
Serverless 架构
花了 1000G,我终于弄清楚了 Serverless 是什么?
在过去的 24 小时,我通过微信公众号的『电子书』一事,大概处理了 8000 个请求:

大部分的请求都是在 200ms 内完成的,而在最开始的请求潮里(刚发推送的时候,十分钟里近 1500 个请求),平均的响应时间都在 50ms 内。

这也表明了,Serverless 相当的可靠。显然,当请求越多的时候,响应时间越快,这简直有违常理——一般来说,随着请求的增加,响应时间会越来越慢。
毫无疑问,在最近的几年里,微服务渐渐成为了一个相当流行的架构风格。微服务大致从 2014 年起,开始流行开来,如下图所示:
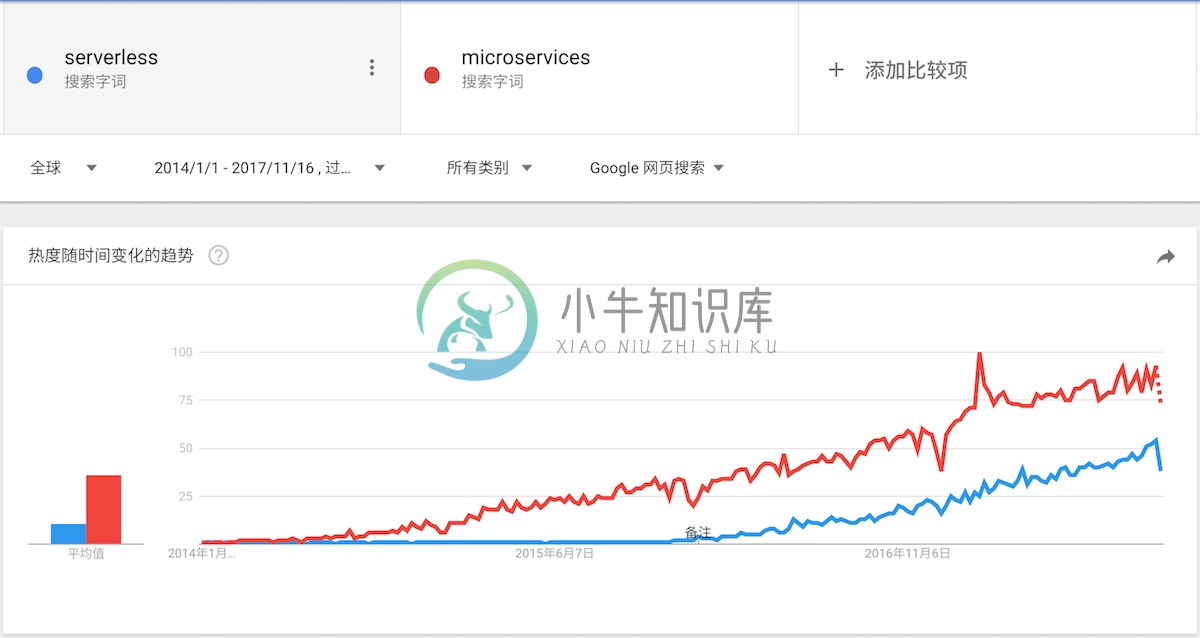
而 Serverless 是从 2016 年起,开始受到开发者的关注。并且从其发展趋势来看,它大有可能在两年后,拥有今天微服务一样的地位。可见,它是一个相当具有潜力的架构。
什么是 Serverless 架构??
为了弄清 Serverless 究竟是什么东西,Serverless 到底是个什么,我使用 Serverless 尝试了一个又一个示例,我自己也做了四五个应用,总算是对 Serverelss 有了一个大致上的认识。
虚拟化与隔离
开发人员为了保证开发环境的正确(即,这个 Bug 不是环境因素造成的),想出了一系列的隔离方式:虚拟机、容器虚拟化、语言虚拟机、应用容器(如 Java 的 Tomcat)、虚拟环境(如 Python 中的 virtualenv),甚至是独立于语言的 DSL。1
从最早的物理服务器开始,我们都在不断地抽象或者虚拟化服务器。
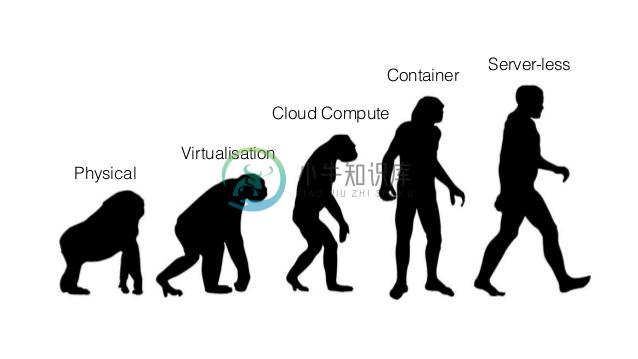
- 我们使用 XEN、KVM等虚拟化技术,隔离了硬件以及运行在这之上的操作系统。
- 我们使用云计算进一步地自动管理这些虚拟化的资源。
- 我们使用 Docker 等容器技术,隔离了应用的操作系统与服务器的操作。
现在,我们有了 Serverless,我们可以隔离操作系统,乃至更底层的技术细节。
为什么是花了 1000G ?
现在,让我简单地解释『花了 1000G,我终于弄清楚了 Serverless 是什么?』这句话,来说说 Serverless 到底是什么鬼?
在实践的过程中,我采用的是 AWS Lambda 作为 Serverless 服务背后的计算引擎。AWS Lambda 是一种函数即服务(Function-as-a-Servcie,FaaS)的计算服务,简单的来说就是:开发人员直接编写运行在云上的函数、功能、服 务。由云服务产商提供操作系统、运行环境、网关等一系列的基础环境,我们只需要关注于编写我们的业务代码即可。
是的,你没听错,我们只需要考虑怎么用代码提供价值即可。我们甚至连可扩展、蓝绿部署等一系列的问题都不用考虑,Amazon 优秀的运营工程师已经帮助我们打造了这一系列的基础设施。并且与传统的 AWS 服务一样,如 Elastic Compute Cloud(EC2),它们都是按流量算钱的。
那么问题又来了,它到底是怎么对一个函数收钱的。我在 Lambda 函数上运行一个 Hello, world 它会怎么收我的钱呢?
如果要对一个运行的函数收费,那么想必只有运行时间、CPU、内存占用、硬盘这几个条件。可针对于不同的需求,提供不同的 CPU 是一件很麻烦的事。对于代码来说,一个应用占用的硬盘空间几乎可以忽略不计。当然,这些应用会在你的 S3 上有一个备份。于是,诸如 AWS 采用的是运行时间 + 内存的计算方式。
| 内存 (MB) | 每个月的免费套餐秒数 | 每 100ms 的价格 (USD) |
|---|---|---|
| 128 | 3,200,000 | 0.000000208 |
| 192 | 2,133,333 | 0.000000313 |
| 256 | 1,600,000 | 0.000000417 |
| … | … | … |
| 1024 | 400,000 | 0.000001667 |
| … | … | … |
在运行程序的时候,AWS 会统计出一个时间和内存,如下所示:
REPORT RequestId: 041138f9-bc81-11e7-aa63-0dbab83f773d Duration: 2.49 ms Billed Duration: 100 ms Memory Size: 1024 MB Max Memory Used: 20 MB其中的 Memory Size 即是我们选用的套餐类型,Duration 即是运行的时间,Max Memory Used 是我们应用运行时占用的内存。根据我们的 Max Memory Used 数值及应用的计算量,我们可以很轻松地计算出我们所需要的套餐。
当然,选择不同大小的内存,也意味着选择不同功率的 CPU。
在 AWS Lambda 资源模型中,您可以选择您想为函数分配的内存量,并按 CPU 功率和其他资源的比例进行分配。例如,选择 256MB 的内存分配至您的 Lambda 函数的 CPU 功率约是请求 128MB 内存的两倍,若选择 512MB 的内存,其分配的 CPU 功率约是一半。您可以在 128MB 到 1.5GB 的范围间以 64MB 的增量设置您的内存。
因此,如果我们选用 1024M 的套餐,然后运行了 320 次,一共算是使用了 320G 的计算量。而其运行时间会被舍入到最近的 100ms,就算我们运行了 2.49ms,那么也是按 100ms 算的。那么假设,我们的 320 次计算都花了 1s,也就是 10×100ms,那么我们要支付的费用是:10×320×0.000001667=0.0053344刀,即使转成人民币也就是不到 4 毛钱的 0.03627392。
如果我们先用的是 128M 的套餐,那么运行了 2000 次,就是 200G 的计算量了。
如果我们先用的是 128M 的套餐,那么运行了 8000 次,就是 1000G 的计算量了。
不过如上表所示,AWS 为 Lambda 提供了一个免费套餐(无期限地提供给新老用户)包含每月 1M 免费请求以及每月 400 000 GB 秒的计算时间。这就意味着,在很长的时间里,我们一分钱都不用花。
Serverless 是什么?
而从上节的内容中,我们可以知道这么几点:
- 在 Serverless 应用中,开发者只需要专注于业务,剩下的运维等工作都不需要操心
- Serverless 是真正的按需使用,请求到来时才开始运行
- Serverless 是按运行时间和内存来算钱的
- Serverless 应用严重依赖于特定的云平台、第三方服务
当然这些都是一些虚无缥缈地东西。
按 AWS 官方对于 Serverless 的介绍是这样的:
服务器架构是基于互联网的系统,其中应用开发不使用常规的服务进程。相反,它们仅依赖于第三方服务(例如AWS Lambda服务),客户端逻辑和服务托管远程过程调用的组合。”2
在一个基于 AWS 的 Serverless 应用里,应用的组成是:
- 网关 API Gateway 来接受和处理成千上万个并发 API 调用,包括流量管理、授权和访问控制、监控等
- 计算服务 Lambda 来进行代码相关的一切计算工作,诸如授权验证、请求、输出等等
- 基础设施管理 CloudFormation 来创建和配置 AWS 基础设施部署,诸如所使用的 S3 存储桶的名称等
- 静态存储 S3 作为前端代码和静态资源存放的地方
- 数据库 DynamoDB 来存储应用的数据
- 等等
以博客系统为例,当我们访问一篇博客的时候,只是一个 GET 请求,可以由 S3 为我们提供前端的静态资源和响应的 HTML。
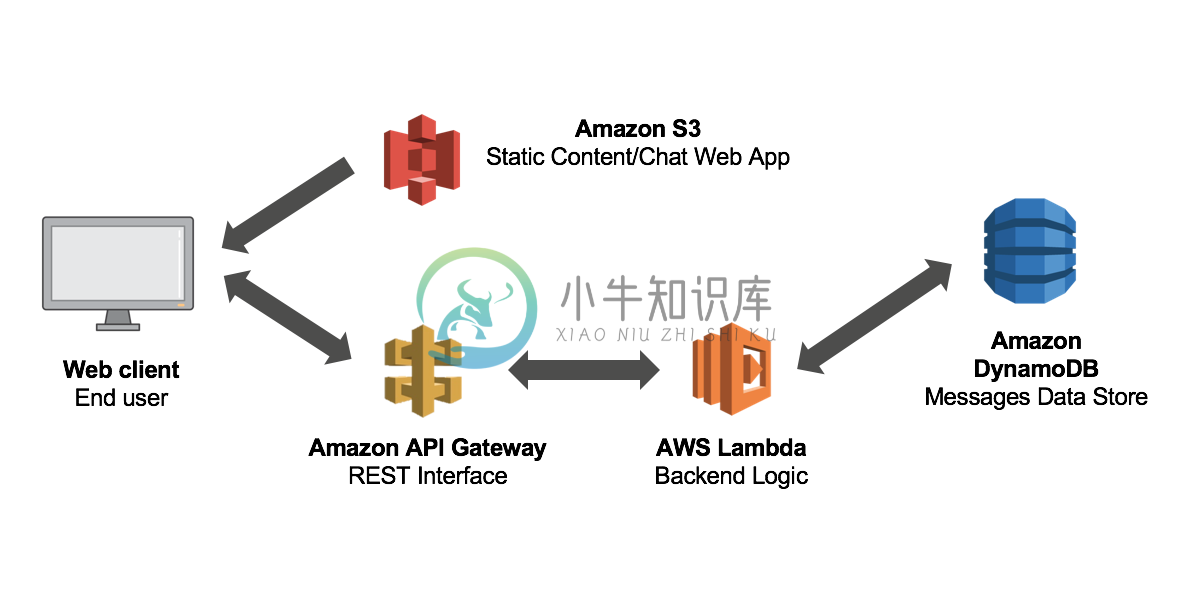
而当我们创建一个博客的时候:
- 我们的请求先来到了 API Gateway,API Gateway 计费器 + 1
- 接着请求来到了 Lambda,进行数据处理,如生成 ID、创建时间等等,Lambda 计费器 + 1
- Lambda 在计算完后,将数据存储到 DynamoDB 上,DynamoDB 计费器 + 1
- 最后,我们会生成静态的博客到 S3 上,而 S3 只在使用的时候按存储收费。
在这个过程中,我们使用了一系列稳定存在的云服务,并且只在使用时才计费。由于这些服务可以自然、方便地进行调用,我们实际上只需要关注在我们的 Lambda 函数上,以及如何使用这些服务完成整个开发流程。
因此,Serverless 并不意味着没有服务器,只是服务器以特定功能的第三方服务的形式存在。
当然并不一定使用这些云服务(如 AWS),才能称为 Serverless。诸如我的同事在 《Serverless 实战:打造个人阅读追踪系统》,采用的是:IFTTT + WebTask + GitHub Webhook 的技术栈。它只是意味着,你所有的应用中的一部分服务直接使用的是第三方服务。
在这种情况下,系统间的分层可能会变成一个又一个的服务。原本,在今天主流的微服务设计里,每一个领域或者子域都是一个服务。而在 Serverless 应用中,这些领域及子域因为他们的功能,又可能会进一步切分成一个又一个 Serverless 函数。
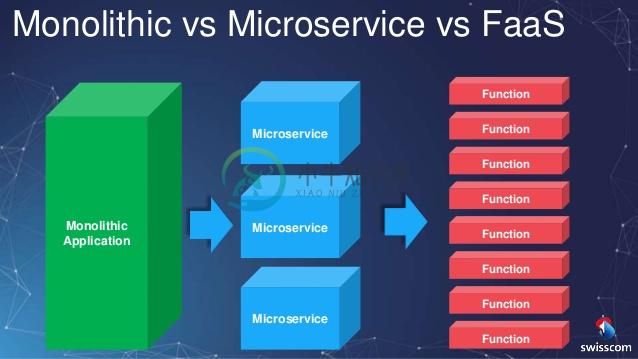
只是这些服务、函数比以往的粒度更加细致。
事件驱动编程
Serverless 的运行才计算,便意味着他是一种 “严格” 的事件驱动式计算。
事件驱动编程(英语:Event-driven programming)是一种电脑程序设计模型。这种模型的程序运行流程是由用户的动作(如鼠标的按键,键盘的按键动作)或者是由其他程序的消息来决定 的。相对于批处理程序设计(batch programming)而言,程序运行的流程是由程序员来决定。批量的程序设计在初级程序设计教学课程上是一种方式。然而,事件驱动程序设计这种设计模 型是在交互程序(Interactive program)的情况下孕育而生的。3
这也意味着,系统在编程模型上有着巨大的改变。在我们编写 GUI 程序,如桌面程序、Web 前端应用,我们都通过监听用户对按钮、链接等组件操作,才开始相应的处理逻辑。这和 Serverless 是相似的,只在用户使用的时候,才会对应用户的行为进行响应。
Serverless 的优势
在我使用 Serverless Framework 开发 AWS Serverless 应用的过程中,最方便的莫过于,第一次部署和第二次、第三次部署没有什么区别。只需要执行 serverless deploy,几分钟后,我们代码就运行在线上。如果是一个传统的 AWS 应用,我需要 SSH 到我的服务器上部署,这样才能写好我的自动部署脚本。除此,我还需要担忧这个过程中,有哪些用户有使用。
除了,我觉得的部署方便,还有就是价格合理。我的 AWS EC2 实例上运行着我的博客、以及其他的一些网络。然而,我那 PV 只有 500 左右的博客,大部分时间都是在空转。便觉得有些浪费,可是运行才收费的 Serverless 就不会有这样的问题。可以让我大胆地去使用这些服务。当然了,还有其它一些显著的优势。
降低启动成本
当我们作为一家公司开发一个 Web 应用时,在开发的时候,我们需要版本管理服务器、持续集成服务器、测试服务器、应用版本管理仓库等作为基础的服务。线上运行的时候,为了应对大量的请求,我们需要一个好的数据库服务器。当我们的应用面向了普通的用户时,我们需要:
- 邮件服务,用于发送提醒、注册等服务
- 短信服务(依国家实名规定),用于注册、登录等用户授权操作
对于大公司而言,这些都是现成的基础设施。可对于新创企业来说,这都是一些启动成本。
减少运营成本
对于初创公司来说,他们没有基础设施,也没有财力,也可能没有能力去建设基础设施。采用云服务往往是最好的选择,可以节省大量的资金。他们可以将注意力放在:创造对用户有价值的产品上。如果一家创业公司采用云服务,而不是自己搭建服务器。那么,他就会拥有更多的时间开发业务功能,而不是关注在这些。只需要为运行时的软件付钱。
而采用函数计算的 Serverless 与云服务器最大的不同之处在于:云服务器需要一直运行,而函数计算是按需计算。按需计算就意味着,在请求到来的时候,才运行函数。没有请求的时候,是不算钱的。
项目初期,其用户数往往是缓慢增长的,而我们在选择服务器的时候,往往会依可能出现的用户来估算。在这个时候,往往会浪费一些不必要的成本。不过,就算用户突然间爆发,Serverless 应用也可以轻松处理。只需要修改一下数据库配置,再重新部署一份。
降低开发成本
一个成功的 Serverless 服务供应商,应该能提供一系列的配套服务。这意味着,你只需要在配置文件上写下,这个数据库的表名,那么我们的数据就会存储到对应的数据库里。甚至于,**如果一个当服务提供者提供一系列的函数计算模板,那么我们只需要写好我们的配置即可。这一系列的东西都可以自动、高效的完成。
在这种情况下,使用某一个云服务,就会调用某一个系统自带的 API 一样简单。
当然,将应用设计成无状态应用,对于早期的系统,可能是一种挑战。除此,诸如 AWS 这样庞大的系统,对于新手程序员来说,也不能容易消化掉的一个系统。
实现快速上线
对于一个 Web 项目来说,启动一个项目需要一系列的 hello, world。当我们在本地搭建环境的时候,是一个 hello, world,当我们将程序部署到开发环境时,也是一个部署相关的 hello, world。虽然看上去有些不同,但是总的来说,都是 it works!。
Serverless 在部署上的优势,使得你可以轻松地实现上线。
更快的部署流水线
实际上,Serverless 应用之所以在部署上有优势,是因为其相当于内建自动化部署——我们在开发应用的时候,已经在不断地增强部署功能。
在我们日常的开发中,为了实现自动化部署,我们需要先手动部署,以设计出一个相关无错的部署配置,如 Docker 的 Dockerfile,又或者是 Ansible 的 playbook。除此,我们还需要设计好蓝绿发布等等的功能。
而在函数计算、Serverless 应用里,这些都是由供应商提供的功能。每次我们写完代码,只需要运行一下:sls deploy 就足够了。在诸如 AWS Lambda 的函数计算里,函数一般在上传后几秒钟内,就能做好调用准备。
这就意味着,当我们和日常一样,使用一个模板来开发我们的应用。我们就可以在 Clone 完代码后的几分钟内,完成第一次部署。
唯一的难点,可能是要选用什么配置类型的服务,如选用哪个级别吞吐量的 DynamoDB、哪个内存大小的 Lambda 计算。
更快的开发速度
由于 Serverless 服务提供者,已经准备好了一系列的基础服务。作为开发人员的我们,只需要关注于如何更好去实现业务,而非技术上的一些限制。
服务提供者已经向我们准备,并测试好了这一系列的服务。它们基本上是稳定、可靠的,不会遇上特别大的问题。事实上,当我们拥有足够强大的代码,如使 用测试来保证健壮性,那么结合持续集成,我们就可以在 PUSH 代码的时候,直接部署到生产环境。当然,可能不需要这么麻烦,我们只需要添加一个 predeploy 的 hook,在这个 hook 里做一些自动测试的工作,就可以在本地直接发布新的版本。
这个过程里,我们并不需要考虑太多的发布事宜。
系统安全性更高
依我维护我博客的经验来看,要保持服务器一直运行不是一件容易的事。在不经意的时候,总会发现有 Cracker 在攻击你网站。我们需要防范不同类型的攻击,如在我的服务器里一直有黑客在尝试密码登录,可是我的博客的服务器是要密钥才能登录的。在一次神奇的尝试登录 攻击后,我的 SSH 守护进程崩溃了。这意味着,我只能从 EC2 后台重启服务器。
有了 Serverless,我不再需要担心有人尝试登录系统,因为我都不知道怎么登录服务器。
我不再需要考虑系统底层安全问题,每次登录 AWS EC2,我总需要更新一遍软件;每当我看到某个软件有漏洞时,如之前的 OpenSSH,我就登录上去看一下版本,更新一下软件。真 TM 费时又费力,还没有一点好处。
唯一需要担心的,可能是有人发起 DDOS 攻击。而根据Could Zombie Toasters DDoS My Serverless Deployment?的计算,每百万的请求,大概是 0.2 刀,每小时 360000000 个请求,也就 72 刀。
适应微服务架构
如我们所见在最近几年里看到的那样,微服务并没有大量地替换掉单体应用——毕竟使用新的架构来替换旧的系统,在业务上的价值并不大。因此,对于很多企业来说,并没有这样的强烈需求及紧迫性。活着,才是一件更紧迫的事。
而 Serverless 天生就与微服务架构是相辅相成的。一个 Serverless 应用拥有自己的网关、数据库、接口,你可还以使用自己喜欢的语言(受限于服务提供者)来开发服务。换句话来说,在这种情形下,一个 Serverless 可能是一个完美的微服务实例。
在可见的一二年里,Serverless 将替换到某些系统中的一些组件、服务。
自动扩展能力
Serverless 的背后是 诸如 AWS Lambda 这样的 FaaS(Function as a Services)。
对于传统应用来说,要应对更多的请求的方式,就是部署更多的实例。然而,这个时候往往已经来不及了。而对于 FaaS 来说,我们并不需要这么做,FaaS 会自动的扩展。它可以在需要时尽可能多地启动实例副本,而不会发生冗长的部署和配置延迟。
这依赖于我们的服务是无状态的,我们才能次无忌惮地不断运行起新的实例。
Serverless 的问题
作为一个运行时,才启动的应用来说,Serverless 也存在着一个个我们所需要的问题。
不适合长时间运行应用
Serverless 在请求到来时才运行。这意味着,当应用不运行的时候就会进入 “休眠状态”,下次当请求来临时,应用将会需要一个启动时间,即冷启动。这个时候,可以结合 CRON 的方式或者 CloudWatch 来定期唤醒应用。
如果你的应用需要一直长期不间断的运行、处理大量的请求,那么你可能就不适合采用 Serverless 架构。在这种情况下,采用 EC2 这样的云服务器往往是一种更好的选择。因为 EC2 从价格上来说,更加便宜。
引用 Lu Zou 在 《花了 1000G,我终于弄清楚了 Serverless 是什么(上):什么是 Serverless 架构?》上的评论:
EC2 相当于你买了一辆车,而 Lambda 相当于你租了你一辆车。
长期租车的成本肯定比买车贵,但是你就少掉了一部分的维护成本。因此,这个问题实际上是一个值得深入计算的问题。
完全依赖于第三方服务
是的,当你决定使用某个云服务的时候,也就意味着你可能走了一条不归路。在这种情况下,只能将不重要的 API 放在 Serverless 上。
当你已经有大量的基础设施的时候,Serverless 对于你来说,并不是一个好东西。当我们采用 Serverless 架构的时候,我们就和特别的服务供应商绑定了。我们使用了 AWS 家的服务,那么我们再将服务迁到 Google Cloud 上就没有那么容易了。
我们需要修改一下系列的底层代码,能采取的应对方案,便是建立隔离层。这意味着,在设计应用的时候,就需要:
- 隔离 API 网关
- 隔离数据库层,考虑到市面上还没有成熟的 ORM 工具,让你即支持 Firebase,又支持 DynamoDB
- 等等
这些也将带给我们一些额外的成本,可能带来的问题会比解决的问题多。
冷启动时间
如上所说,Serverless 应用存在一个冷启动时间的问题。
据 New Relic 官方博客《Understanding AWS Lambda Performance—How Much Do Cold Starts Really Matter?》称,AWS Lambda 的冷启动时间。
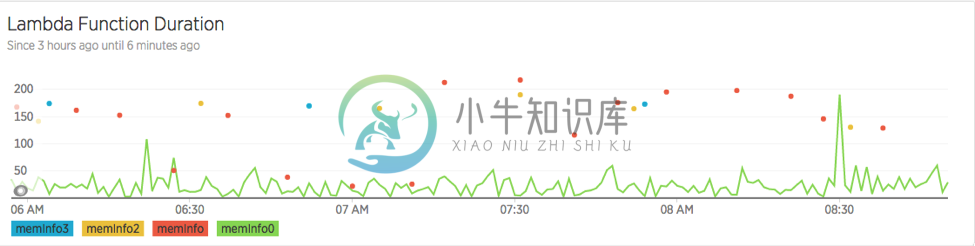
又或者是我之前统计的请求响应时间:

尽管这个冷启动时间大部分情况下,可以在 50ms 以内。而这是对于 Node.js 应用来说,对于拥有虚拟机的 Java 和 C# 可能就没有那么幸运了。
缺乏调试和开发工具
当我使用 Serverless Framework 的时候,遇到了这样的问题:缺乏调试和开发工具。后来,我发现了 serverless-offline、dynamodb-local 等一系列插件之后,问题有一些改善。
然而,对于日志系统来说,这仍然是一个艰巨的挑战。
每次你调试的时候,你需要一遍又一遍地上传代码。而每次上传的时候,你就好像是在部署服务器。然后 Fuck 了,我并不能总是快速地定位出问题在哪。于是,我修改了一下代码,添加了一行 console.log,然后又一次地部署了下代码。问题解决了,挺好的,我删了一下 console.log,然后又一次地部署了下代码。
后来,我学乖了,找了一个类似于 log4j 这样的可以分级别纪录日志的 Node.js 库 winston。它可以支持 error、warn、info、verbose、debug、silly 六个不同级别的日志。
构建复杂
Serverless 很便宜,但是这并不意味着它很简单。
早先,在知道 AWS Lambda 之后,我本来想进行一些尝试。但是 CloudForamtion 让我觉得太难了,它的配置是如此的复杂,并且难以阅读及编写(JSON 格式)。
考虑到 CloudForamtion 的复杂度,我是在接触了 Serverless Framework 之后,才重新燃起了一些信心。
Serverless Framework 的配置更加简单,采用的是 YAML 格式。在部署的时候,Serverless Framework 会根据我们的配置生成 CloudForamtion 配置。
在那篇《Kinesis Firehose 持久化数据到 S3》想着的数据统计文章里,我们介绍了 Serverless 框架的配置。与一般的 Lambda 配置来说,这里的配置就稍微复杂一些。然而,这也并非是一个真正用于生产的配置。我的意思是,真实的应用场景远远比这复杂。
语言版本落后
在 Node.js 6 出来的时候,AWS Lambda 只支持 Node.js 4.3.2;在 Node.js 9.0 出来的时候,AWS Lambda 支持到 6.10.3。
如下是 AWS Lambda 支持以下运行时版本:
- Node.js – v4.3.2 和 6.10.3
- Java - Java 8
- Python – Python 3.6 和 2.7
- .NET 内核 – .NET 内核 1.0.1 (C#)
对于 Java 和 Python 来说,他们的版本上可能基本都是够用的,我不知道 C# 怎么样。但是 Node.js 的版本显然是有点老旧的,但是都 Node.js 9.2.0 了。不过,话说来说,这可能与版本帝 Chrome 带来的前端版本潮有一点关系。
Serverless 的适用场景
尽管 Serverless 在编写传统的 Web 应用上,有一定的缺点。然而,它的事件驱动及运行时计算,使得它在某些场景上相当的合适。
发送通知
由我们在上一节中提到的,对于诸如 PUSH Notification、邮件通知接口、短信,这一类服务来说,他们都需要基础设施来搭建。并且,他们对实时性的要求相对没有那么高。
即使在时间上晚来几秒钟,用户还是能接受的。在我们所见到的短信发送的例子里,一般都会假设用户能在 60 秒内收到短信。因此,在这种时间 1s 的误差,用户也不会恼火的。而对于 APP 的消息推送而言,这种要求就更低了,用户反而不太希望能收到这样的推送
WebHook
当我们没有服务器,又想要一个 Webhook 来触发我们一系列的操作的时候。我们就可以考虑使用 Serverless,我们不需要一直就这么支付一个服务器的费用。通过 Serverless,我们就可以轻松完成这样的工作,并且节省大量的费用。
一个比较明显的例子,就如 GitHub Hooks
GitHub 上的 Webhook 允许我们构建或设置在 GitHub.com 上订阅某些事件的 GitHub 应用程序。当触发这些事件之一时,我们将向 webhook 配置的 URL 发送 HTTP POST 有效内容。
比如说,当我们 PUSH 了代码,我们想触发我们的持续集成。这个时候,就可以通过一个 Webhook 来做这样的事情。
轻量级 API
Serverless 特别适合于,轻量级快速变化地 API。
其实,我一直没有想到一个合适的例子。在我的假想里,一个 AutoSuggest 的 API 可能就是这样的 API,但是这种 API 在有些时候,往往会伴随着相当复杂的业务。
于是,便想举一个 Featrue Toggle 的例子,尽管有一些不合适。但是,可能是最有价值的部分。
物联网
当我们谈及物联网的时候,我们会讨论事件触发、传输协议、海量数据(数据存储、数据分析)。而有了 Serverless,那么再多的数据,处理起来也是相当容易的一件事。
对于一个物联网应用的服务端来说,系统需要收集来自各个地方的数据,并创建一个个 pipeline 来处理、过滤、转换这些数据,并将数据存储到数据库中。
对于硬件开发人员来说,对接不同的硬件,本身就是一种挑战。而直接使用诸如 AWS IoT 这样国,可以在某种程度上,帮助我们更好地开发出写服务端连接的应用。
同时,对于物联网应用的客户端来说,则需要从数据库抽取数据进行展示。这部分,可能算不上是一个挑战点。
数据统计分析
数据统计本身只需要很少的计算量,但是生成图表,则可以定期生成。
在接收数据的时候,我们不需要考虑任何延时带来的问题。50~200 ms 的延时,并不会对我们的系统造成什么影响。
Trigger 及定时任务
对于哪些需要爬虫来抓取和生成的程序来说,Serverless 可能是一个不错的舞台。
尽管,这样的工作也可以由云服务器来做,我们只需要定时的启动一下服务器。通过服务器中的自启动脚本来做相应的事,但是当我们完成了一系列的工作之 后。我们需要将数据存储在一个远程的服务器上。而为了让系统中的其它应用,也能直接访问这些数据。那么,我们可能会考虑使用一个云数据库。这个时 候,Serverless 应用看上去更具有吸引力。
在那篇《CRON 定时执行 Lambda 任务》中,我们也可以看到 AWS Lambda 可以支持 Lambda 计算,定时启动服务,并计算。
精益创业
Serverless 的快速上线、开发,意味着它可以快速验证一个想法 MVP。如 Dropbox 在开始的时候,只创造了一个 Landing Page。作为一个想使用这个服务的用户,我们会在其中填上我们的邮箱。
而如果是使用 Serverless 来构建这样的应用,那么我们只需要创建一个静态页面,然后用一个 Serverless 服务来保存用户的邮箱到数据库中,如我在 GitHub 上的 serverless-landingpage 所做的那样。
Chat 机器人
聊天机器人,也是一个相当好的应用场景。
But,由于国内的条件限制(信息监管),这并不是一件容易的事。因此,从渠道(如微信、blabla)上,都在尽可能地降低这方面的可能性。
但是,我们还可以做一个微信公众号的服务。当用户输入一个关键词时,做出相应的回复,这实质上和聊天机器人是差不多的。只需要结合《基于 Serverless 与 Lambda 的微信公共平台》 就可以轻松实现,并实现快速上线。
其它
迁移方案
Express 应用示例
Serverless Framework
Serverless Framework是无服务器应用框架和生态系统,旨在简化开发和部署AWS Lambda应用程序的工作。Serverless Framework 作为 Node.js NPM 模块提供,填补了AWS Lambda 存在的许多缺口。它提供了多个样本模板,可以迅速启动 AWS Lambda 开发。
Apex
Apex可以轻松地构建、部署和管理AWS Lambda功能。通过节点可使用由AWS Lambda(如Golang)所不支持的语言,js shim注入到构建中,为测试功能、回滚部署、查看度量、跟踪日志、连接到构建系统以及更多的功能提供了各种工作流相关工具。
Apache OpenWhisk
OpenWhisk是一个分布式的、事件驱动的计算服务。OpenWhisk运行应用程序逻辑,以应对事件或直接通过HTTP调用网络或移动应用。