
Kmeans均值聚类算法原理以及Python如何实现

第一步.随机生成质心
由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两个质心分为两堆就对了。如下图所示:
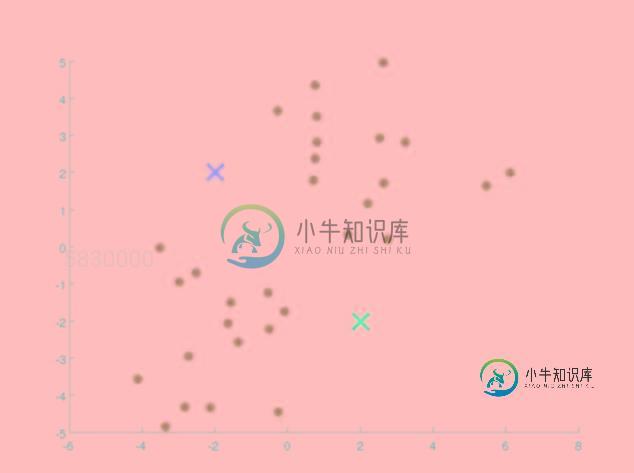
第二步.根据距离进行分类
红色和蓝色的点代表了我们随机选取的质心。既然我们要让这一堆点的分为两堆,且让分好的每一堆点离其质心最近的话,我们首先先求出每一个点离质心的距离。假如说有一个点离红色的质心比例蓝色的质心更近,那么我们则将这个点归类为红色质心这一类,反之则归于蓝色质心这一类,如图所示:
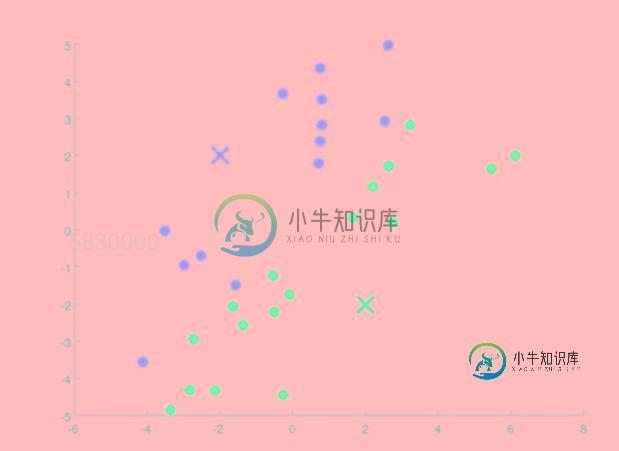
第三步.求出同一类点的均值,更新质心位置
在这一步当中,我们将同一类点的x\y的值进行平均,求出所有点之和的平均值,这个值(x,y)则是我们新的质心的位置,如图所示:
我们可以看到,质心的位置已经发生了改变。
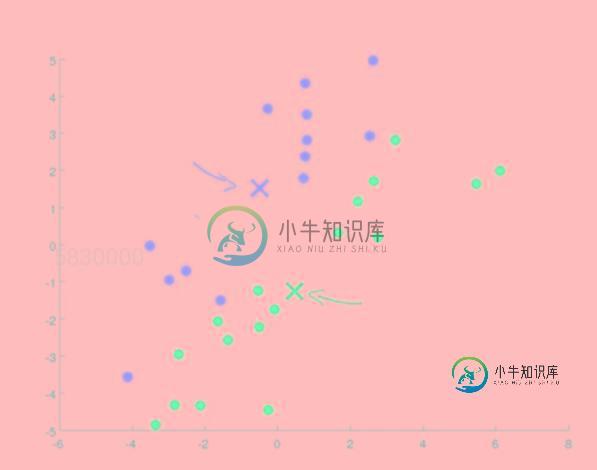
第四步.重复第二步,第三步
我们重复第二步和第三部的操作,不断求出点对质心的最小值之后进行分类,分类之后再更新质心的位置,直到得到迭代次数的上限(这个迭代次数是可以我们自己设定的,比如10000次),或者在做了n次迭代之后,最后两次迭代质心的位置已经保持不变,如下图所示:

这个时候我们就将这一堆点按照它们的特征在没有监督的条件下,分成了两类了!!
五.如果面对多个特征确定的一个点的情况,又该如何实现聚类呢?
首先我们引入一个概念,那就是欧式距离,欧式距离是这样定义的,很容易理解:

很显然,欧式距离d(xi,xj)等于我们每一个点的特征去减去另一个点在该维度下的距离的平方和再开根号,十分容易理解。
我们也可以用另一种方式来理解kmeans算法,那就是使某一个点的和另一些点的方差做到最小则实现了聚类,如下图所示:

得解!
六:代码实现
我们现在使用Python语言来实现这个kmeans均值算法,首先我们先导入一个名叫make_blobs的数据集datasets,然后分别使用两个变量X,和y进行接收。X表示我们得到的数据,y表示这个数据应该被分类到的是哪一个类别当中,当然在我们实际的数据当中不会告诉我们哪个数据分在了哪一个类别当中,只会有X当中数据。在这里写代码的时候比较特殊,make_blobs库要求我们必须接受这两个参数,不能够只接受X这个数据参数,代码如下
plt.figure(figsize=(15,15))#规定我们绘图的大小为12*12
X, y=make_blobs(n_samples=1600,random_state=170)#一共取用1600个sample,同时状态设定为随机
#不知道这个状态随机是什么意思,只能查有关这个库的官方文档,同时这个数据集规定了是具备三个数据中心,也就是三个簇
y_pred=KMeans(n_clusters=3,random_state=170).fit_predict(X)
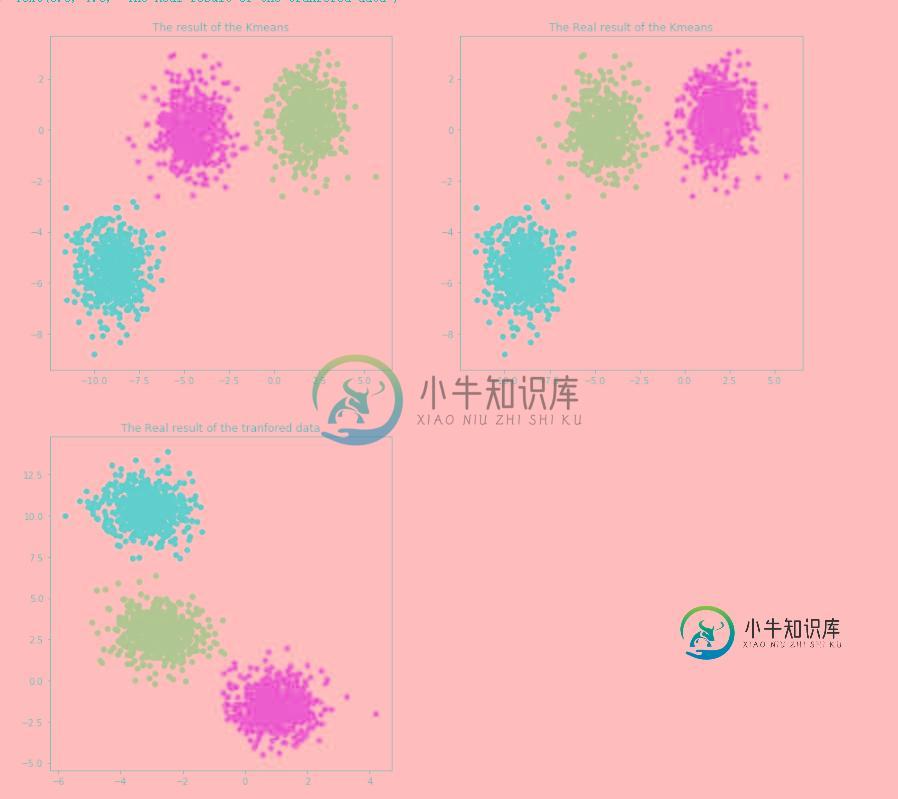
plt.subplot(221)#表示四个方格当中的第一格
plt.scatter(X[:,0],X[:,1],c=y_pred)#表示数据的第0个和第1个维度,同时数据的colour与predict的结果有关
plt.title("The result of the Kmeans")
plt.subplot(222)#表示四个方格当中的第一格
plt.scatter(X[:,0],X[:,1],c=y)
plt.title("The Real result of the Kmeans")
array=np.array([[0.60834549,-0.63667341],[-0.40887178,-0.85253229]])
lashen=np.dot(X,array)
y_pred=KMeans(n_clusters=3,random_state=170).fit_predict(lashen)
plt.subplot(223)#表示四个方格当中的第一格
plt.scatter(lashen[:,0],lashen[:,1],c=y_pred)#表示数据的第0个和第1个维度,同时数据的colour与predict的结果有关
plt.title("The Real result of the tranfored data")
我们在使用scatter函数进行绘图的时候会根据我们数据结的形状来编写相应的代码,这里我们所拿到的X数据集的行数是我们所指定的1600行,因为我们一共拿到了1600个数据,每一个数据仅有两个特征,也就是在XY轴当中的坐标,因此X是一个二维的ndarray对象(X是numpy当中的ndarray对象),我们可以打印出来看看这个数据的构成,如下图所示:

同时我们也可以看到y也是ndarray对象,由于我们在采集数据的时候仅仅接受了3个簇,make_blobs默认接受的是三个簇(或称cluster)的缘故,因此最后y的值只有0,1,2这三种可能。我们通过matplotlib绘图,绘制出我们分类的结果图,也就是上述代码的运行结果如下:
以上就是Kmeans均值聚类算法原理以及Python如何实现的详细内容,更多关于Kmeans均值聚类算法的资料请关注小牛知识库其它相关文章!
-
本文向大家介绍Python实现Kmeans聚类算法,包括了Python实现Kmeans聚类算法的使用技巧和注意事项,需要的朋友参考一下 本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4。 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的
-
本文向大家介绍kmeans算法原理?相关面试题,主要包含被问及kmeans算法原理?时的应答技巧和注意事项,需要的朋友参考一下 随机初始化中心点范围,计算各个类别的平均值得到新的中心点。 重新计算各个点到中心值的距离划分,再次计算平均值得到新的中心点,直至各个类别数据平均值无变化。
-
算法介绍 K-Means又名为K均值算法,他是一个聚类算法,这里的K就是聚簇中心的个数,代表数据中存在多少数据簇。K-Means在聚类算法中算是非常简单的一个算法了。有点类似于KNN算法,都用到了距离矢量度量,用欧式距离作为小分类的标准。 算法步骤 (1)、设定数字k,从n个初始数据中随机的设置k个点为聚类中心点。 (2)、针对n个点的每个数据点,遍历计算到k个聚类中心点的距离,最后按照离哪个中心
-
$k$均值聚类算法(k-means clustering algorithm) 在聚类的问题中,我们得到了一组训练样本集 ${x^{(1)},...,x^{(m)}}$,然后想要把这些样本划分成若干个相关的“类群(clusters)”。其中的 $x^{(i)}\in R^n$,而并未给出分类标签 $y^{(i)}$ 。所以这就是一个无监督学习的问题了。 $K$ 均值聚类算法如下所示: 随机初始化(
-
本文向大家介绍python中kmeans聚类实现代码,包括了python中kmeans聚类实现代码的使用技巧和注意事项,需要的朋友参考一下 k-means算法思想较简单,说的通俗易懂点就是物以类聚,花了一点时间在python中实现k-means算法,k-means算法有本身的缺点,比如说k初始位置的选择,针对这个有不少人提出k-means++算法进行改进;另外一种是要对k大小的选择也没有很完善的理
-
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies),名字实在是太长了,不过没关系,其实只要明白它是用层次方法来聚类和规约数据就可以了。刚才提到了,BIRCH只需要单遍扫描数据集就能进行聚类,那它是怎么做到的呢? BIRCH算法利用了一个树结构来帮助我们快速的聚类,这个数结构类