
熊猫数据框存储列表为字符串:如何转换回列表

我有一个n-by-m熊猫DataFramedf定义如下。(我知道这不是最好的方法。这对我在实际代码中尝试做的事情是有意义的,但这将是这篇文章的TMI,所以请相信我的话,这种方法在我的特定场景中是有效的。)
>>> df = DataFrame(columns=['col1'])
>>> df.append(Series([None]), ignore_index=True)
>>> df
Empty DataFrame
Columns: [col1]
Index: []
我将列表存储在此DataFrame的单元格中,如下所示。
>>> df['column1'][0] = [1.23, 2.34]
>>> df
col1
0 [1, 2]
出于某种原因,DataFrame将此列表存储为字符串而不是列表。
>>> df['column1'][0]
'[1.23, 2.34]'
我有两个问题要问你。
- 为什么DataFrame将列表存储为字符串,是否有办法绕过此行为?
- 如果没有,那么有没有Pythonic的方法将这个字符串转换成列表?
使现代化
我使用的DataFrame已从CSV格式保存和加载。这种格式,而不是DataFrame本身,将列表从字符串转换为文本。
共有3个答案

>
ast.literal_eval安全地计算包含Python文字或容器数据类型的字符串。
它是标准库的一部分
使用python的eval()与ast.literal_eval()相比?解释为什么
literal\u eval比使用eval更安全。-
null
- 请参阅熊猫-将字符串转换为处理此表示的字符串列表。
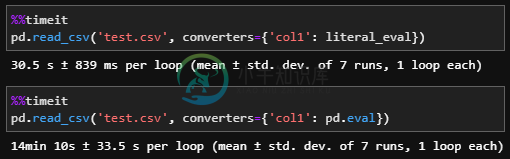
col1 "[1.23, 2.34]" "['KB4523205','KB4519569','KB4503308']"from ast import literal_eval import pandas as pd # convert the column during import df = pd.read_csv('test.csv', converters={'col1': literal_eval}) # display(df) col1 0 [1.23, 2.34] 1 [KB4523205, KB4519569, KB4503308] # check type print(type(df.iloc[0, 0])) list print(type(df.iloc[1, 0])) listdf.col1 = df.col1.apply(literal_eval)pd.eval比literal\u eval慢28倍

你可以直接使用熊猫-
import pandas as pd
df = pd.read_csv(DF_NAME, converters={'COLUMN_NAME': pd.eval})
这将在python中读取该列作为它对应的dtype,而不是字符串。
更新:
正如@ctwardy在评论中正确指出的那样。明智的做法是使用pd.eval而不是eval来避免意外的正则表达式相关后果。详情-https://realpython.com/python-eval-function/#minimizing-eval的安全问题

正如您指出的,当将熊猫数据帧保存和加载为文本格式的. csv文件时,通常会发生这种情况。
在你的例子中,发生这种情况是因为列表对象有一个字符串表示,允许它们存储为. csv文件。加载. csv将产生该字符串表示。
如果要存储实际对象,应使用DataFrame.to\u pickle()(注意:对象必须可拾取!)。
要回答第二个问题,可以使用ast.literal\u eval将其转换回:
>>> from ast import literal_eval
>>> literal_eval('[1.23, 2.34]')
[1.23, 2.34]
-
我有这个“file.csv”文件要和熊猫一起读: 使用 输出为: 我知道,列是一个完整的字符串,因为: 我需要将其作为字符串列表来阅读,如。我尝试了这个问题中提供的解决方案,但没有成功,因为我的和字符实际上会把事情搞砸。 预期输出应为:
-
问题内容: 我对熊猫有些陌生。我有一个熊猫数据框,它是1行乘23列。 我想将其转换为系列吗?我想知道最pythonic的方法是什么? 我试过了,但是抱怨。它不够聪明,无法意识到它仍然是数学上的“向量”。 谢谢! 问题答案: 它不够聪明,无法意识到它仍然是数学上的“向量”。 可以说它足够聪明,可以识别尺寸差异。:-) 我认为您可以做的最简单的事情是使用位置选择该行,这将为您提供一个Series,其列
-
问题内容: 我有以下熊猫数据框: 我想将日期时间索引转换为数据框的列。我尝试过,但结果没有改变。任何想法? 问题答案: 需要分配输出或参数:
-
我有一本python词典,名为,由关键字和值组成,这些关键字和值表示它们在给定文本中出现的频率: 现在,我需要将其制作成一个包含两列的pandas数据框:一列名为“word”,表示单词,另一列名为“count”,表示频率。
-
我有一个这样的字典列表: 我想把它变成一个熊猫,如下所示: 注意:列的顺序并不重要。 如何将字典列表转换为如上所示的数据帧?
-
问题内容: 如何使用Python将列表转换为字符串? 问题答案: 通过使用 或者,如果列表是整数,则在连接元素之前将其转换。