《神策数据》专题
-
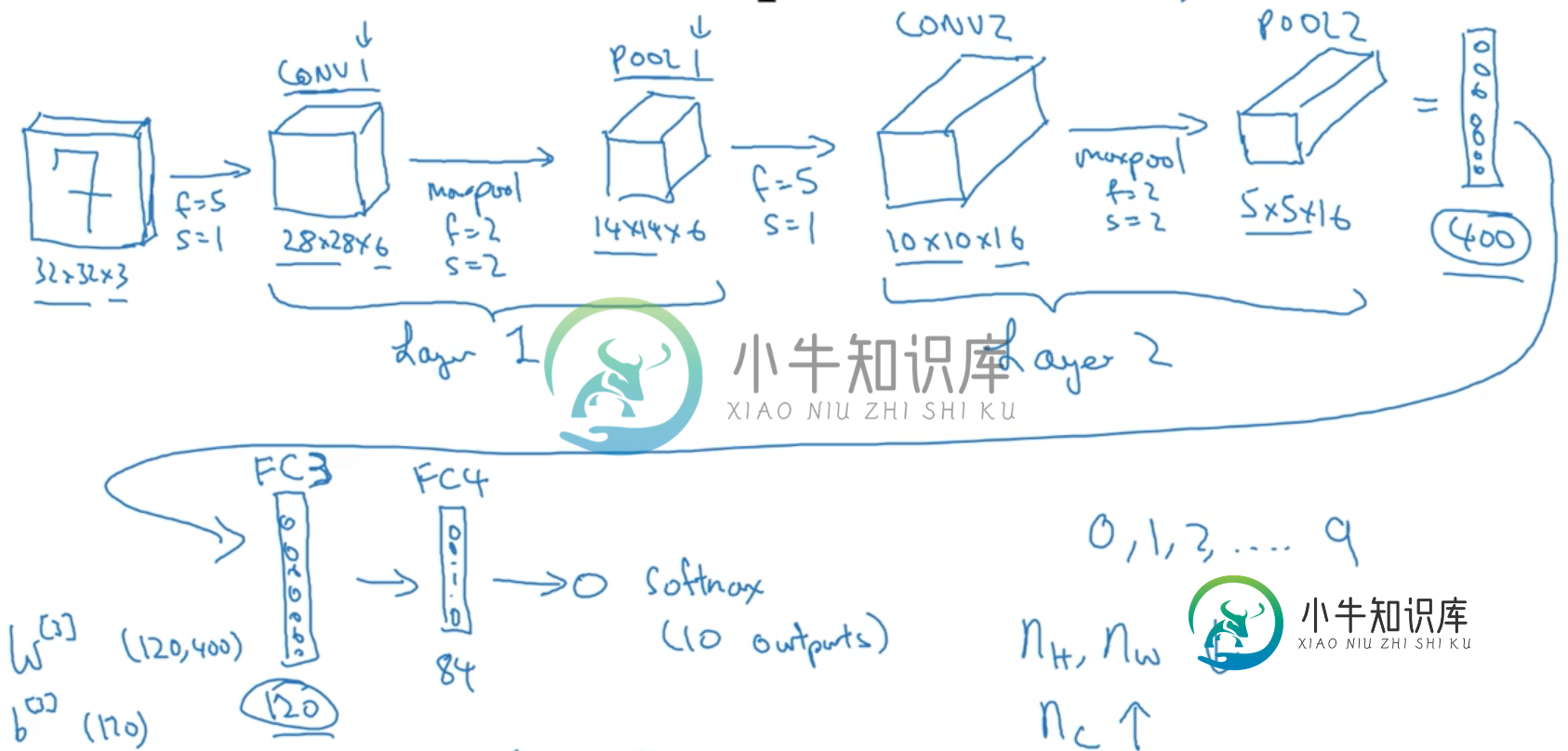 卷积神经网络中参数个数的计算
卷积神经网络中参数个数的计算我是CNN研究的新手,我从看Andrew'NG的课程开始。有一个例子我不明白: 他是如何计算#参数值的?
-
卷积神经网络特征图及参数总数
假设我有一幅尺寸为125*125的RGB图像,我使用了10个尺寸为5*5、步长为3的过滤器,那么这一层的特征图是什么?特征图的参数总数是多少?10*((125-5)/3)1=(41*41*10)(过滤器数量)但RGB图像和灰度图像之间的区别是什么?因此,对于RGB图像,它应该是41*41*30(过滤器数量*输入图像通道数量)?对于参数总数:5*5*3*10=750?
-
kafka 有几种数据保留的策略?
本文向大家介绍kafka 有几种数据保留的策略?相关面试题,主要包含被问及kafka 有几种数据保留的策略?时的应答技巧和注意事项,需要的朋友参考一下 kafka 有两种数据保存策略:按照过期时间保留和按照存储的消息大小保留。
-
java - 热点数据筛选优化策略?
热点数据怎么筛选? 如题,存在这样一个场景,上游系统和我们系统之间存在通知+定时轮询的机制去同步某个账户的流水。其中定时轮询的批量高频率执行,因为里面大部分账户做同步的时候都是没有任何数据的,上游系统就骂人了,由此打算从中抽取一些热点数据做同步。 现在的想法是在得到通知的时候维持一个redis缓存,定时轮询时看缓存中是否存在数据,存在才同步否则不同步,然后再做一个慢一点的全量同步定时。具体实现是在
-
 b站数据策略实习(OC但拒)
b站数据策略实习(OC但拒)4.18 hr发邮件约一面 4.21 一面 4.23 hr发邮件约二面 4.24 二面 4.25 hr通知面试已过,发offer bg:本硕华五,天坑专业,无实习经历,几场数模比赛水奖 b站真的是我很心仪的一家实习公司,整个面试流程也十分十分愉快,只是后来再三决定,还是放弃了offer去了字节。 一面:技术面,一位面试官,牛客网,1h(30min面试,30min的sql笔试) 面试 1. 自我介绍
-
来自数据框的神经网络LSTM输入形状
问题内容: 我正在尝试使用Keras实施LSTM。 我知道Keras中的LSTM需要3D张量与形状作为输入。但是,我不能完全确定输入在我的情况下的样子,因为我对每个输入只有一个观察样本,而不是多个样本,即。将我的每个输入分成长度样本是否更好?对我而言,大约有几百万个观测值,因此在这种情况下,每个样本应保留多长时间,即我将如何选择? 另外,我是对的,这个张量应该看起来像: 其中M和N如前所述,x对应
-
神经网络:“InverseLayer”
我玩神经网络。我了解卷积层、完全连接层和许多其他东西是如何工作的。我还知道什么是梯度,以及如何训练这样的网络。 框架千层面包含一个称为InverseLayer的层。 InverseLayer类通过应用要反转的层相对于其输入的偏导数,对神经网络的单层执行反转操作。 我不知道这是什么意思,或者我应该在什么时候使用这个层。或者倒置偏导数背后的想法是什么? 非常感谢你
-
连接神经元
连接神经元到慧编程,需要使用到:Micro-USB 数据线、蓝牙或者 Wi-Fi模块。 使用蓝牙模块连接 1. 使用 Micro-USB 数据线将蓝牙模块连接到电脑的 USB 口,如下图所示: 2. 在“设备”下,点击“+”,从设备库中添加神经元,然后点击“连接”。
-
张量流卷积神经网络负维数
我正在制作这个CNN模型 ''' 但这是给我一个错误:-InvalidArgumentError:负尺寸造成的减去2从1'{{nodeconv2d_115/Conv2D}}=Conv2D[T=DT_FLOAT,data_format="NHWC",膨胀=[1,1,1,1],explicit_paddings=[],填充="VALID",步幅=[1,2,2,1],use_cudnn_on_gpu=t
-
使用Keras函数API调整神经网络超参数
我有一个包含两个分支的神经网络。一个分支接受卷积神经网络的输入。另一个分支是一个完全连接的层。我合并这两个分支,然后使用softmax获得输出。我不能使用顺序模型,因为它已被弃用,因此必须使用函数式API。我想调整卷积神经网络分支的超参数。例如,我想弄清楚我应该使用多少卷积层。如果是顺序模型,我会使用for循环,但由于我使用的是函数式API,我真的不能这样做。我已经附加了我的代码。有人能告诉我如何
-
如何计算卷积神经网络的参数个数?
我正在使用千层面为MNIST数据集创建CNN。我将密切关注这个示例:卷积神经网络和Python特征提取。 我目前拥有的CNN架构(不包括任何退出层)是: 这将输出以下图层信息: 并输出可学习参数的数量为217,706 我想知道这个数字是如何计算的?我已经阅读了许多资源,包括这个StackOverflow的问题,但没有一个明确概括了计算。 如果可能,每层可学习参数的计算是否可以泛化? 例如,卷积层:
-
Matlab神经网络到C神经网络的转换
我用newff在Matlab中创建了一个用于手写数字识别的神经网络。 我只是训练它只识别0 输入层有9个神经元,隐层有5个神经元,输出层有1个神经元,共有9个输入。 我的赔率是0.1 我在Matlab中进行了测试,网络运行良好。现在我想用c语言创建这个网络,我编写了代码并复制了所有的权重和偏差(总共146个权重)。但当我将相同的输入数据输入到网络时,输出值不正确。 你们谁能给我指点路吗? 这是我的
-
神经网络中的输入形状和神经元数量可以不同吗?[复制]
在Francois Chollet的《使用Python进行深度学习》一书中,我发现了一段代码,输入形状为784,单位为32? 我想知道他们有什么不同。 下面是确切的代码:
-
及策
及策 及策是一个基于用户行为和用户属性对用户进行精细化运营和再营销的实时分析平台,能够帮助用户最高效解决用户拉新、活跃和再营销转化问题。主要包含App归因分析、App用户运营解决方案、Web用户运营解决方案、微信小程序用户运营解决方案在传统网站分析的基础上更专注于每一个用户的互动行为和其本身属性,深入理解每一个用户并引导其达成转化。最终我们希望结合一系列用户标属性和签体系进行聚类分析依托强大的第一
-
将分类数据传递到Sklearn决策树
问题内容: 关于如何将分类数据编码到Sklearn决策树中,有几篇文章,但是从Sklearn文档中,我们得到了这些。 决策树的一些优点是: (…) 能够处理数字和分类数据。其他技术通常专用于分析仅具有一种类型的变量的数据集。有关更多信息,请参见算法。 但是运行以下脚本 输出以下错误: 我知道在R中可以通过Sklearn传递分类数据,这可能吗? 问题答案: 与接受的答案相反,我更愿意使用Scikit