
分析网站日志,打造访问地图
概况
背景
这个项目的背景是起源于,我有一个2G左右的网站访问日志。我想看看访问网站的人都来自哪里,于是我想开始想办法来分析这日志。当时正值大数据火热的时候,便想拿着Hadoop来做这样一件事。
ShowCase
最后的效果如下图如示:
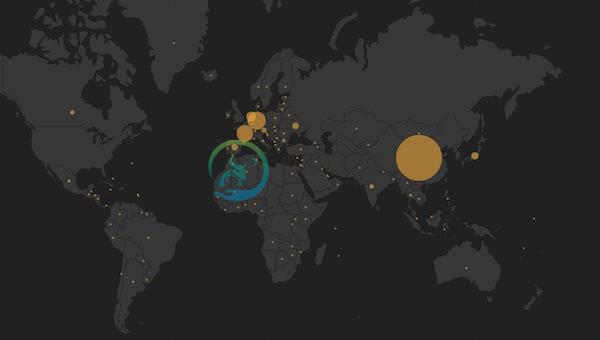
这是一个Web生成的界面,通过Elastic.js向搜索引擎查询数据,将再这些数据渲染到地图上。
Hadoop + Pig + Jython + AmMap + ElasticSearch
我们使用的技术栈有上面这些,他们的简介如下:
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
- Pig 是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
- Jython是一种完整的语言,而不是一个Java翻译器或仅仅是一个Python编译器,它是一个Python语言在Java中的完全实现。Jython也有很多从CPython中继承的模块库。
- AmMap是用于创建交互式Flash地图的工具。您可以使用此工具来显示您的办公室地点,您的行程路线,创建您的经销商地图等。
- ElasticSearch是一个基于Lucene 构建的开源,分布式,RESTful 搜索引擎。 设计用于云计算中,能够达到搜索实时、稳定、可靠和快速,并且安装使用方便。
步骤
总的步骤并不是很复杂,可以分为:
- 搭建基础设施
- 解析access.log
- 转换IP为GEO信息
- 展示数据到地图上
Step 1: 搭建基础设施
在这一些系列的实战中,比较麻烦的就是安装这些工具,我们需要安装上面提到的一系列工具。对于不同的系统来说,都有相似的安装工具:
- Windows上可以使用Chocolatey
- Ubuntu / Mint上可以使用aptitude
- CentOS / OpenSUSE上可以使用yum安装
- Mac OS上可以使用brew安装
如下是Mac OS下安装Hadoop、Pig、Elasticsearch、Jython的方式
brew install hadoop
brew install pig
brew install elasticsearch
brew install jython对于其他操作系统也可以使用相似的方法来安装。接着我们还需要安装一个Hadoop的插件,用于连接Hadoop和ElasticSearch。
下载地址:https://github.com/elastic/elasticsearch-hadoop
复制其中的elasticsearch-hadoop-*.jar、elasticsearch-hadoop-pig-*.jar到你的pig库的目录,如我的是:/usr/local/Cellar/pig/0.14.0。
由于我使用提早期的版本,所以这里我的文件名是:elasticsearch-hadoop-2.1.0.Beta3.jar、elasticsearch-hadoop-pig-2.1.0.Beta3.jar。
下面我们就可以尝试去解析我们的日志了。
Step 2: 解析access.log
在开始解析之前,先让我们来看看几条Nginx的日志:
106.39.113.203 - - [28/Apr/2016:10:40:31 +0000] "GET / HTTP/2.0" 200 0 "https://www.phodal.com/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36" -
66.249.65.119 - - [28/Apr/2016:10:40:51 +0000] "GET /set_device/default/?next=/blog/use-falcon-peewee-build-high-performance-restful-services-wordpress/ HTTP/1.1" 302 5 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" -而上面的日志实际上是有对应的格式的,这个格式写在我们的Nginx配置文件中。如下是上面的日志的格式:
log_format access $remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $http_x_forwarded_for';在最前面的是访问者的IP地址,然后是访问者的当地时间、请求的类型、状态码、访问的URL、用户的User Agent等等。随后,我们就可以针对上面的格式编写相应的程序,这些代码如下所示:
register file:/usr/local/Cellar/pig/0.14.0/libexec/lib/piggybank.jar;
register file:/usr/local/Cellar/pig/0.14.0/libexec/lib/elasticsearch-hadoop-pig-2.1.0.Beta3.jar;
RAW_LOGS = LOAD 'data/access.log' USING TextLoader as (line:chararray);
LOGS_BASE = FOREACH RAW_LOGS GENERATE
FLATTEN(
REGEX_EXTRACT_ALL(line, '(\\S+) - - \\[([^\\[]+)\\]\\s+"([^"]+)"\\s+(\\d+)\\s+(\\d+)\\s+"([^"]+)"\\s+"([^"]+)"\\s+-')
)
AS (
ip: chararray,
timestamp: chararray,
url: chararray,
status: chararray,
bytes: chararray,
referrer: chararray,
useragent: chararray
);
A = FOREACH LOGS_BASE GENERATE ToDate(timestamp, 'dd/MMM/yyyy:HH:mm:ss Z') as date, ip, url,(int)status,(int)bytes,referrer,useragent;
--B = GROUP A BY (timestamp);
--C = FOREACH B GENERATE FLATTEN(group) as (timestamp), COUNT(A) as count;
--D = ORDER C BY timestamp,count desc;
STORE A INTO 'nginx/log' USING org.elasticsearch.hadoop.pig.EsStorage();在第1~2行里,我们使用了自定义的jar文件。接着在第4行,载入了log文件,并其值赋予RAW_LOGS。随后的第6行里,我们取出RAW_LOGS中的每一个值 ,根据下面的正则表达式,取出其对应的值到对象里,如- -前面的(\S+)对应的是ip,最后将这些值赋给LOGS_BASE。
接着,我们就可以对值进行一些特殊的处理,如A是转化时间戳后的结果。B是按时间戳排序后的结果。最后,我们再将这些值存储到ElasticSearch对应的索引nginx/log中。
Step 3: 转换IP为GEO信息
在简单地完成了一个Demo之后,我们就可以将IP转换为GEO信息了,这里我们需要用到一个名为pygeoip的库。GeoIP是一个根据IP地 址查询位置的API的集成。它支持对国家、地区、城市、纬度和经度的查询。实际上,就是在一个数据库中有对应的国家和地区的IP段,根据这个IP段,我们 就可以获取对应的地理位置。
由于使用Java来实现这个功能比较麻烦,这里我们就使用Jython来实现。大部分的过程和上面都是一样的,除了注册了一个自定义的库,并在这个库里使用了解析GEO的方法,代码如下所示:
register file:/usr/local/Cellar/pig/0.14.0/libexec/lib/piggybank.jar;
register file:/usr/local/Cellar/pig/0.14.0/libexec/lib/elasticsearch-hadoop-pig-2.1.0.Beta3.jar;
register utils.py using jython as utils;
RAW_LOGS = LOAD 'data/access.log' USING TextLoader as (line:chararray);
LOGS_BASE = FOREACH RAW_LOGS GENERATE
FLATTEN(
REGEX_EXTRACT_ALL(line, '(\\S+) - - \\[([^\\[]+)\\]\\s+"([^"]+)"\\s+(\\d+)\\s+(\\d+)\\s+"([^"]+)"\\s+"([^"]+)"\\s+-')
)
AS (
ip: chararray,
timestamp: chararray,
url: chararray,
status: chararray,
bytes: chararray,
referrer: chararray,
useragent: chararray
);
A = FOREACH LOGS_BASE GENERATE ToDate(timestamp, 'dd/MMM/yyyy:HH:mm:ss Z') as date, utils.get_country(ip) as country,
utils.get_city(ip) as city, utils.get_geo(ip) as location,ip,
url, (int)status,(int)bytes,referrer,useragent;
STORE A INTO 'nginx/log' USING org.elasticsearch.hadoop.pig.EsStorage();在第三行里,我们注册了utils.py并将其中的函数作为utils。接着在倒数第二行里,我们执行了四个utils函数。即:
- get_country从IP中解析出国家
- get_city从IP中解析出城市
- get_geo从IP中解析出经纬度信息
其对应的Python代码如下所示:
#!/usr/bin/python
import sys
sys.path.append('/Users/fdhuang/test/lib/python2.7/site-packages/')
import pygeoip
gi = pygeoip.GeoIP("data/GeoLiteCity.dat")
@outputSchema('city:chararray')
def get_city(ip):
try:
city = gi.record_by_name(ip)["city"]
return city
except:
pass
@outputSchema('country:chararray')
def get_country(ip):
try:
city = gi.record_by_name(ip)["country_name"]
return city
except:
pass
@outputSchema('location:chararray')
def get_geo(ip):
try:
geo = str(gi.record_by_name(ip)["longitude"]) + "," + str(gi.record_by_name(ip)["latitude"])
return geo
except:
pass代码相应的简单,和一般的Python代码也没有啥区别。这里一些用户自定义函数,在函数的最前面有一个outputSchema,用于返回输出的结果。
Step 4: 展示数据到地图上
现在,我们终于可以将数据转化到可视化界面了。开始之前,我们需要几个库
- jquery 地球人都知道
- elasticsearch.jquery即用于搜索功能
- ammap用于制作交互地图。
添加这些库到html文件里:
<script src="bower_components/jquery/dist/jquery.js"></script>
<script src="bower_components/elasticsearch/elasticsearch.jquery.js"></script>
<script src="bower_components/ammap/dist/ammap/ammap.js" type="text/javascript"></script>
<script src="bower_components/ammap/dist/ammap/maps/js/worldLow.js" type="text/javascript"></script>
<script src="bower_components/ammap/dist/ammap/themes/black.js" type="text/javascript"></script>
<script src="scripts/latlng.js"></script>
<script src="scripts/main_ammap.js"></script>生成过程大致如下所示:
- 获取不同国家的全名,用于解析出全名,如US -> “United States”
- 查找ElasticSearch搜索引擎中的数据,并计算访问量
- 再将数据渲染到地图上
对应的main文件如下所示:
var client = new $.es.Client({
hosts: 'localhost:9200'
});
// 创建ElasticSearch搜索条件
var query = {
index: 'nginx',
type: 'log',
size: 200,
body: {
query: {
query_string: {
query: "*"
}
},
aggs: {
2: {
terms: {
field: "country",
size: 200,
order: {
_count: "desc"
}
}
}
}
}
};
// 获取到country.json后生成数据
$(document).ready(function () {
$.ajax({
type: "GET",
url: "country.json",
success: function (data) {
generate_info(data)
}
});
});
// 根据数据中的国家名,来计算不同国家的访问量大小。
var generate_info = function(data){
var mapDatas = [];
client.search(query).then(function (results) {
$.each(results.aggregations[2].buckets, function(index, bucket){
var mapData;
$.each(data, function(index, country){
if(country.name.toLowerCase() === bucket.key) {
mapData = {
code: country.code,
name: country.name,
value: bucket.doc_count,
color: "#eea638"
};
}
});
if(mapData !== undefined){
mapDatas.push(mapData);
}
});
create_map(mapDatas);
});
};
var create_map = function(mapData){
var map;
var minBulletSize = 3;
var maxBulletSize = 70;
var min = Infinity;
var max = -Infinity;
AmCharts.theme = AmCharts.themes.black;
for (var i = 0; i < mapData.length; i++) {
var value = mapData[i].value;
if (value < min) {
min = value;
}
if (value > max) {
max = value;
}
}
map = new AmCharts.AmMap();
map.pathToImages = "bower_components/ammap/dist/ammap/images/";
map.areasSettings = {
unlistedAreasColor: "#FFFFFF",
unlistedAreasAlpha: 0.1
};
map.imagesSettings = {
balloonText: "<span style='font-size:14px;'><b>[[title]]</b>: [[value]]</span>",
alpha: 0.6
};
var dataProvider = {
mapVar: AmCharts.maps.worldLow,
images: []
};
var maxSquare = maxBulletSize * maxBulletSize * 2 * Math.PI;
var minSquare = minBulletSize * minBulletSize * 2 * Math.PI;
for (var i = 0; i < mapData.length; i++) {
var dataItem = mapData[i];
var value = dataItem.value;
// calculate size of a bubble
var square = (value - min) / (max - min) * (maxSquare - minSquare) + minSquare;
if (square < minSquare) {
square = minSquare;
}
var size = Math.sqrt(square / (Math.PI * 2));
var id = dataItem.code;
dataProvider.images.push({
type: "circle",
width: size,
height: size,
color: dataItem.color,
longitude: latlong[id].longitude,
latitude: latlong[id].latitude,
title: dataItem.name,
value: value
});
}
map.dataProvider = dataProvider;
map.write("mapdiv");
};我们可以看到比较麻烦的地方就是生成地图上的数量点,也就是create_map函数。