
4.算法原理以及算法效果(车载目标检测)
目标检测部分包括对机器人检测和装甲板检测,要求准确率和检测帧率可以达到实时效果,我们的目标检测算法基于anchor-base算法框架SSD(Single Shot MultiBox Detector),SSD框架对于轻量级主干网络,小目标检测效果不够理想,但是我们经过结构调整之后,整体算法效果有了惊人提升,我们采用的backbone基于mobilenet-v3,并进行一些改进,使其可以适应size为512×512大小图片输入,并且添加了PaFpn结构,来对输出的多尺度特征层进行融合,令小尺度的特征层具有丰富的语义信息,大尺度特征则有更为丰富的特征信息, 解决了SSD框架小目标检测效果差的问题。
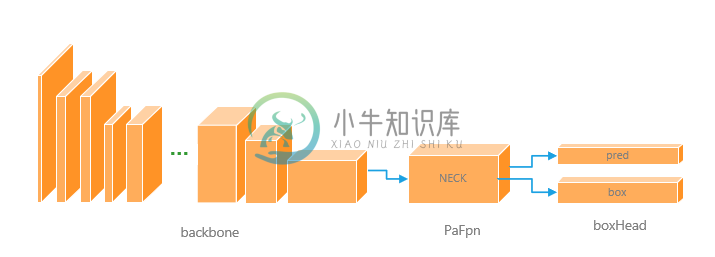
图 4.1 目标检测算法神经网络结构图
Backbone
我们删除了原文中一些block,使得小特征不会在计算中丢失,并且加快了推理速度。
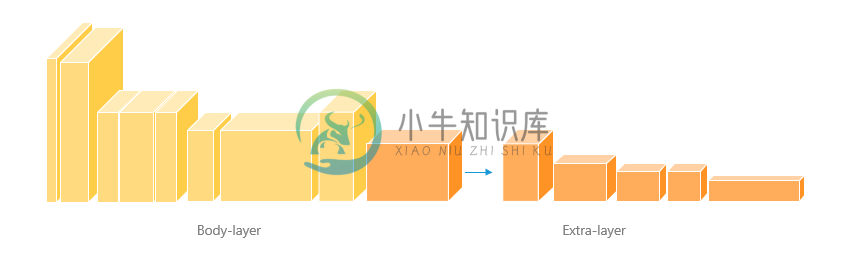
图 4.2 mobilenet-V3 改进版(橙色为特征输出)
网络结构
| 结构层数 | ker | in | hidden | out | stride | acti | res |
|---|---|---|---|---|---|---|---|
| 1(conv) | 3 | 3 | / | 16 | 2 | / | / |
| 2(block) | 3 | 16 | 64 | 24 | 2 | Relu | F |
| 3(block) | 5 | 24 | 72 | 40 | 2 | Relu | F |
| 4(block) | 3 | 40 | 240 | 80 | 2 | hswish | F |
| 5(block) | 3 | 80 | 200 | 80 | 1 | hswish | T |
| 6(block) | 3 | 80 | 480 | 112 | 1 | hswish | F |
| 7(block) | 3 | 112 | 672 | 160 | 1 | hswish | F |
| 8(block) | 5 | 160 | 672 | 160 | 2 | hsiwsh | T |
| 9 (conv) | 1 | 160 | / | 960 | 1 | / | / |
| extra--layer | |||||||
| 10(block) | 3 | 960 | 256 | 512 | 2 | / | / |
| 11(block) | 3 | 512 | 128 | 256 | 2 | / | / |
| 12(block) | 3 | 256 | 128 | 256 | 2 | / | / |
| 13(block) | 3 | 256 | 64 | 128 | 2 | / | / |
Necks
我们在实验过程中发现了无fpn结构网络对于小目标识别效果较差这个问题,Fpn结构可以有效地提升浅层特征的语义信息,同样也可以丰富深层特征的特征信息,使得定位更加精确,相比不采用fpn结构,采用fpn结构之后小目标识别的效果显著提升,经过算法对比,采用pafpn结构对于我们的网络结构检测效果提升明显。更多关于fpn结构的相关信息请查阅相关论文。[PaFpn 论文地址](https://arxiv.org/abs/1803.01534)
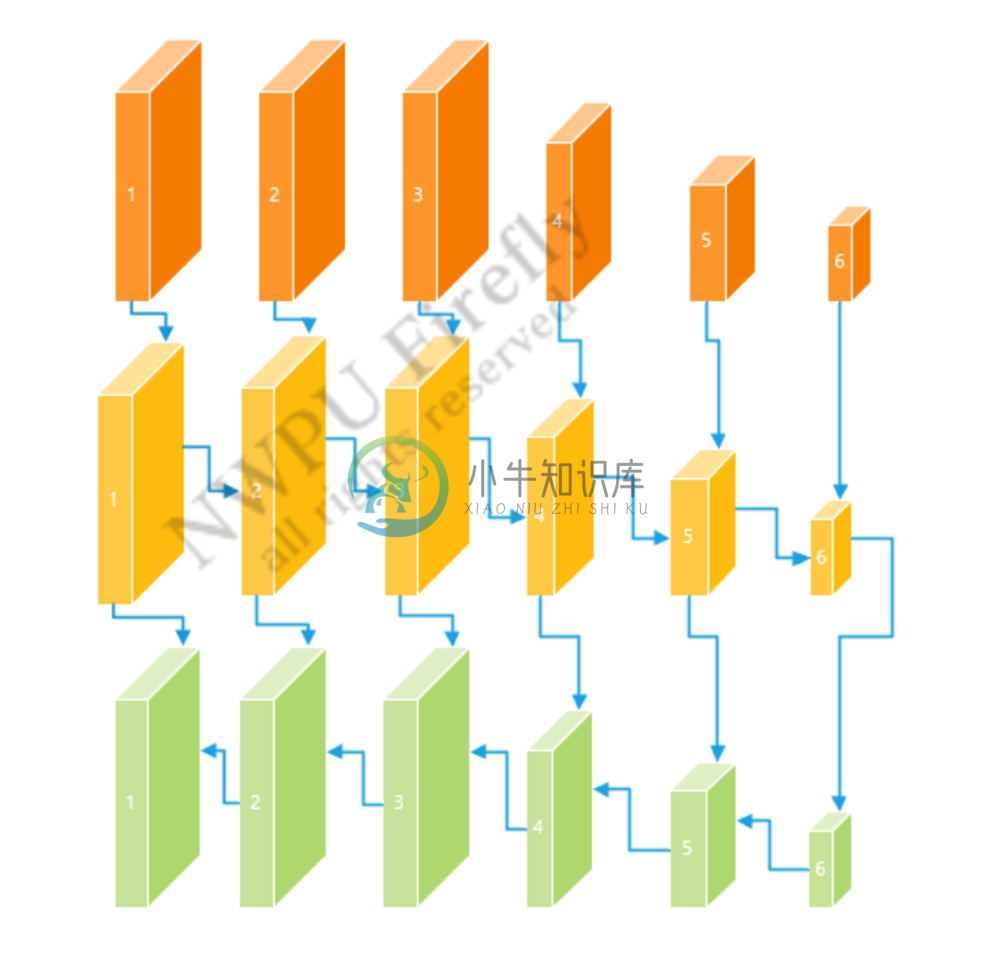
图 4.3 paFpn网络结构图
网络结构
| 层数 | input | hidden(down) | output(up) |
|---|---|---|---|
| 1 | 672 | 128 | 128 |
| 2 | 960 | 128 | 128 |
| 3 | 512 | 128 | 128 |
| 4 | 256 | 128 | 128 |
| 5 | 256 | 128 | 128 |
| 6 | 128 | 128 | 128 |
BoxHead
我们的BoxHead结构是对提取的特征进行回归,得到分类结果和包围框结果。
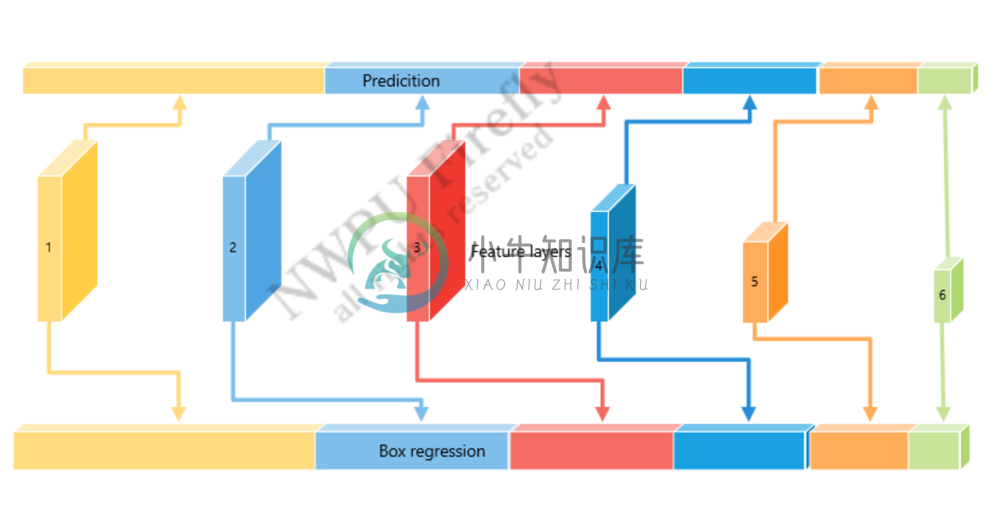
图 4.4 BoxHead 结构图
anchors
anchors 锚点, 共计有 4774 个
| layer | priorbox size |
|---|---|
| 1 | [16,16] [21,21] |
| 2 | [40, 40] [76,76] [13,13] [120,120] [80,80] [20,20] |
| 3 | [148, 148] [186,186] [74,74] [105,105] [296,296] [207,207] |
| 4 | [236,236] [276,276] [118,118] [168,168] [330,330] [472,472] |
| 5 | [324,324][365,365] |
| 6 | [412,412][459,459] |
数据处理
神经网络的训练数据来自于大疆机甲大师开源数据集,以及在自己场地上录制的部分数据集,在用官方数据集训练完成backbone之后,针对人工智能挑战赛,进行微调boxHead的操作。
由于官方数据集分辨率较高,直接输入,运算量较大,不利于推理加速,因此采用将官方数据集切割为512512大小的样本来进行训练。为了达到多尺度训练效果,训练集中增添了300300大小数据和100*100大小数据。
数据集样例:

图 4.5 DJI Robomaster 开源数据集样例图片
数据输入:






图 4.6 用于网络训练的图片样例
算法效果
算法对比
| mAp | Ap(car) | mAp(finetune) | Ap(car)(finetune) | |
|---|---|---|---|---|
| SSD-mobileNetv2 | 0.37 | 0.63 | 0.79 | 0.82 |
| SSD-mobileNetV2-pafpn | 0.46 | 0.74 | 0.88 | 0.90 |
| SSD-mobileNetV3 | 0.45 | 0.77 | 0.87 | 0.86 |
| SSD-mobileNetV3-pafpn | 0.55 | 0.81 | 0.90 | 0.90 |
场地实际效果

图 4.7 真实机器人测试效果
运行时间
我们将模型进行如下流程的转换:pytorch ==> onnx ==> tensorrt。转换完成之后,在device上运行,测试检测单张图片运行时间 (不计入IO时间)
| device | fp32 | fp16 |
|---|---|---|
| jetson nano | 12-11ms | 6-7ms |
| jetson tx2 | / | / |
| jetson xaiver | / | / |
| rtx2060 | 3-4ms | 1-2ms |
未来工作(3d-detection)
大致思路: 由回归包围框4个点变为回归包围箱的8个点,由已知的机器人尺寸,一起计算epnp,得到三维位置和姿态