
如何使用python从列表中读取数据并将特定值索引到Elasticsearch中?

我使用“
paramiko”将PC连接到开发板并执行脚本。然后,我将该脚本的结果保存在一个列表中(输出)。我想提取列表的一些值并将其插入到Elasticsearch中。我已经手动完成了列表的第一个结果。但是如何使其余的值自动化?我需要“正则表达式”吗?请给我一些线索。
谢谢
这是连接到开发板,执行脚本并检索列表=输出的代码的一部分
def main():
ssh = initialize_ssh()
stdin, stdout, stderr = ssh.exec_command('cd coral/tflite/python/examples/classification/Auto_benchmark\n python3 auto_benchmark.py')
output = stdout.readlines()
type(output)
#print(type(output))
print('\n'.join(output))
ssh.close()
清单看起来像这样:
labels: imagenet_labels.txt
Model: efficientnet-edgetpu-S_quant_edgetpu.tflite
Image: img0000.jpg
----INFERENCE TIME----
Note: The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory.
Time: 6.2ms
Results: wall clock
Score: 0.25781
#####################################
labels: imagenet_labels.txt
Model: mobilenet_v1_1.0_224_quant_edgetpu.tflite
Image: img0000.jpg
----INFERENCE TIME----
Note: The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory.
Time: 2.8ms
Results: umbrella
Score: 0.22266
#####################################
Temperature: 35C
这是将数据索引到ELASTICSSARCH中所需的映射
def initialize_mapping_classification(es):
"""
Initialise les mappings
"""
mapping_classification = {
'properties': {
'@timestamp': {'type': 'date'},
'type': 'coralito',
'Model': {'type': 'string'},
'Time': {'type': 'float'},
'Results': {'type': 'string'},
'Score': {'type': 'float'},
'Temperature': {'type': 'float'}
}
}
if not es.indices.exists(CORAL):
es.indices.create(CORAL)
es.indices.put_mapping(body=mapping_classification, doc_type=DOC_TYPE, index=CORAL)
这是我的尝试。我已经根据清单的第一项结果进行了手动操作。我想自动化
if CLASSIFY == 1:
doc = {
'@timestamp': str(datetime.datetime.utcnow().strftime("%Y-%m-%d"'T'"%H:%M:%S")),
'type': 'coralito',
'Model': "efficientnet-edgetpu-S_quant_edgetpu.tflite",
'Time': "6.2 ms",
'Results': "wall clock",
'Score': "0.25781",
'Temperature': "35 C"
}
response = send_data_elasticsearch(CORAL, DOC_TYPE, doc, es)
print(doc)
------------------------------编辑2 ------------------ ---------------------
所以这是使用正则表达式提取感兴趣的值后我的数据的样子
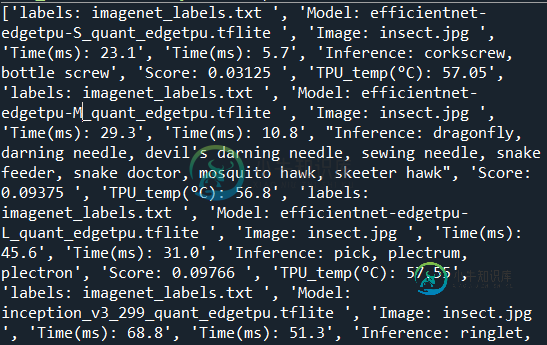
这是我被索引的内容:
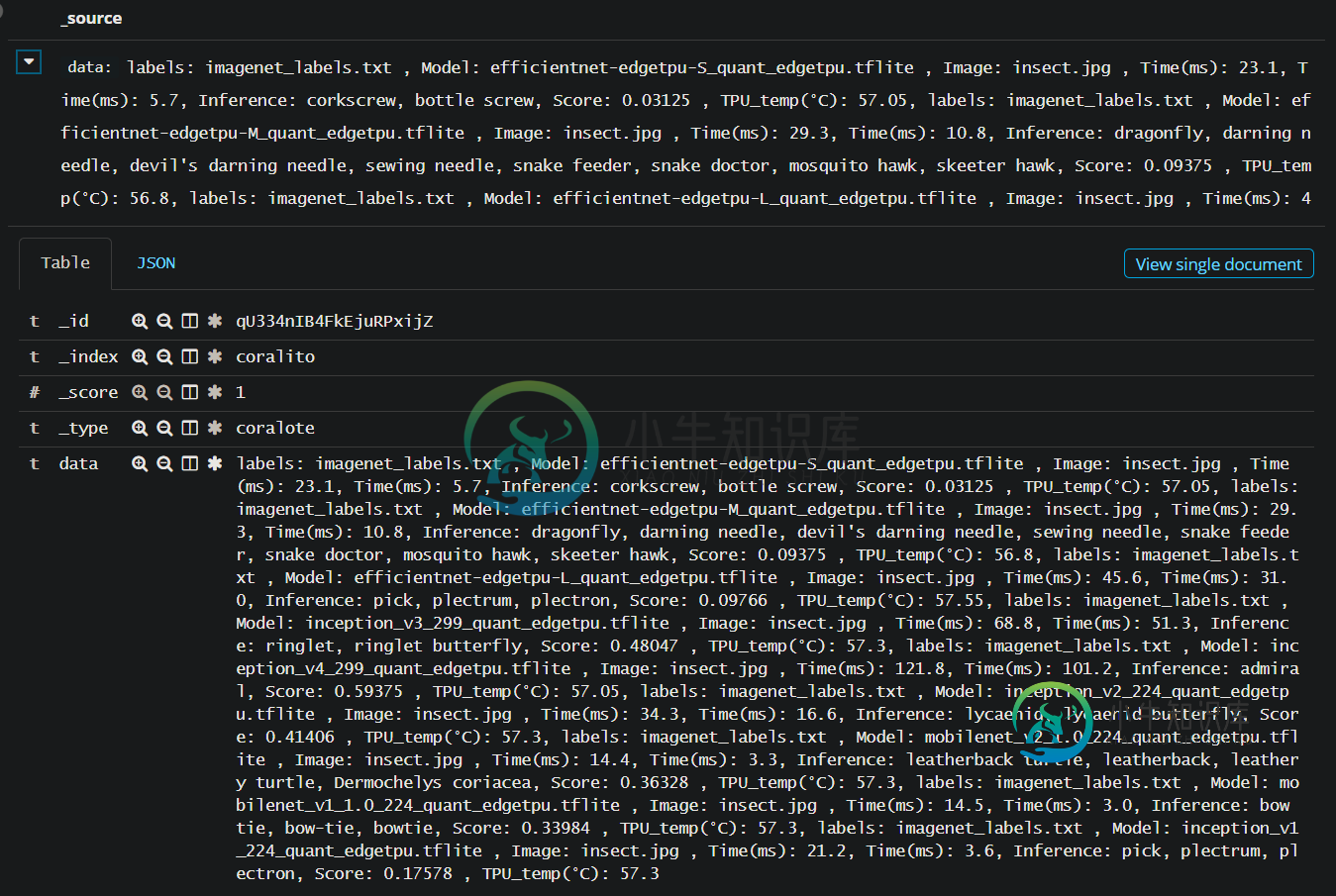
这是我的代码:
import elasticsearch
from elasticsearch import Elasticsearch, helpers
import datetime
import re
data = ['labels: imagenet_labels.txt \n', '\n', 'Model: efficientnet-edgetpu-S_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 23.1\n', 'Time(ms): 5.7\n', '\n', '\n', 'Inference: corkscrew, bottle screw\n', 'Score: 0.03125 \n', '\n', 'TPU_temp(°C): 57.05\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: efficientnet-edgetpu-M_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 29.3\n', 'Time(ms): 10.8\n', '\n', '\n', "Inference: dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk\n", 'Score: 0.09375 \n', '\n', 'TPU_temp(°C): 56.8\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: efficientnet-edgetpu-L_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 45.6\n', 'Time(ms): 31.0\n', '\n', '\n', 'Inference: pick, plectrum, plectron\n', 'Score: 0.09766 \n', '\n', 'TPU_temp(°C): 57.55\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: inception_v3_299_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 68.8\n', 'Time(ms): 51.3\n', '\n', '\n', 'Inference: ringlet, ringlet butterfly\n', 'Score: 0.48047 \n', '\n', 'TPU_temp(°C): 57.3\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: inception_v4_299_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 121.8\n', 'Time(ms): 101.2\n', '\n', '\n', 'Inference: admiral\n', 'Score: 0.59375 \n', '\n', 'TPU_temp(°C): 57.05\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: inception_v2_224_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 34.3\n', 'Time(ms): 16.6\n', '\n', '\n', 'Inference: lycaenid, lycaenid butterfly\n', 'Score: 0.41406 \n', '\n', 'TPU_temp(°C): 57.3\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: mobilenet_v2_1.0_224_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 14.4\n', 'Time(ms): 3.3\n', '\n', '\n', 'Inference: leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea\n', 'Score: 0.36328 \n', '\n', 'TPU_temp(°C): 57.3\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: mobilenet_v1_1.0_224_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 14.5\n', 'Time(ms): 3.0\n', '\n', '\n', 'Inference: bow tie, bow-tie, bowtie\n', 'Score: 0.33984 \n', '\n', 'TPU_temp(°C): 57.3\n', '##################################### \n', '\n', 'labels: imagenet_labels.txt \n', '\n', 'Model: inception_v1_224_quant_edgetpu.tflite \n', '\n', 'Image: insect.jpg \n', '\n', '*The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory*\n', 'Time(ms): 21.2\n', 'Time(ms): 3.6\n', '\n', '\n', 'Inference: pick, plectrum, plectron\n', 'Score: 0.17578 \n', '\n', 'TPU_temp(°C): 57.3\n', '##################################### \n', '\n']
# declare a client instance of the Python Elasticsearch library
client = Elasticsearch("http://localhost:9200")
#using regex
regex = re.compile(r'(\w+)\((.+)\):\s(.*)|(\w+:)\s(.*)')
match_regex = list(filter(regex.match, data))
match = [line.rstrip('\n') for line in match_regex]
#using "bulk"
def yield_docs():
"""
Initialise les mappings
"""
doc_source = {
"data": match
}
# use a yield generator so that the doc data isn't loaded into memory
yield {
"_index": "coralito",
"_type": "coralote",
"_source": doc_source
}
try:
# make the bulk call using 'actions' and get a response
resp = helpers.bulk(
client,
yield_docs()
)
print ("\nhelpers.bulk() RESPONSE:", resp)
print ("RESPONSE TYPE:", type(resp))
except Exception as err:
print("\nhelpers.bulk() ERROR:", err)
-----------------------------编辑3 ------------------- -
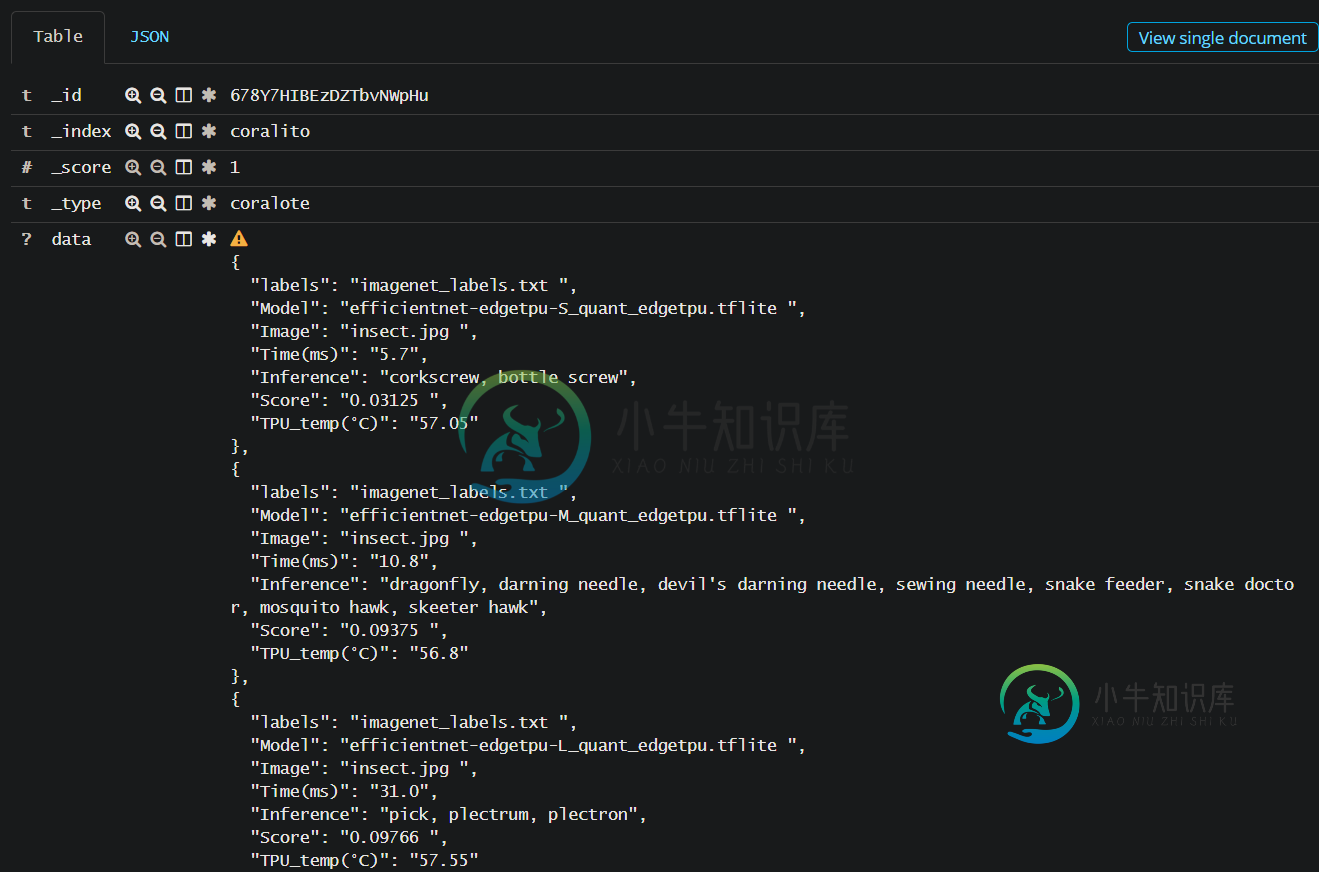
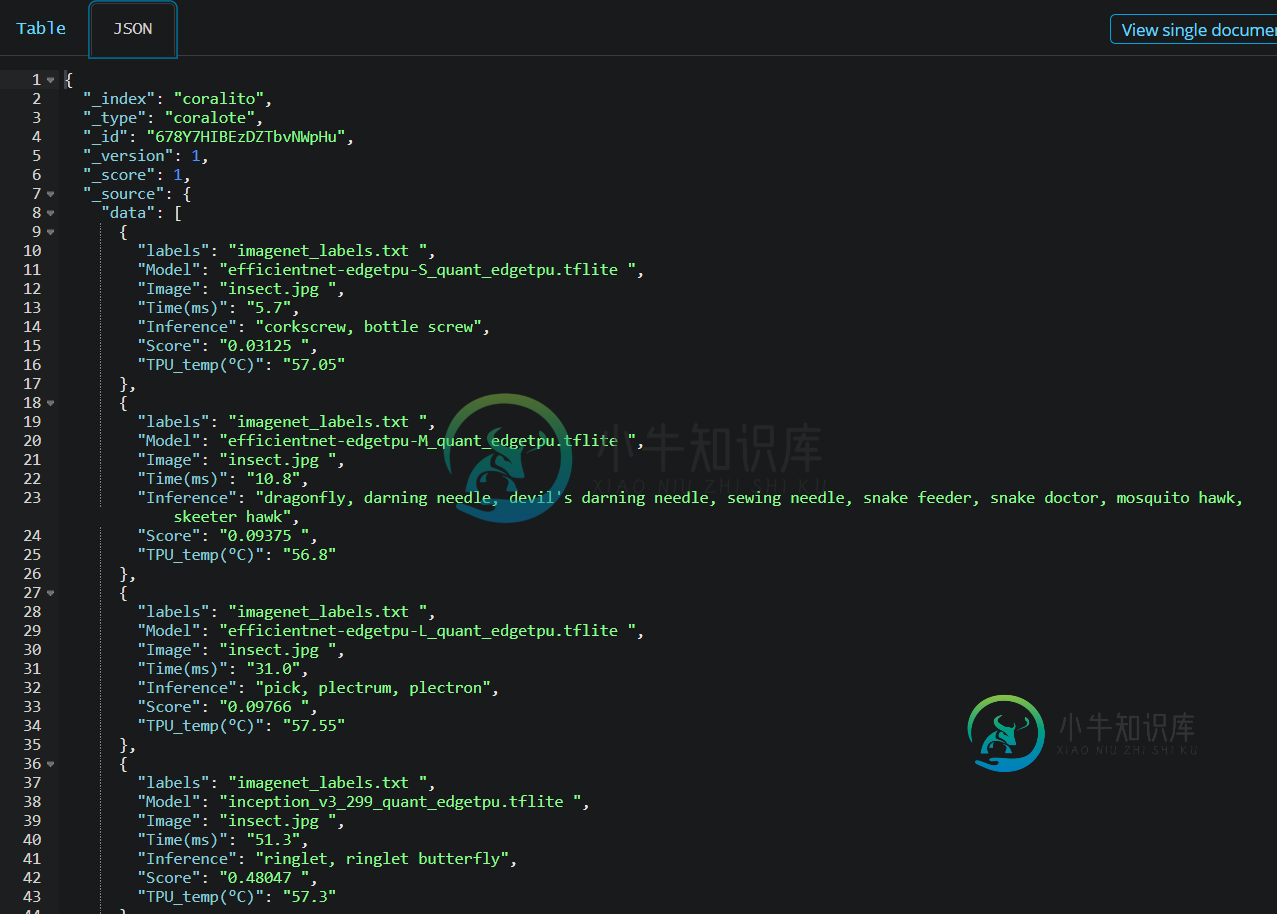
问题答案:
- 删除换行符
- 用通用分隔符分隔文本(
----INFERENCE TIME----我认为这将是一个好的开始) - 提取密钥&使用例如值
r'(\w+:)\s(.*)'或命名回顾后如r'(?<=Note: ).*'等 - 解析数值(时间,分数,温度等)-稍后您会感谢我;)
Model使用关键字数据类型扩展映射-否则点将被标记掉,您会想知道为什么无法搜索完全匹配或对其进行汇总- 准备要同步的对象
Bulk上传到ElasticSearch
-
问题内容: 有什么方法可以简化此代码,以获取提供的某一列的索引以获取特定行的索引吗?在这种情况下,索引将为,因为我要遍历第一列直到找到“ A”。感觉应该对此有一个linq解决方案,但我无法弄清楚。 问题答案: 如果使用DataTableExtensions.AsEnumerable()方法,则可以使用LINQ查询您的DataTable。然后,您可以用来确定给定谓词的索引:
-
我有一个从数据库中提取数据的表。在同一张桌子里,我有两个按钮。通过按任意一个按钮,我希望获得所有特定的列数据。我试过几种方法。请参阅下面的代码。 生成上表HTML和PHP: JavaScript:每个警报都是我尝试的不同方法,但没有成功
-
问题内容: 如果您在python中有一个列表,并且想要将索引1、2和5的元素提取到新列表中,您将如何做? 这是我的做法,但我并不十分满意: 有没有更好的办法? 更一般而言,给定一个索引元组,即使使用重复,您将如何使用该元组从列表中提取相应的元素(例如,元组产生)。 问题答案: 也许使用这个:
-
在下面的代码中:我正在读取一个文件,获取标题行,查找特定的标题列并存储它们的索引。然后我遍历其余的行,只需要这些索引的值。
-
问题内容: 如何获得Python中索引名称的列表?这是我到目前为止的内容: 问题答案: 搜索有关使用库进行检索的信息时,会出现此问题。接受的答案说可以使用,但该方法已删除(截至2017年)。要获取,您可以使用以下代码:
-
本文向大家介绍Python 从列表中取值和取索引的方法,包括了Python 从列表中取值和取索引的方法的使用技巧和注意事项,需要的朋友参考一下 如下所示: 建议大家多多尝试哦 下面介绍以下del删除 以上这篇Python 从列表中取值和取索引的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。