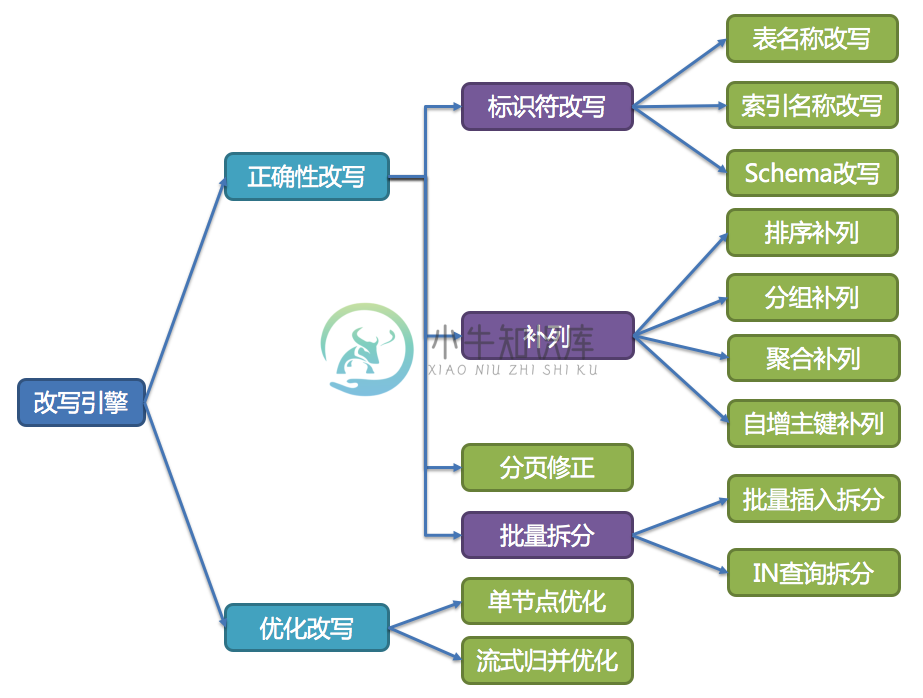
改写引擎
工程师面向逻辑库与逻辑表书写的 SQL,并不能够直接在真实的数据库中执行,SQL 改写用于将逻辑 SQL 改写为在真实数据库中可以正确执行的 SQL。 它包括正确性改写和优化改写两部分。
正确性改写
在包含分表的场景中,需要将分表配置中的逻辑表名称改写为路由之后所获取的真实表名称。仅分库则不需要表名称的改写。除此之外,还包括补列和分页信息修正等内容。
标识符改写
需要改写的标识符包括表名称、索引名称以及 Schema 名称。
表名称改写是指将找到逻辑表在原始 SQL 中的位置,并将其改写为真实表的过程。表名称改写是一个典型的需要对 SQL 进行解析的场景。 从一个最简单的例子开始,若逻辑 SQL 为:
SELECT order_id FROM t_order WHERE order_id=1;
假设该 SQL 配置分片键 order_id,并且 order_id=1 的情况,将路由至分片表 1。那么改写之后的 SQL 应该为:
SELECT order_id FROM t_order_1 WHERE order_id=1;
在这种最简单的 SQL 场景中,是否将 SQL 解析为抽象语法树似乎无关紧要,只要通过字符串查找和替换就可以达到 SQL 改写的效果。 但是下面的场景,就无法仅仅通过字符串的查找替换来正确的改写 SQL 了:
SELECT order_id FROM t_order WHERE order_id=1 AND remarks=' t_order xxx';
正确改写的 SQL 应该是:
SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order xxx';
而非:
SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order_1 xxx';
由于表名之外可能含有表名称的类似字符,因此不能通过简单的字符串替换的方式去改写 SQL。
下面再来看一个更加复杂的 SQL 改写场景:
SELECT t_order.order_id FROM t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
上面的 SQL 将表名作为字段的标识符,因此在 SQL 改写时需要一并修改:
SELECT t_order_1.order_id FROM t_order_1 WHERE t_order_1.order_id=1 AND remarks=' t_order xxx';
而如果 SQL 中定义了表的别名,则无需连同别名一起修改,即使别名与表名相同亦是如此。例如:
SELECT t_order.order_id FROM t_order AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
SQL 改写则仅需要改写表名称就可以了:
SELECT t_order.order_id FROM t_order_1 AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
索引名称是另一个有可能改写的标识符。 在某些数据库中(如 MySQL、SQLServer),索引是以表为维度创建的,在不同的表中的索引是可以重名的; 而在另外的一些数据库中(如 PostgreSQL、Oracle),索引是以数据库为维度创建的,即使是作用在不同表上的索引,它们也要求其名称的唯一性。
在 ShardingSphere 中,管理 Schema 的方式与管理表如出一辙,它采用逻辑 Schema 去管理一组数据源。 因此,ShardingSphere 需要将用户在 SQL 中书写的逻辑 Schema 替换为真实的数据库 Schema。
ShardingSphere 目前还不支持在 DQL 和 DML 语句中使用 Schema。 它目前仅支持在数据库管理语句中使用 Schema,例如:
SHOW COLUMNS FROM t_order FROM order_ds;
Schema 的改写指的是将逻辑 Schema 采用单播路由的方式,改写为随机查找到的一个正确的真实 Schema。
补列
需要在查询语句中补列通常由两种情况导致。 第一种情况是 ShardingSphere 需要在结果归并时获取相应数据,但该数据并未能通过查询的 SQL 返回。 这种情况主要是针对 GROUP BY 和 ORDER BY。结果归并时,需要根据 GROUP BY 和 ORDER BY 的字段项进行分组和排序,但如果原始 SQL 的选择项中若并未包含分组项或排序项,则需要对原始 SQL 进行改写。 先看一下原始 SQL 中带有结果归并所需信息的场景:
SELECT order_id, user_id FROM t_order ORDER BY user_id;
由于使用 user_id 进行排序,在结果归并中需要能够获取到 user_id 的数据,而上面的 SQL 是能够获取到 user_id 数据的,因此无需补列。
如果选择项中不包含结果归并时所需的列,则需要进行补列,如以下 SQL:
SELECT order_id FROM t_order ORDER BY user_id;
由于原始 SQL 中并不包含需要在结果归并中需要获取的 user_id,因此需要对 SQL 进行补列改写。补列之后的 SQL 是:
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
值得一提的是,补列只会补充缺失的列,不会全部补充,而且,在 SELECT 语句中包含 * 的 SQL,也会根据表的元数据信息选择性补列。下面是一个较为复杂的 SQL 补列场景:
SELECT o.* FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
我们假设只有 t_order_item 表中包含 order_item_id 列,那么根据表的元数据信息可知,在结果归并时,排序项中的 user_id 是存在于 t_order 表中的,无需补列;order_item_id 并不在 t_order 中,因此需要补列。 补列之后的 SQL 是:
SELECT o.*, order_item_id AS ORDER_BY_DERIVED_0 FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
补列的另一种情况是使用 AVG 聚合函数。在分布式的场景中,使用 avg1 + avg2 + avg3 / 3 计算平均值并不正确,需要改写为 (sum1 + sum2 + sum3) / (count1 + count2 + count3)。 这就需要将包含 AVG 的 SQL 改写为 SUM 和 COUNT,并在结果归并时重新计算平均值。例如以下 SQL:
SELECT AVG(price) FROM t_order WHERE user_id=1;
需要改写为:
SELECT COUNT(price) AS AVG_DERIVED_COUNT_0, SUM(price) AS AVG_DERIVED_SUM_0 FROM t_order WHERE user_id=1;
然后才能够通过结果归并正确的计算平均值。
最后一种补列是在执行 INSERT 的 SQL 语句时,如果使用数据库自增主键,是无需写入主键字段的。 但数据库的自增主键是无法满足分布式场景下的主键唯一的,因此 ShardingSphere 提供了分布式自增主键的生成策略,并且可以通过补列,让使用方无需改动现有代码,即可将分布式自增主键透明的替换数据库现有的自增主键。 分布式自增主键的生成策略将在下文中详述,这里只阐述与 SQL 改写相关的内容。 举例说明,假设表 t_order 的主键是 order_id,原始的 SQL 为:
INSERT INTO t_order (`field1`, `field2`) VALUES (10, 1);
可以看到,上述 SQL 中并未包含自增主键,是需要数据库自行填充的。ShardingSphere 配置自增主键后,SQL 将改写为:
INSERT INTO t_order (`field1`, `field2`, order_id) VALUES (10, 1, xxxxx);
改写后的 SQL 将在 INSERT FIELD 和 INSERT VALUE 的最后部分增加主键列名称以及自动生成的自增主键值。上述 SQL 中的 xxxxx 表示自动生成的自增主键值。
如果 INSERT 的 SQL 中并未包含表的列名称,ShardingSphere 也可以根据判断参数个数以及表元信息中的列数量对比,并自动生成自增主键。例如,原始的 SQL 为:
INSERT INTO t_order VALUES (10, 1);
改写的 SQL 将只在主键所在的列顺序处增加自增主键即可:
INSERT INTO t_order VALUES (xxxxx, 10, 1);
自增主键补列时,如果使用占位符的方式书写 SQL,则只需要改写参数列表即可,无需改写 SQL 本身。
分页修正
从多个数据库获取分页数据与单数据库的场景是不同的。 假设每 10 条数据为一页,取第 2 页数据。在分片环境下获取 LIMIT 10, 10,归并之后再根据排序条件取出前 10 条数据是不正确的。 举例说明,若 SQL 为:
SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2;
下图展示了不进行 SQL 的改写的分页执行结果。
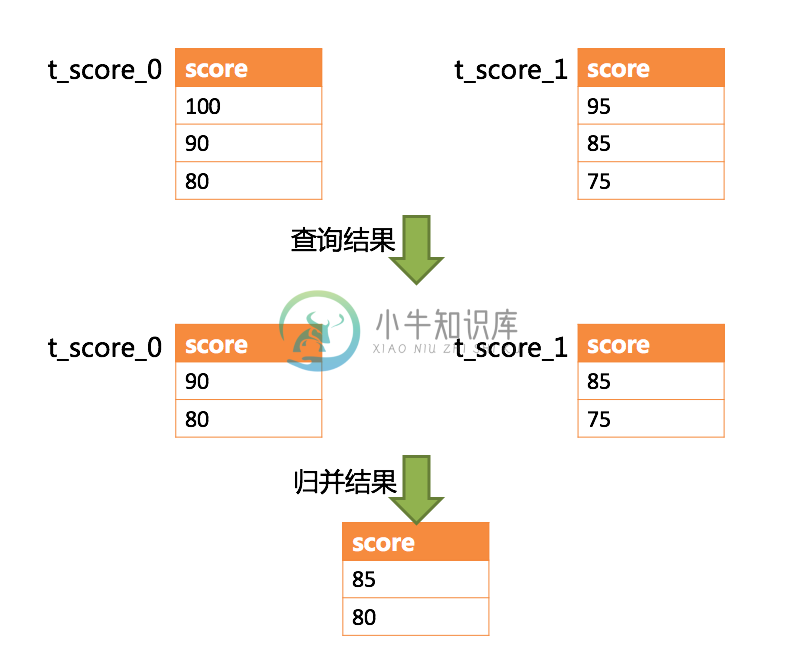
通过图中所示,想要取得两个表中共同的按照分数排序的第 2 条和第 3 条数据,应该是 95 和 90。 由于执行的 SQL 只能从每个表中获取第 2 条和第 3 条数据,即从 t_score_0 表中获取的是 90 和 80;从 t_score_1 表中获取的是 85 和 75。 因此进行结果归并时,只能从获取的 90,80,85 和 75 之中进行归并,那么结果归并无论怎么实现,都不可能获得正确的结果。
正确的做法是将分页条件改写为 LIMIT 0, 3,取出所有前两页数据,再结合排序条件计算出正确的数据。 下图展示了进行 SQL 改写之后的分页执行结果。
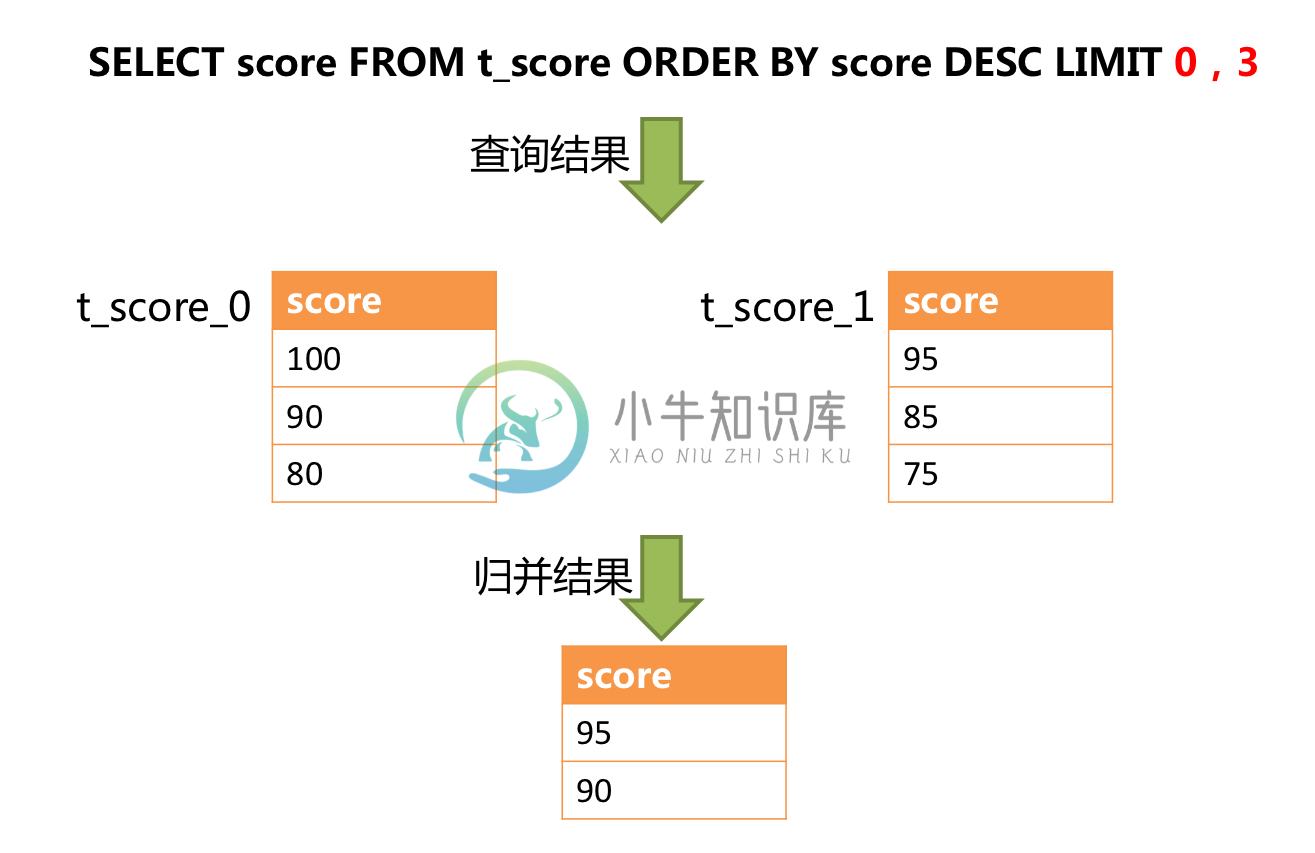
越获取偏移量位置靠后数据,使用 LIMIT 分页方式的效率就越低。 有很多方法可以避免使用 LIMIT 进行分页。比如构建行记录数量与行偏移量的二级索引,或使用上次分页数据结尾 ID 作为下次查询条件的分页方式等。
分页信息修正时,如果使用占位符的方式书写 SQL,则只需要改写参数列表即可,无需改写 SQL 本身。
批量拆分
在使用批量插入的 SQL 时,如果插入的数据是跨分片的,那么需要对 SQL 进行改写来防止将多余的数据写入到数据库中。 插入操作与查询操作的不同之处在于,查询语句中即使用了不存在于当前分片的分片键,也不会对数据产生影响;而插入操作则必须将多余的分片键删除。 举例说明,如下 SQL:
INSERT INTO t_order (order_id, xxx) VALUES (1, 'xxx'), (2, 'xxx'), (3, 'xxx');
假设数据库仍然是按照 order_id 的奇偶值分为两片的,仅将这条 SQL 中的表名进行修改,然后发送至数据库完成 SQL 的执行 ,则两个分片都会写入相同的记录。 虽然只有符合分片查询条件的数据才能够被查询语句取出,但存在冗余数据的实现方案并不合理。因此需要将 SQL 改写为:
INSERT INTO t_order_0 (order_id, xxx) VALUES (2, 'xxx');
INSERT INTO t_order_1 (order_id, xxx) VALUES (1, 'xxx'), (3, 'xxx');
使用 IN 的查询与批量插入的情况相似,不过 IN 操作并不会导致数据查询结果错误。通过对 IN 查询的改写,可以进一步的提升查询性能。如以下 SQL:
SELECT * FROM t_order WHERE order_id IN (1, 2, 3);
改写为:
SELECT * FROM t_order_0 WHERE order_id IN (2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 3);
可以进一步的提升查询性能。ShardingSphere 暂时还未实现此改写策略,目前的改写结果是:
SELECT * FROM t_order_0 WHERE order_id IN (1, 2, 3);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2, 3);
虽然 SQL 的执行结果是正确的,但并未达到最优的查询效率。
优化改写
优化改写的目的是在不影响查询正确性的情况下,对性能进行提升的有效手段。它分为单节点优化和流式归并优化。
单节点优化
路由至单节点的 SQL,则无需优化改写。 当获得一次查询的路由结果后,如果是路由至唯一的数据节点,则无需涉及到结果归并。因此补列和分页信息等改写都没有必要进行。 尤其是分页信息的改写,无需将数据从第 1 条开始取,大量的降低了对数据库的压力,并且节省了网络带宽的无谓消耗。
流式归并优化
它仅为包含 GROUP BY 的 SQL 增加 ORDER BY 以及和分组项相同的排序项和排序顺序,用于将内存归并转化为流式归并。 在结果归并的部分中,将对流式归并和内存归并进行详细说明。
改写引擎的整体结构划分如下图所示。