQuant Instrument Strategy
-
混合参数策略-仅使用命名、位置或JPA顺序策略之一
我正在从Oracle数据库调用函数,并面临此异常: 组织。冬眠发动机查询ParameterRecognitionException:混合参数策略-仅使用命名、位置或JPA顺序策略之一 这是我的用户。java实体。 这就是我从服务类调用这个函数的方式。 那么,为了调用返回字符串的Oracle函数,需要做哪些更改。 谢谢。如果需要更多信息,请告诉我。