
Python将匹配数据帧并从列表中指示结果

有了水果列表,我想检查它们是否存在于数据帧中(不管是哪个列),并指明它们。
import pandas as pd
Fruits = ["Avocado", "Blackberry", "Black Sapote", "Fingered Citron", "Crab Apples", "Custard Apple", "Chico Fruit", "Coconut", "Damson", "Elderberry", "Goji Berry", "Grape", "Guava", "Huckleberry"]
data = {'ID': ["488", "14805", "23591", "470995", "56251", "85964", "5268", "322624", "342225", "380689", "480562", "5623"],
'Content' : ["Kalo Beruin", "this is Blackberry", "Khara Beruin", "guava and coconut", "Lapha", "Loha Sura", "Matichak", "Miniket Rice", "Mou Beruin", "Moulata", "oh Goji Berry", "purple Grape"],
'Content_1' : ["Jook-sing noodles", "grape", "Lai fun", "Damson", "Liangpi", "Custard Apple and Crab apples", "Misua", "nana Coconut Berry", "Damson", "Paomo", "Ramen", "Rice vermicelli"]}
df = pd.DataFrame(data)
df = df[['ID', 'Content', 'Content_1']]
s = pd.Series(data['Content'])
s_1 = pd.Series(data['Content_1'])
df["found_content"] = s[s.str.contains('|'.join(Fruits))]
df["found_content_1"] = s_1[s_1.str.contains('|'.join(Fruits))]
writer = pd.ExcelWriter('C:\\TEM\\22522.xlsx')
df.to_excel(writer,'Sheet1', index = False)
writer.save()
这些守则的问题包括:
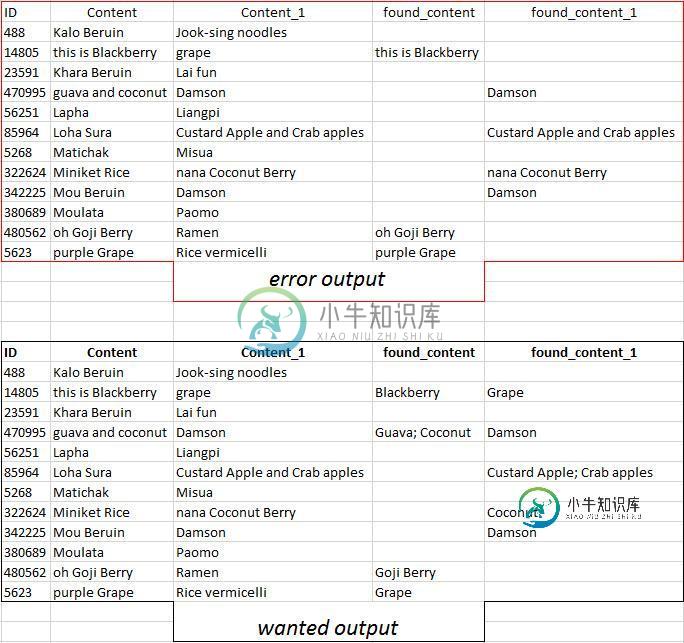
- 它显示的不是水果,而是整个内容。例如,14805行,应仅为“Blackberry”,而不是整个原始内容
我怎样才能做到呢?非常感谢。
这是当前输出和所需输出的屏幕截图。
共有2个答案

也许是这样:
import pandas as pd
Fruits = ["Avocado", "Blackberry", "Black Sapote", "Fingered Citron", "Crab Apples", "Custard Apple", "Chico Fruit", "Coconut", "Damson", "Elderberry", "Goji Berry", "Grape", "Guava", "Huckleberry"]
data = {'ID': ["488", "14805", "23591", "470995", "56251", "85964", "5268", "322624", "342225", "380689", "480562", "5623"],
'Content' : ["Kalo Beruin", "this is Blackberry", "Khara Beruin", "guava and coconut", "Lapha", "Loha Sura", "Matichak", "Miniket Rice", "Mou Beruin", "Moulata", "oh Goji Berry", "purple Grape"],
'Content_1' : ["Jook-sing noodles", "grape", "Lai fun", "Damson", "Liangpi", "Custard Apple and Crab apples", "Misua", "nana Coconut Berry", "Damson", "Paomo", "Ramen", "Rice vermicelli"]}
df = pd.DataFrame(data)
df["found_content"] = df['Content'].str.extract('(?P<Fruits>{})'.format("|".join(Fruits)), expand=True).fillna('')
df["found_content_1"] = df['Content_1'].str.extract('(?P<Fruits>{})'.format("|".join(Fruits)), expand=True).fillna('')
writer = pd.ExcelWriter('filename.xlsx')
df.to_excel(writer,'Sheet1', index = False)
writer.save()

将str.findall与re一起使用。I用于忽略大写/小写,然后通过str.join连接列表:
import re
#\b for word boundary - general use
pat = r'(\b{}\b)'.format('|'.join(Fruits))
df["found_content"] = df['Content'].str.findall(pat, re.I).str.join(';')
df["found_content_1"] = df['Content_1'].str.findall(pat, re.I).str.join(';')
print (df)
ID Content Content_1 found_content \
0 488 Kalo Beruin Jook-sing noodles
1 14805 this is Blackberry grape Blackberry
2 23591 Khara Beruin Lai fun
3 470995 guava and coconut Damson guava;coconut
4 56251 Lapha Liangpi
5 85964 Loha Sura Custard Apple and Crab apples
6 5268 Matichak Misua
7 322624 Miniket Rice nana Coconut Berry
8 342225 Mou Beruin Damson
9 380689 Moulata Paomo
10 480562 oh Goji Berry Ramen Goji Berry
11 5623 purple Grape Rice vermicelli Grape
found_content_1
0
1 grape
2
3 Damson
4
5 Custard Apple;Crab apples
6
7 Coconut
8 Damson
9
10
11
另一个解决方案是使用title代替re。我:
pat = r'(\b{}\b)'.format('|'.join(Fruits))
df["found_content"] = df['Content'].str.title().str.findall(pat).str.join(';')
df["found_content_1"] = df['Content_1'].str.title().str.findall(pat).str.join(';')
print (df)
ID Content Content_1 found_content \
0 488 Kalo Beruin Jook-sing noodles
1 14805 this is Blackberry grape Blackberry
2 23591 Khara Beruin Lai fun
3 470995 guava and coconut Damson Guava;Coconut
4 56251 Lapha Liangpi
5 85964 Loha Sura Custard Apple and Crab apples
6 5268 Matichak Misua
7 322624 Miniket Rice nana Coconut Berry
8 342225 Mou Beruin Damson
9 380689 Moulata Paomo
10 480562 oh Goji Berry Ramen Goji Berry
11 5623 purple Grape Rice vermicelli Grape
found_content_1
0
1 Grape
2
3 Damson
4
5 Custard Apple;Crab Apples
6
7 Coconut
8 Damson
9
10
11
-
我有两个数据帧,一个包含数据,第二个包含代码及其解码值。我想将df1[代码]与df2[代码]匹配,并将df2[值]粘贴在df1中。需要注意的是,我的第二个数据帧包含代码和值一次,基本上是一张代码和值,但在第一个数据帧中,代码是重复的,因此将粘贴的值列应该代表每次代码出现在df1[代码]列中时的值。 我需要: 基本上是从第二个数据帧转换一个数据帧中的代码。
-
我一直试图从摘要列表中提取数据并保留列指示符。 这是一个数据的例子 我希望从每个结果列表中只提取groups ( 5行)和statistics (1行)选项卡,并将它们与列Var 1和Var2的相应值一起放在一个表中。在选项卡组选项卡中,row.names表示用于分析的处理。 我尝试使用扫帚::整洁(它适用于其他结果列表),但此列表分发失败 到目前为止,我已经能够从提取的组及其相关行名称创建表,但
-
我有一个包含100,000行(人)和500列(概率)的数据集,我想用测试概率扫描各列,以找到大于和最接近测试值的列标题(a、b或c ),并将标题记录在新列中。 以数据表为例: 新列将记录“a”(0.1 我最初做它作为一个矩阵,而不是data.table.下面的代码不会工作,但给出了一个想法,它是如何运作的 如何跨 data.table 中的列执行此匹配。我认为我需要使用 来自 的查询。但不确定如何
-
问题内容: 我在IPython中具有以下数据框,其中每一行都是一只股票: 我想应用一个groupby操作,该操作计算“ yearmonth”列中每个日期的所有内容的上限加权平均回报。 这按预期工作: 但是,然后我想将这些值“广播”回原始数据帧中的索引,并将它们保存为日期匹配的常量列。 我意识到这种天真的任务不起作用。但是,将groupby操作的结果分配给父数据帧上新列的“正确” Pandas习惯用
-
我有一个订单数据帧: 我有另一个唯一的菜单项数据帧,它有自己的特定ID: 现在我要匹配元素,并通过在orders数据帧中打印其chat_id来返回其ID
-
我有两个具有经度和纬度值的数据帧,我想从数据帧#2中提取值(例如数据帧#2的第三列),这些值与数据帧1的列匹配...例如,数据帧1有两列(、),数据帧2有三列(、和一些值)...我想在数据帧1中添加第三列,其中的值对应于两个数据帧中两列完全匹配的值,类似于和...在、不匹配的对中,我希望添加,以便第三列(我要添加到数据。帧1)的长度为=。我尝试了merge函数,但在将的两列与的列进行匹配时遇到了困