
编码
在我们真正开始去写代码之前,我们可能会去考虑一些事情。怎么去规划我们的任务,如何去细分这个任务。
- 如果一件事可以自动化,那么就尽量去自动化,毕竟你是一个程序员。
- 快捷键!快捷键!快捷键!
- 使用可以帮助你快速工作的工具——如启动器。
不过不得不提到的一点是:你需要去考虑这个需求是不是一个坑的问题。如果这是一个坑,那么你应该尽早的去反馈这个问题。沟通越早,成本越低。
编码过程
整个编程的过程如下图所示:
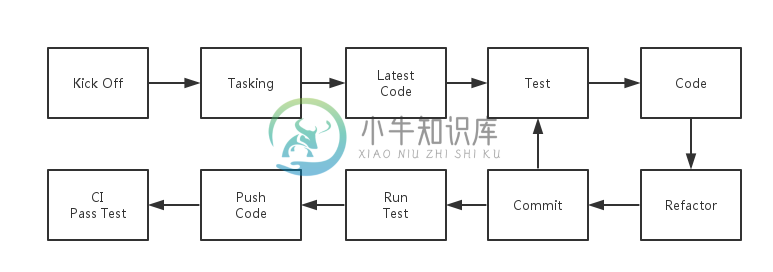
步骤如下所示:
- Kick Off。在这个步骤中,我们要详细地了解我们所需要做的东西、我们的验收条件是什么、我们需要做哪些事情。
- Tasking。简单的规则一下,我们需要怎么做。一般来说,如果是结对编程的话,还会记录下来。
- 最新的代码。对于使用 Git 来管理项目的团队来说,在一个任务刚开始的时候应该保证本地的代码是最新的。
- Test First。测试优先是一个很不错的实践,可以保证我们写的代码的健壮,并且函数尽可能小,当然也会有测试。
- Code。就是实现功能,一般人都知道。
- 重构。在我们实现了上面两步之后,我们还需要重构代码,使我们的代码更容易阅读、更易懂等等。
- 提交代码。这里的提交代码只是本地的提交代码,因此都提倡在本地多次提交代码。
- 运行测试。当我们完成我们的任务后,我们就可以准备 PUSH 代码了。在这时,我们需要在本地运行测试——以保证我们不破坏别人的功能。
- PUSH 代码。
- 等 CI 测试通过。如果这时候 CI 是挂的话,那么我们就需要再修 CI。这时其他的人就没有理由 PUSH 代码,如果他们的代码也是有问题的,这只会使情况变得愈加复杂。
不过,在最开始的时候我们要了解一下如何去搭建一个项目。
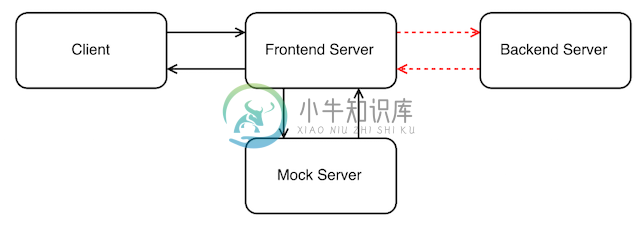
Web 应用的构建系统
构建系统(build system)是用来从源代码生成用户可以使用的目标的自动化工具。目标可以包括库、可执行文件、或者生成的脚本等等。
常用的构建工具包括 GNU Make、GNU autotools、CMake、Apache Ant(主要用于JAVA)。此外,所有的集成开发环境(IDE)比如 Qt Creator、Microsoft Visual Studio 和 Eclipse 都对他们支持的语言添加了自己的构建系统配置工具。通常 IDE 中的构建系统只是基于控制台的构建系统(比如 Autotool 和 CMake )的前端。
对比于 Web 应用开发来说,构建系统应该还包括应用打包(如 Java 中的 Jar 包,或者用于部署的 RPM 包)、源代码分析、测试覆盖率分析等等。
Web 应用的构建过程
在刚创建项目的时候,我们都会有一个完整的构建思路。如下图便是这样的一个例子:
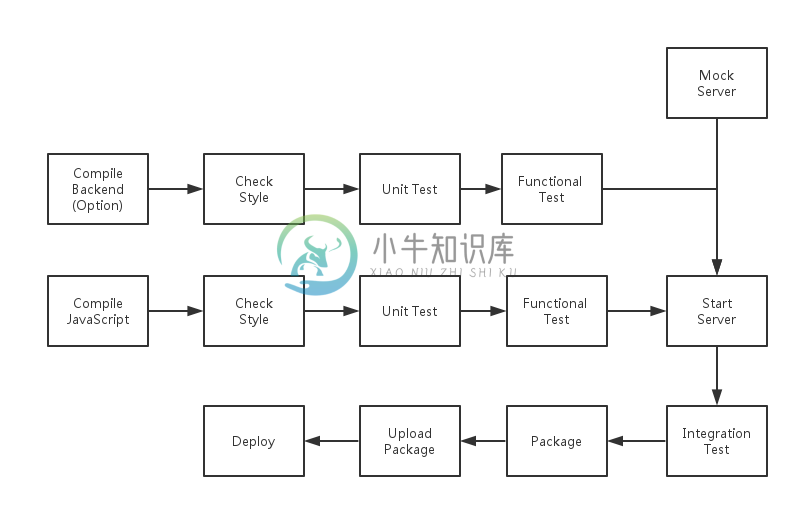
这是一个后台语言用的是 Java,前台语言用的是 JavaScript 项目的构建流程。
Compile。对于那些不是用浏览器的前端项目来说,如 ES6、CoffeeScript,他们还需要将代码编译成浏览器使用的 JavaScript 版本。对于 Java 语言来说,他需要一个编译的过程,在这个编译的过程中,会检查一些语法问题。
Check Style。通常我们会在我们的项目里定义一些代码规范,如 JavaScript 中的使用两个空格的缩进,Java 的 Checkstyle 中一个函数不能超过30行的限制。
单元测试。作为测试中最基础也是最快的测试,这个测试将集中于测试单个函数的是不是正确的。
功能测试。功能测试的意义在于,保证一个功能依赖的几个函数组合在一起也是可以工作的。
Mock Server。当我们的代码依赖于第三方服务的时候,我们就需要一个 Mock Server 来保证我们的功能代码可以独立地测试。
集成测试。这一步将集成前台、后台,并且运行起最后将上线的应用。接着依据于用户所需要的功能来编写相应的测试,来保证一个个的功能是可以工作的。
打包。对于部署来说,直接安装一个 RPM 包,或者 DEB 包是最方便的事。在这个包里会包含应用程序所需的所有二进制文件、数据和配置文件等等。
上传包。在完成打包后,我们就可以上传这个软件包了。
部署。最后,我们就可以在我们的线上环境中安装这个软件包。
Web 应用的构建实战
下面就让我们来构建一个简单的 Web 应用,来实践一下这个过程。在这里,我们要使用到的一个工具是 Gulp,当然对于 Grunt 也是类似的。
Gulp 入门指南
Gulp.js 是一个自动化构建工具,开发者可以使用它在项目开发过程中自动执行常见任务。Gulp.js 是基于 Node.js 构建的,利用 Node.js 流的威力,你可以快速构建项目并减少频繁的 IO 操作。Gulp.js 源文件和你用来定义任务的 Gulp 文件都是通过 JavaScript(或者 CoffeeScript )源码来实现的。
- 全局安装 gulp:
$ npm install --global gulp- 作为项目的开发依赖(devDependencies)安装:
$ npm install --save-dev gulp- 在项目根目录下创建一个名为 gulpfile.js 的文件:
var gulp = require('gulp');
gulp.task('default', function() {
// 将你的默认的任务代码放在这
});- 运行 gulp:
$ gulp默认的名为 default 的任务(task)将会被运行,在这里,这个任务并未做任何事情。接下来,我们就可以打造我们的应用的构建系统了。
代码质量检测工具
当 C 还是一门新型的编程语言时,还存在一些未被原始编译器捕获的常见错误,所以程序员们开发了一个被称作 lint 的配套项目用来扫描源文件,查找问题。
对应于不同的语言都会有不同的 lint 工具,在 JavaScript 中就有 JSLint。JavaScript 是一门年轻、语法灵活多变且对格式要求相对松散的语言,因此这样的工具对于这门语言来说比较重要。
2011年,一个叫 Anton Kovalyov 的前端程序员借助开源社区的力量弄出来了 JSHint,其思想基本上和 JSLint 是一致的,但是其有一下几项优势:
- 可配置规则,每个团队可以自己定义自己想要的代码规范。
- 对社区非常友好,社区支持度高。
- 可定制的结果报表。
下面就让我们来安装这个软件吧:
安装及使用
npm install jshint gulp-jshint --save-dev示例代码:
var jshint = require('gulp-jshint');
var gulp = require('gulp');
gulp.task('lint', function() {
return gulp.src('./lib/*.js')
.pipe(jshint())
.pipe(jshint.reporter('YOUR_REPORTER_HERE'));
});自动化测试工具
一般来说,自动测试应该从两部分考虑:
- 单元测试
- 功能测试
Mocha 是一个可以运行在 Node.js 和浏览器环境里的测试框架,
var gulp = require('gulp');
var mocha = require('gulp-mocha');
gulp.task('default', function () {
return gulp.src('test.js', {read: false})
// gulp-mocha needs filepaths so you can't have any plugins before it
.pipe(mocha({reporter: 'nyan'}));
});编译
对于静态型语言来说,编译是一个很重要的步骤。不过,对于动态语言来说也存在这样的工具。
动态语言的编译
可以说这类型的语言,是以我们常见的 JavaScript 为代表。
CoffeeScript 是一套 JavaScript 的转译语言,并且它增强了 JavaScript 的简洁性与可读性。
Webpack 是一款模块加载器兼打包工具,它能把各种资源,例如 JS(含JSX)、coffee、样式(含less/sass)、图片等都作为模块来使用和处理。
Babel 是一个转换编译器,它能将 ES6 转换成ES5,以便在较低版本的浏览器中正确运行。
打包
在 GNU/Linux 系统的软件包里通过包含了已压缩的软件文件集以及该软件的内容信息。常见的软件包有
- DEB。Debian 软件包格式,文件扩展名为 .deb
- RPM(原 Red Hat Package Manager,现在是一个递归缩写)。该软件包分为二进制包(Binary)、源代码包(Source)和 Delta 包三种。二进制包可以直接安装在计算机中,而源代码包将会由 RPM 自动编译、安装。源代码包经常以 src.rpm 作为后缀名。
- 压缩文档 tar.gz。通常是该软件的源码,故而在安装的过程中需要编译、安装,并且在编译时需要自己手动安装所需要依赖的软件。在软件仓库没有最新版本的软件时,tar.gz 往往是最好的选择。
由于这里的打包过程比较繁琐,就不介绍了。有兴趣的读者可以自己了解一下。
上传及发布包
上传包之前我们需要创建一个相应的文件服务器,又或者是相应的软件源。并且对于我们的产品环境的服务器来说,我们还需要指定好这个软件源才能安装这个包。
以 Ubuntu 为例,Ubuntu 里的许多应用程序软件包,是放在网络里的服务器上,这些服务器网站,就称作“源”,从源里可以很方便地获取软件包。
因而在这一步中,我们所需要做的事便是将我们打包完的软件上传到相应的服务器上。
Git 与版本控制
版本控制
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
虽然基于 Git 的工作流可能并不是一个非常好的实践,但是在这里我们以这个工作流做为实践来开展我们的项目。如下图所示是一个基于 Git 的项目流:
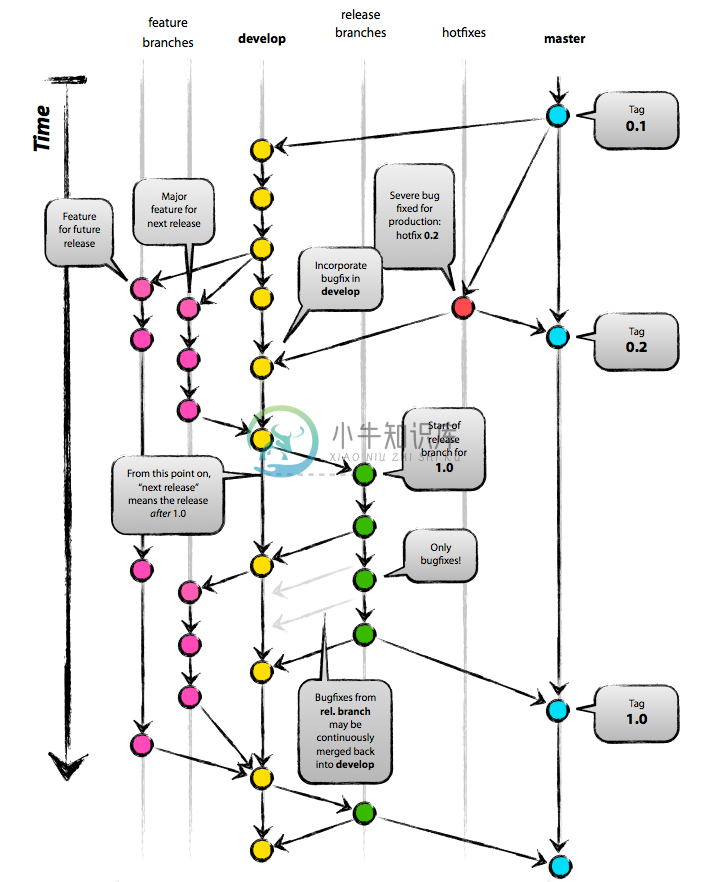
我们日常会工作在 “develop” 分支(那条线)上,通常来说每个迭代我们会发布一个新的版本,而这个新的版本将会直接上线到产品环境。那么上线到产品环境的这个版本就需要打一个版本 号——这样不仅可以方便跟踪我们的系统,而且当出错的时候我们也可以直接回滚到上一个版本。如果在上线的时候有些 Bug 不得不去修复,并且由于上线的新功能很重要,我们就需要一些 Hotfix。而从整个过程来看,版本控制起了一个非常大的作用。
不仅仅如此,版本控制的最大重要是在开发的过程中扮演的角色。通过版本管理系统,我们可以:
- 将某个文件回溯到之前的状态。
- 将项目回退到过去某个时间点。
- 在修改 Bug 时,可以查看修改历史,查出修改原因
- 只要版本控制系统还在,你可以任意修改项目中的文件,并且还可以轻松恢复。
常用的版本管理系统有 Git、SVN,但是从近年来看 Git 似乎更受市场欢迎。
Git
从一般开发者的角度来看,Git 有以下功能:
- 从服务器上克隆数据库(包括代码和版本信息)到单机上。
- 在自己的机器上创建分支,修改代码。
- 在单机上自己创建的分支上提交代码。
- 在单机上合并分支。
- 新建一个分支,把服务器上最新版的代码 fetch 下来,然后跟自己的主分支合并。
- 生成补丁(patch),把补丁发送给主开发者。
- 看主开发者的反馈,如果主开发者发现两个一般开发者之间有冲突(他们之间可以合作解决的冲突),就会要求他们先解决冲突,然后再由其中一个人提交。如果主开发者可以自己解决,或者没有冲突,就通过。
- 一般开发者之间解决冲突的方法,开发者之间可以使用 pull 命令解决冲突,解决完冲突之后再向主开发者提交补丁。
从主开发者的角度(假设主开发者不用开发代码)看,Git 有以下功能:
- 查看邮件或者通过其它方式查看一般开发者的提交状态。
- 打上补丁,解决冲突(可以自己解决,也可以要求开发者之间解决以后再重新提交,如果是开源项目,还要决定哪些补丁有用,哪些不用)。
- 向公共服务器提交结果,然后通知所有开发人员。
Git 初入
如果是第一次使用 Git,你需要设置署名和邮箱:
$ git config --global user.name "用户名"
$ git config --global user.email "电子邮箱"你可以在 GitHub 新建免费的公开仓库或在 Coding.net 新建免费的私有仓库。
按照 GitHub 的文档 或 Coding.net 的文档 配置 SSH Key,然后将代码仓库 clone 到本地,其实就是将代码复制到你的机器里,并交由 Git 来管理:
$ git clone git@github.com:username/repository.git
或
$ git clone git@git.coding.net:username/repository.git或使用 HTTPS 地址进行 clone:
$ git clone https://username:password@github.com/username/repository.git
或
$ git clone https://username:password@git.coding.net/username/repository.git你可以修改复制到本地的代码了( symfony-docs-chs 项目里都是 rst 格式的文档)。当你觉得完成了一定的工作量,想做个阶段性的提交:
向这个本地的代码仓库添加当前目录的所有改动:
$ git add .或者只是添加某个文件:
$ git add -p我们可以输入
$ git status来看现在的状态,如下图是添加之前的:
下面是添加之后 的
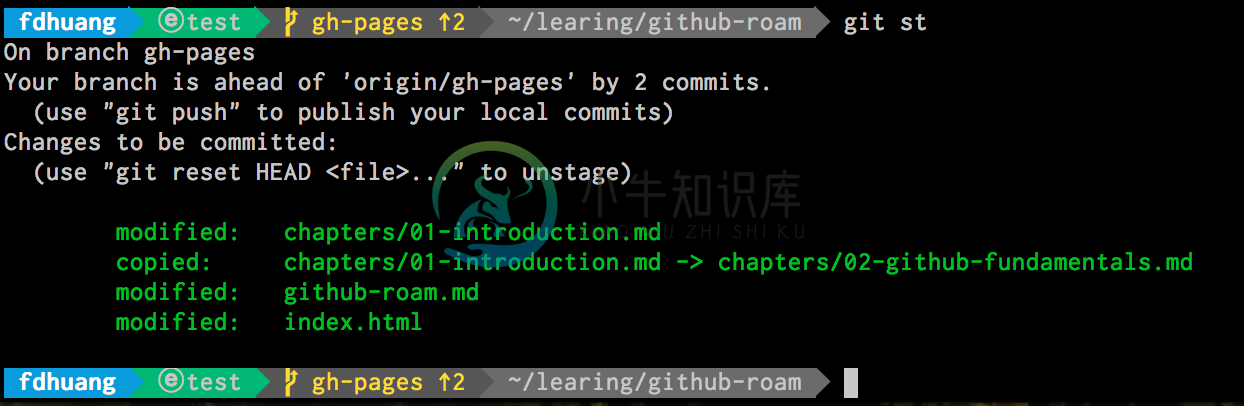
可以看到状态的变化是从黄色到绿色,即 unstage 到 add。
在完成添加之后,我们就可以写入相应的提交信息——如这次修改添加了什么内容 、这次修改修复了什么问题等等。在我们的工作流程里,我们使用 Jira 这样的工具来管理我们的项目,也会在我们的 Commit Message 里写上作者的名字,如下:
$ git commit -m "[GROWTH-001] Phodal: add first commit & example"在这里的GROWTH-001就相当于是我们的任务号,Phodal 则对应于用户名,后面的提交信息也会写明这个任务是干嘛的。
由于有测试的存在,在完成提交之后,我们就需要运行相应的测试来保证我们没有破坏原来的功能。因此,我们就可以PUSH我们的代码到服务器端:
$ git push这样其他人就可以看到我们修改的代码。
Tasking
初到 ThoughtWorks 时,Pair 时候总会有人教我如何开始编码,这应该也是一项基础的能力。结合日常,重新演绎一下这个过程:
- 有一个明确的实现目标。
- 评估目标并将其拆解成任务(TODO)。
- 规划任务的步骤(TODO)
- 学习相关技能
- 执行 Task,遇到难题就跳到第二步。
如何 Tasking 一本书
以本文的写作为例,细分上面的过程就是:
- 我有了一个中心思想——在某种意义上来说就是标题。
- 依据中心思想我将这篇文章分成了四小节。
- 然后我开始写四小节的内容。
- 直到完成。
而如果将其划分到一个编程任务,那么也是一样的:
- 我们想到做一个 xxx 的 idea。
- 为了这个 idea 我们需要分成几步,或者几层设计。
- 对于每一步,我们应该做点什么
- 我们需要学习怎样的技能
- 集成每一步的代码,就有了我们的系统。
现在让我们以这本书的写作过程为例,来看看这个过程是怎么发生的。
在计划写一本书的时候,我们有关于这本书主题的一些想法。正是一些想法慢慢地凝聚成一个稳定的想法,不过这不是我们所要讨论的重点。
当我们已经有了一本书的相关话题的时候,我们会打算去怎么做?先来个头脑风暴,在上面写满我们的一些想法,如这本书最开始划分了这七步:
- 从零开始
- 编码
- 上线
- 数据分析
- 持续交付
- 遗留系统
- 回顾与新架构
接着,依据我们的想法整理出几个章节。如本书最初的时候只有七个章节,但是我们还需要第一个章节来指引新手,因此变成了八个章节。对应于每一个章 节,我们都需要想好每一章里的内容。如在第一章里,又可以分成不同的几部分。随后,我们再对每一部分的内容进行任务划分,那么我们就会得到一个又一个的小 的章节。在每个小的章节里,我们都可以大概策划一下我们要写的内容。
然后我们就可以开始写这样的一本书——由一节节汇聚成一章,由一章一章汇聚成一本。
Tasking 开发任务
现在,让我们简单地来 Tasking 如何开发一个博客。作为一个程序员,如果我们要去开始一个博客系统的话,那么我们会怎么做?
- 先规划一下我们所需要的功能——如后台、评论、Social 等等,并且我们还应该设计我们博客的 Mockup。
- 随后我们就可以简单地设计一下系统的架构,如传统的前后端结合。
- 我们就可以进行技术选型了——使用哪个后端框架、使用哪个前端框架。
- 创建我们的 hello,world,然后开始进行一个功能的编码工作。
- 编码时,我们就需要不断地查看、添加测试等等。
- 完成一个个功能的时候,我们就会得到一个子模块。
- 依据一个个子模块,我们就可以得到我们的博客系统。
与我们日常开发一致的是:我们需要去划分任务的优先级。换句话来说,我们需要先实现我们的核心功能。
对于我们的博客系统来说,最主要的功能就是发博客、展示博客。往简单地说,一篇博客应该有这么基础的四部分:
- 标题
- 内容
- 作者
- 时间
- Slug
然后,我们就需要创建相应的 Model,根据这个 Model,我们就可以创建相应的控制器代码。再配置下路由,添加下页面。对于有些系统来说,我们就可以完成博客系统的展示了。
写代码只是在码字
编程这件事情实际上一点儿也不难,当我们只是在使用一个工具创造一些东西的时候,比如我们拿着电烙铁、芯片、电线等去焊一个电路板的时候,我们学的是如何运用这些工具。虽然最后我们的电路板可以实现相同的功能,但是我们可以一眼看到差距所在。
换个贴切一点的比喻,比如烧菜做饭,对于一个优秀的厨师和一个像我这样的门外汉而言,就算给我们相同的食材、厨具,一段时间后也许一份是诱人的美食,一份只能喂猪了——即使我模仿着厨师的步骤一步步地来,也许看上去会差不多,但是一吃便吃出差距了。
我们还做不好饭,还焊不好电路,还写不好代码,很大程度上并不是因为我们比别人笨,而只是别人比我们做了更多。有时候一种机缘巧遇的学习或者 bug 的出现,对于不同的人的编程人生都会有不一样的影响(ps:说的好像是蝴蝶效应)。我们只是在使用工具,使用的好与坏,在某种程序上决定了我们写出来的质 量。
写字便是如此,给我们同样的纸和笔(ps:减少无关因素),不同的人写出来的字的差距很大,写得好的相比于写得不好的 ,只是因为练习得更多。而编程难道不也是如此么,最后写代码这件事就和写字一样简单了。
刚开始写字的时候,我们需要去了解一个字的笔划顺序、字体结构,而这些因素相当于语法及其结构。熟悉了之后,写代码也和写字一样是简简单单的事。
学习编程只是在学造句
?多么无聊的一个标题
计算机语言同人类语言一样,有时候我们也许会感慨一些计算机语言是多么地背离我们的世界,但是他们才是真正的计算机语言。
计算机语言是模仿人类的语言,从 if 到其他,而这些计算机语言又比人类语言简单。故而一开始学习语言的时候我们只是在学习造句,用一句话来概括一句代码的意思,或者可以称之为函数、方法(method)。
于是我们开始组词造句,以便最后能拼凑出一整篇文章。
编程是在写作
?编程是在写作,这是一个怎样的玩笑?这是在讽刺那些写不好代码,又写不好文章的么
代码如诗,又或者代码如散文。总的来说,这是相对于英语而言,对于中文而言可不是如此。如果用一种所谓的中文语言写出来的代码,不能像中文诗一样,那么它就算不上是一种真正的中文语言。
那些所谓的写作逻辑对编程的影响
- 早期的代码是以行数算的,文章是以字数算的
- 代码是写给人看的,文章也是写给人看的
- 编程同写作一样,都由想法开始
- 代码同文章一样都可以堆砌出来(ps:如本文)
- 写出好的文章不容易,需要反复琢磨,写出好的代码不也是如此么
- 构造一个类,好比是构造一个人物的性格特点,多一点不行,少一点又不全
- 代码生成,和生成诗一样,没有情感,过于机械化
- 。。。
然而好的作家和一般的写作者,区别总是很大,对同一个问题的思考程度也是不同的。从一个作者到一个作家的过程,是一个不断写作不断积累的过程。而从一个普通的程序员到一个优秀的程序员也是如此,需要一个不断编程的过程。
当我们开始真正去编程的时候,我们还会纠结于“僧推月下门”还是“僧敲月下门”的时候,当我们越来越熟练就容易决定究竟用哪一个。而这样的“推敲”,无论在写作中还是在编程中都是相似的过程。
写作的过程真的就是一次探索之旅,而且它会贯穿人的一生。
因此:
编程只是在码字,难道不是么?
真正的想法都在脑子里,而不在纸上,或者 IDE 里。
内置索引与外置引擎
门户网站
让我们先来看看门户网站。
百科上说:
门户网站(英语:Web portal,又称入口网站,入门网站)指的是将不同来源的信息以一种整齐划一的形式整理、储存并呈现的网站
从某种意义上来说门户网站更适合那些什么都不知道,从头开始探索互联网的人。换句话说,这有点于类似我们在学第一门计算机语言——我们不需要去寻找什么,我们也不知道一些复杂的概念。
这时候我们只能随便的看一本别人推荐的书籍,读一读别人写的笔记,开始一点点构建我们的知识体系。
而在我们学习第二门计算机语言的时候,我们有了更多的诀窍——我们知道怎么去搜索。在我们的知识体系里,我们知道如何去搜索,这时我们就可以通过搜索引擎来学习。
百科上大致将搜索引擎分成了四部分:搜索器、索引器、检索器、用户接口。
- 搜索器:其功能是在互联网中漫游,发现和搜集信息。
- 索引器:其功能是理解搜索器所搜索到的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
- 检索器:其功能是根据用户的查询在索引库中快速检索文档,进行相关度评价,对将要输出的结果排序,并能按用户的查询需求合理反馈信息。
- 用户接口:其作用是接纳用户查询、显示查询结果、提供个性化查询项。
我想这部分大家都是有点印象的就不多介绍了(即:Ctrl + C, Ctrl + V)。
对于一个新手来说,使用搜索引擎的最大障碍就是——你知道问题,但是你不知道怎么搜索。这也是为什么,你会在那么多的博客、问答里,看到如何使用搜索引擎。
但是这并不能解决根本性问题——你需要知道你的问题是什么。顺便,推荐一本书叫做《你的灯亮着吗?》
内置索引与外置引擎
(ps: 为了和搜索引擎对应起来,这里就将内置门户改成内置索引。)
所以,再仔细回到上面的问题里。要成为一名可以完成任务的程序员,你就需要不断地构建你的门户网站。我们要学习 Web 开发,我们就需要对整个知识体系有一个好的理解。不断理解的过程中,我们就不断也添加了新的文档,构建新的索引。每遇到一个新的知识点,我们就开始重新生 成新的索引。
然后又会引入一个问题:
人的大脑如同一间空空的阁楼,要有选择地把一些家具装进去。
我们需要不断地整理一些新的技术,并且想方设法地忘记旧的知识。
有时,不得不说笔记和博客是这样一个很好的载体。在未来的某一天,我们可以重新挖掘这些技术,识别技术的旧有缺陷,发展出新的技术——水能载舟,亦能覆舟。
如何编写测试
写测试相比于写代码来说算是一件简单的事。多数时候,我们并不需要考虑复杂的逻辑。我们只需要按照我们的代码逻辑,对代码的行为进行覆盖。
需要注意的是——在不同的团队、工作流里,测试可能是会有不同的工作流程:
- 开发人员写单元测试、集成测试等等
- 测试团队通过界面来做黑盒测试
- 测试人员手动测试来测试功能
在允许的情况下,测试应该由开发人员来编写,并且是由底层开始写测试。为了更好地去测试代码,我们需要了解测试金字塔。
测试金字塔
测试金字塔是由 Mike Cohn 提出的,主要观点是:底层单元测试应多于依赖 GUI 的高层端到端测试。其结构图如下所示:

从结构上来说,上面的金字塔可以分成三部分:
- 单元测试。
- 服务测试
- UI 测试
从图中我们可以发现:单元测试应该要是最多的,也是最底层的。其次才是服务测试,最后才是 UI 测试。大量的单元测试可以保证我们的基础函数是正常、正确工作的。而服务测试则是一门很有学问的测试,不仅仅只在测试我们自己提供的服务,也会测试我们依 赖第三方提供的服务。在测试第三方提供的服务时,这就会变成一件有意思的事了。除此还有对功能和 UI 的测试,写这些测试可以减轻测试人员的工作量——毕竟这些工作量转向了开发人员来完成。
单元测试
单元测试是针对程序模块(软件设计的最小单位)来进行正确性检验的测试工作。它是应用的最小可测试部件。举个例子来说,下面是一个JavaScript 的函数,用于判断一个变量是否是一个对象:
var isObject = function (obj) {
var type = typeof obj;
return type === 'function' || type === 'object' && !!obj;
};这是一个很简单的功能,对应的我们会有一个简单的 Jasmine 测试来保证这个函数是正常工作的:
it("should be a object", function () {
expect(l.isObject([])).toEqual(true);
expect(l.isObject([{}])).toEqual(true);
});虽然这个测试看上去很简单,但是大量的基本的单元测试可以保证我们调用的函数都是可以正常工作的。这也相当于是我们在建设金字塔时用的石块——如果我们的石块都是经常测试的,那么我们就不怕金字塔因为石块的损坏而坍塌。
当单元测试达到一定的覆盖率,我们的代码就会变得更健壮。因为我们都需要保证我们的代码都是可测的,也意味着我们代码间的耦合度会降低。我们需要去 考虑代码的长度,越长的代码在测试的时间会变得越困难。这也就是为什么 TDD 会促使我们写出短的代码。如果我们的代码都是有测试的,单元测试可以帮助我们在未来重构我们的代码。
并且在很多没有文档或者文档不完整的开源项目中,了解这个项目某个函数的用法就是查看他的测试用例。测试用例(Test Case)是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求。这些测试用例可以让我们直观 地理解程序程序的 API。
服务测试
服务测试顾名思义便是对服务进行测试,而服务可以是有不同的类型,不同层次的测试。如第三方的 API 服务、我们程序提供的服务,虽然他们他应该在这一个层级上进行测试,但是对他们的测试会稍有不同。
对于第三方的提供的 API 服务或者其他类似的服务,在这一个层级的测试,我们都不会真实地去测试他们能不能工作——这些依赖性的服务只会在功能测试上进行测试。在这里的测试,我们 只会保证我们的功能代码是可以正常工作的,所以我们会使用一些虚假的 API 测试数据来进行测试。这一类提供 API 的 Mock Server 可以模拟被测系统外部依赖模块行为的通用服务。我们只要保证我们的功能代码是正常工作的,那么依赖他的服务也会是正常工作的。
而对于我们提供的服务来说,这一类的服务不一定是 API 的服务,还有可能是多个函数组成的功能性服务。当我们在测试这些服务的时候,实际上是在测试这个函数结合在一起是不是正常的。
一个服务可能依赖于多个函数,因而我们会发现服务测试的数量是少于单元测试的。
UI 测试
在传统的软件开发中,UI 测试多数是由人手动来完成的。而在稍后的章节里,你将会看到这些工作是可以由机器自己来完成的——当然,前提是我们要编写这些自动化测试的代码。需要注意 的是 UI 测试并不能完全替代手工的工作,一些测试还是应该由人来进行测试——如对 UI 的布局,在现阶段机器还没有审美意识呢。
自动化 UI 测试是一个缓慢的过程,在这个过程里我们需要做这么几件事:
- 运行起我们的网站——这可能需要几分钟。
- 添加一些 Mock 的数据,以使网站看上去正常——这也需要几分钟到几十分钟的时间。
- 开始运行测试——在一些依赖于网络的测试中,运行完一个测试可能会需要几分钟。尽管可以并行运行测试,但是一个测试几分钟算到最后就会累积成很长的时间。
所以,你会发现这是一个很长的测试过程。尽可能地将这个层级的测试往下层级移,就会尽可能的节省时间。一个 UI 测试需要几分钟,但是一个单元测试可能不到1秒。这就意味着,这样的测试下移可以节省上百个数量级的时间。
如何测试
现在问题来了,我们应该怎么去写测试?换句话来说,我要测什么?这是一个很难的问题,这足够可以以一本书的幅度来说明这个问题。这个问题也需要依赖于不同的实践,不同的时候我们可能对问题的看法都有不同。
编写测试的过程大致可以分成下面的几个步骤:
- 了解测试目的(Why)?即我们需要测什么,我们是为了什么而编写的测试。
- 我们要测哪些内容(What)?即测试点,我们即要从功能点上出发来寻找需要我们测试的点,在不同的条件下这个测试点是不一样的。
- 我们要如何进行测试(How)?我们要使用怎么样的方法进行测试?
测试目的
我们在上面提到过的测试金字塔,也表明了我们在每个层级要测试的目的是不一样的。
在单元测试这一层级,因为我们所测试的是每一个函数,这些函数没有办法构成完整的功能。这时候我们就只是用于简简单单的测试函数本身的功能,没有太多的业务需求。
而对于服务这一层级,我们所要测试的就是一个完整的功能。对于以 API 为主的项目来说,实际上就是在测返回结果是否是正确的。
最后 UI 这一层级,我们所需要测试的就是一个完整的功能。用户操作的时候应该是怎样的,那么我们就应该模仿用户的行为来测试。这是一个完整的业务需求,也可以称之为验证测试。
测试点
在了解完我们要测试的目的之后,我们要测试的点也变得很清晰。即在单元测试测试我们的函数的功能,在我们的服务测试我们的服务,在我们的 UI测试测试业务。
而这些都理想的情况,当系统由于业务的原因不得不耦合的时候。究竟是单元测试还是功能测试,这是一个特别值得思考的问题。如果一个功能既可以在单元 测试里测,又可以在服务测试里测,那么我们要测试哪一个?或者说我们应该把两个都测一遍?而如果是花费时间更长的 UI 测试呢?这样做是不是会变得不划算。
如何写测试代码
先让来们来简单地看一下测试用例,然后再让我们看看一般情况下我们是如何写测试代码的。下面的代码是一个用Python写的测试用例:
class HomepageTestCase(LiveServerTestCase):
def setUp(self):
self.selenium = webdriver.Firefox()
self.selenium.maximize_window()
super(HomepageTestCase, self).setUp()
def tearDown(self):
self.selenium.quit()
super(HomepageTestCase, self).tearDown()
def test_can_visit_homepage(self):
self.selenium.get(
'%s%s' % (self.live_server_url, "/")
)
self.assertIn("Welcome to my blog", self.selenium.title)在上面的代码里主要有三个方法,setUp()、tearDown()和 test_can_visit_homepage()。在这三个方法中起主要作用的是 test_can_visit_homepage()方法。而 setUp() 和 tearDown() 是特殊的方法,分别在测试方法开始之前运行和之后运行。同时,在这里我们也用这两个方法来打开和关闭浏览器。
而在我们的测试方法 test_can_visit_homepage() 里,主要有两个步骤:
- 访问首页
- 验证首页的标题是“Welcome to my blog”
大部分的测试代码也是以如何的流程来运行着。有一点需要注意的是:一般来说函数名就表示了这个测试所要做测试的事情,如这里就是测试可以访问首页。
如上所示的测试过程称为“四阶段测试”,即这个过程分为如下的四个阶段:
- Setup。在这个阶段主要是做一些准备工作,如数据准备和初始化等等,在上面的 setup 阶段就是用 selenium 启动了一个 Firefox 浏览器,然后把窗口最大化了。
- Execute。在执行阶段就是做好验证结果前的工作,如我们在测试注册的时候,那么这里就是填写数据,并点击提交按钮。在上面的代码里,我们只是打开了首页。
- Verify。在验证阶段,我们所要做的就是验证返回的结果是否和我们预期的一致。在这里我们还是使用和单元测试一样的 assert 来做断言,通过判断这个页面的标题是“Welcome to my blog”,来说明我们现在就是在首页里。
- Tear Down。就是一些收尾工作啦 ,比如关闭浏览器、清除测试数据等等。
Tips
需要注意的几点是:
- 从运行测试速度上来看,三种测试的运行速度是呈倒金字塔结构。即,单元测试跑得最快,开发速度也越快。随后是服务测试,最后是 UI 测试。
- 即使现在的 UI 测试跑得非常快,但是随着时间的推移,UI 测试会越来越多。这也意味着测试来跑得越来越久,那么人们就开始不想测试了。在我们之前的项目里,运行完所有的测试大概接近一个小时,我们开始在会议会争论这些测试的必要性,也在想方设法减少这些测试。
- 如果一个测试可以在最底层写,那么就不要在他的上一层写了,因为他的运行速度更快。
参考书籍:
- 《优质代码——软件测试的原则、实践与模式》
- 《Python Web 开发: 测试驱动开发方法》
测试替身
测试替身(Test Double)是一个非常有意思的概念。
有时候对被测系统(SUT)进行测试是很困难的,因为它依赖于其他无法在测试环境中使用的组件。这有可能是因为这些组件不可用,它们不会返回测试所 需要的结果,或者执行它们会有不良副作用。在其他情况下,我们的测试策略要求对被测系统的内部行为有更多控制或更多可见性。 如果在编写测试时无法使用(或选择不使用)实际的依赖组件(DOC),可以用测试替身来代替。测试替身不需要和真正的依赖组件有完全一样的的行为方式;他 只需要提供和真正的组件同样的 API 即可,这样被测系统就会以为它是真正的组件! ——Gerard Meszaros
当我们遇到一些难以测试的方法、行为的时候,我们就一些特别的方式来帮助我们测试。Mock 和 Stub 就是常见的两种方式:
- Stub 是一种状态确认,它用简单的行为来替换复杂的行为
- Mock 是一种行为确认,它用于模拟其行为
通俗地来说:Stub 从某种程度上来说,会返回我们一个特定的结果,用代码替换来方法;而 Mock 只是确保这个方法被调用。
Stub
Stub 从字面意义上来说是存根,存根可以理解为我们保留了一些预留的结果。这个时候我们相当于构建了这样一个特殊的测试场景,用于替换诸如网络或者 IO 调度等高度不可预期的测试。如当我们需要去验证某个 API 被调用并返回了一个结果,举例在最小物联网系统设计中返回的 json,我们可以在本地构建一个
[{"id":1,"temperature":14,"sensors1":15,"sensors2":12,"led1":1}]的结果来当我们预期的数据,也就是所谓的存根。那么我们所要做的也就是解析 json,并返回预期的结果。当我们依赖于网络时,此时测试容易出现问题。
Mock
Mock 从字面意义上来说是模仿,也就是说我们要在本地构造一个模仿的环境,而我们只需要验证我们的方法被调用了。
var Foo = function(){};
Foo.prototype.callMe = function() {};
var foo = mock( Foo );
foo.callMe();
expect( foo.callMe ).toHaveBeenCalled();测试驱动开发
测试驱动开发是一个很“古老”的程序开发方法,然而由于国内开发流程的问题——即开发人员负责功能的测试,导致这么好的一项技术没有在国内推广。
红-绿-重构
测试驱动开发的主要过程是: 红 —> 绿 -> 重构
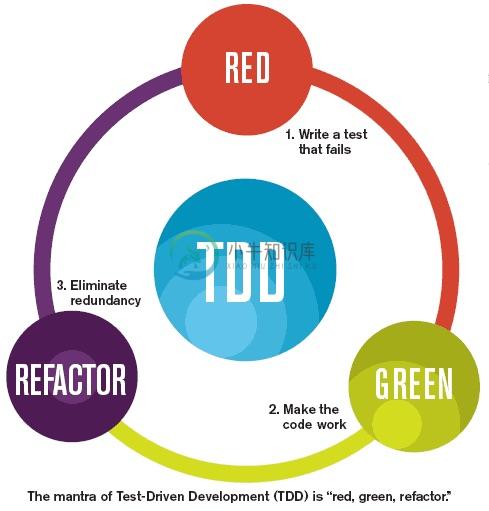
- 先写一个失败的单元测试。即我们并没有实现这个方法,但是已经有了这个方法的测试。
- 让测试通过。实现简单的代码来保证测试通过,就算我们用一些作弊的方法也是可以的。我们写的是功能代码,那么我们应该提交代码,因为我们已经实现了这个功能。
- 重构,并改进功能代码,让它变得更加合理。
TDD 有助于我们将问题分解成更小的部分,再一点点的添加我们所需要的业务代码。随着这个过程的不断进行,我们会发现我们已经接近完成我们的功能代码了。并且到了最后,我们会发现我们的代码都会被测试到。
虽然说起来很简单,但是真正实现起来并不是那么容易。于我而言我只会在我自己造的一些轮子中使用 TDD。因为这个花费大量的时间,通常来说测试代码和功能代码的比例可能是1:1,或者是2:1等等。在自己创建的一些个人应用,如博客中,我不需要与其 他人 Share 我的 Content。由于我使用的是第三方框架,框架本身的测试已经足够多,并且没有复杂的逻辑,我就没有对我的博客写测试。而在我写的一些框架里,我就会尽 量保证足够高的测试覆盖率,并且在适当的时候会去 TDD。
通常来说对于单元测试我会采用 TDD 的方式来进行,但是功能测试仍会选择在最后添加进去。主要的缘由是:在写 UI 的过程中,元素会发生变化。这一点和我们在写 Unit 的时候,有很大的区别。div + class 会使得我们思考问题的方式发生变化,我们需要去点击某个元素,并观察某个元素发生的变化。而多数时候,我们很难把握好一个页面最后的样子。
不得不说明的一点是,TDD 需要你对测试比较了解后,才容易使用它。从个人的感受来说,TDD 在一开始是一件很难的事。
测试先行
对于写测试的人来说,测试先行有点难以理解,而对于不写测试的人来说,就更难以理解。这里假定你已经开始写测试了,因为对于不写测试的人来说,写测试就是一件难以理解的事。既然我们都要写测试,那么为什么我们就不能先写测试呢?或者说为什么后写测试存在一些问题?
依据 J.Timothy King 所总结的《测试先行的12个好处》:
- 测试可证明你的代码是可以解决问题的
- 一面写单元测试,一面写实现代码,这样感觉更有兴趣
- 单元测试也可以用于演示代码
- 会让你在写代码之前做好计划
- 它降低了 Bug 修复的成本
- 可以得到一个底层模块的回归测试工具
- 可以在不改变现有功能的基础上继续改进你的设计
- 可以用于展示开发的进度
- 它真实的为程序员消除了工作上的很多障碍
- 单元测试也可以让你更好的设计
- 单元测试比代码审查的效果还要好
- 它比直接写代码的效率更高
但是在我个人的感觉里,比较喜欢的是: 写出可以测试的函数。这是一个一直困扰着我的难题,特别是当我的代码里存在很多条件的时候,在后期我编写的时候,难度越来越大。当我只有一个简单的 IF-ELSE 的时候,我的代码测试起来也很简单:
if (hour < 18) {
greeting = "Good day";
} else {
greeting = "Good evening";
}而当我有复杂的业务逻辑时,后写测试就会变成一场恶梦:
if (EchoesWorks.isObject(words)) {
var nextTime = that.parser.parseTime(that.data.times)[currentSlide + 1];
if (that.time < nextTime && words.length > 1) {
var length = words.length;
var currentTime = that.parser.parseTime(that.data.times)[currentSlide];
var time = nextTime - currentTime;
var average = time / length * 1000;
var i = 0;
document.querySelector('words').innerHTML = words[i].word;
timerWord = setInterval(function () {
i++;
if (i - 1 === length) {
clearInterval(timerWord);
} else {
document.querySelector('words').innerHTML = words[i].word;
}
}, average);
}
return timerWord;
} else {
document.querySelector('words').innerHTML = words;
}我们需要重新理清业务的逻辑,再依据这些逻辑来编写测试代码。而当我们已经忘记具体的业务逻辑时,我们已然无法写出测试。
思考
通常在我的理解下,TDD 是可有可无的。既然我知道了我要实现的大部分功能,而且我也知道如何实现。与此同时,对 Code Smell 也保持着警惕、要保证功能被测试覆盖。那么,总的来说 TDD 带来的价值并不大。
然而,在当前这种情况下,我知道我想要的功能,但是我并不理解其深层次的功能。我需要花费大量的时候来理解,它为什么是这样的,需要先有一些脚本来 知道它是怎么工作的。TDD 变显得很有价值,换句话来说,在现有的情况下,TDD 对于我们不了解的一些事情,可以驱动出更多的开发。毕竟在我们完成测试脚本之后,我们也会发现这些测试脚本成为了代码的一部分。
在这种理想的情况下,我们为什么不 TDD 呢?
参考资料
J.Timothy King 《Twelve Benefits of Writing Unit Tests First》
可读的代码
过去,我有过在不同的场合吐槽别人的代码写得烂。而我写的仅仅是比别人好一点而已——而不是好很多。
然而这是一件很难的事,人们对于同一件事物未来的考虑都是不一样的。同样的代码在相同的情景下,不同的人会有不同的设计模式。同样的代码在不同的情景下,同样的人会有不同的设计模式。在这里,我们没有办法讨论设计模式,也不需要讨论。
我们所需要做的是,确保我们的代码易读、易测试,看上去这样就够了,然而这也是挺复杂的一件事:
- 确保我们的变量名、函数名是易读的
- 没有复杂的逻辑判断
- 没有多层嵌套 (事不过三)
- 减少复杂函数的出现(如,不超过三十行)
- 然后,你要去测试它。这样你就知道需要什么,实际上要做到这些也不是一些难事。
只是首先,我们要知道我们要自己需要这些。对于没有太多编程经验的人,建议先从两个基本点做起:
- 命名
- 函数长度
首先要说的就是程序员认为最难的一个话题了——命名。
命名
命名是一个特别长的,也是特别忧伤的故事。我想作为一个程序员的你,也相当恐惧这件事。一个好的函数名、变量名应该包含着这个函数的信息,如这个函数是干什么的,或者这个函数是怎么来的,这个变量名存储的是什么。
正因为取名字是一件很重要的事,所以它也是一件很难的事。一个好的函数名、变量名应该能正确地表达出它的涵义。如你可以猜到下面的代码中的i是什么意思吗?
fruits = ['banana', 'apple', 'mango']
for i in fruits: # Second Example
print 'Current fruit :', i那如果换成下面的代码会不会更容易阅读呢?
fruits = ['banana', 'apple', 'mango']
for fruit in fruits: # Second Example
print 'Current fruit :', fruit而命令还存在于对函数的命名上,如我们可能会用 getNumber 来表示去获取一个数值,但是要知道这样的命名并不是在所有的语言中都可以这样用。如在 Java 中存在 getter 和 setter 这种模式,如下的代码所示:
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}如果我们是去取某个东西的数值,那么我们应该使用 retrieveNumber 这样的更具代表性的名字。
在《编写可读代码的艺术》也提到了这几点:
- 选择专业的词。最好是可以和业务相关的,它应该极具表现力。
- 避免像 tmp 和 retval 这样泛泛的名字。不得不提到的一点是,tmp 实在是一个有够烂的名字,将其变为 timeTemp 或者类似的会更直观。它只应该是名字中的一部分。
- 用具体的名字代替抽象的名字。
- 为名字赋予更多的信息。
- 名字应该有多长。
- 利用名字的格式来传递含义。
函数长度
函数是指一段在一起的、可以做某一件事儿的程序。
这就意味着从定义上来说,这段函数应该只做一件事——但是什么才是真正的一件事呢?实际上还是 TASKING,将一个复杂的过程一步步地分解成一个个的函数,每个函数只做他的名称对应的事。对于一个任务来说,他有一个稳定的过程,在这个过程中的每 一步都可以变成一个函数。
因此,长的代码意味着一件事——这个函数可能违反了单一职责原则,即这个类做了太多的事。通常来说,一个类,只有一个引起它变化的原因。当一个类有多个职责的时候,这些代码就容易耦合到一起了。
对于函数长度的控制是为了有效控制分支深度。如果我们用一个函数来实现一个复杂的功能,那么不仅仅在我们下次阅读的时间会花费大量的时间。而且如果 我们的代码没有测试的话,这些代码就会变得越来越难以理解。而在我们写这些函数的时候就没有测试,那么这个函数就会变得越来越难以测试,它们就会变成遗留 代码。
其他
虽然只想介绍上面的简单的两点,但是顺便在这里也提一下重复代码~~。
重复代码
在《重构》一书中首先提到的 Code Smell 就是重复代码(Duplicate Code)。重复代码看上去并不会影响我们的阅读体验,但是实际上会发生这样的事——重复的代码阅读体验越不好。
DRY(Don’t Repeat Yourself)原则是特别值得玩味的。当我们不断地偏执的去减少重复代码的时候,会导致复杂度越来越高。在适当的时候,由于业务发生变更,我们还需要去拆解这些不重复的代码。
代码重构
重构,一言以蔽之,就是在不改变外部行为的前提下,有条不紊地改善代码。
代码重构(英语:Code refactoring)指对软件代码做任何更动以增加可读性或者简化结构而不影响输出结果。在经历了一年多的工作之后,我平时的主要工作就是修 Bug。刚开始的时候觉得无聊,后来才发现修 Bug 需要更好的技术。有时候你可能要面对着一坨一坨的代码,有时候你可能要花几天的时间去阅读代码。而,你重写那几十行代码可能只会花上你不到一天的时间。但 是如果你没办法理解当时为什么这么做,你的修改只会带来更多的 Bug。修 Bug,更多的是维护代码。还是前人总结的那句话对:
写代码容易,读代码难。
假设我们写这些代码只要半天,而别人读起来要一天。为什么不试着用一天的时间去写这些代码,让别人花半天或者更少的时间来理解。
重命名
在上一节中,我们提到了命名的重要性,这里首先要说到的也就是重命名~。再看看《编写可读代码的艺术》也提到了这几点:
- 选择专业的词。最好是可以和业务相关的,它应该极具表现力。
- 避免像 tmp 和 retval 这样泛泛的名字。不得不提到的一点是,tmp 实在是一个有够烂的名字,将其变为 timeTemp 或者类似的会更直观。它只应该是名字中的一部分。
- 用具体的名字代替抽象的名字。
- 为名字赋予更多的信息。
- 名字应该有多长。
- 利用名字的格式来传递含义。
提取变量
先让我们来看看一个简单的情况:
if ($scope.goodSkills.indexOf('analytics') !== -1) {
skills.analytics = 5;
}在上面的代码里比较难以看懂的就是数字5,这时候你会怎么做?写一行注释?这里的5就是一个 Magic Number。
而实际上,最简单有效的办法就是把5提取成一个变量:
var LEVEL_FIVE = 5;
if ($scope.goodSkills.indexOf('analytics') !== -1) {
skills.analytics = LEVEL_FIVE;
}提炼函数
这个简单有效的方法就是为了对付之前太长的函数,抽取提炼函数出应该抽取出来的部分成为一个新的函数。引自《重构》一书的说法,短的精巧的函数有以下的特点:
- 如果每个函数的粒度都很小,那么函数被复用的机会就更大;
- 是这会让高层函数读起来就像一系列注释一样,容易理解;
- 是如果函数都是细粒度,那么函数的复写也会更加容易。
在提炼函数中我们所要做的就是——判断出原有的函数的意图,再依据我们的新意图来命名新的函数。然后判断依赖——变量值,处理这些变量。提取出函数,再对其测试。
这里只简单地对重构进行一些介绍,更多详细信息请参阅《重构:改善既有代码的设计》。
Intellij Idea 重构
下面简单地介绍一下,一些可以直接使用 IDE 就能完成的重构。这种重构可以用在日常的工作中,只需要使用 IDE 上的快捷键就可以完成了。
提炼函数
Intellij IDEA 带了一些有意思的快捷键,或者说自己之前不在意这些快捷键的存在。重构作为单独的一个菜单,显然也突显了其功能的重要性,说说提炼函数,或者说提出方法。
快捷键
Mac: alt+command+M
Windows/Linux: Ctrl+Alt+M
鼠标: Refactor | Extract | Method
重构之前
以重构一书代码为例,重构之前的代码
public class extract {
private String _name;
void printOwing(double amount){
printBanner();
System.out.println("name:" + _name);
System.out.println("amount" + amount);
}
private void printBanner() {
}
}重构
选中
System.out.println("name:" + _name);
System.out.println("amount" + amount);按下上述的快捷键,会弹出下面的对话框
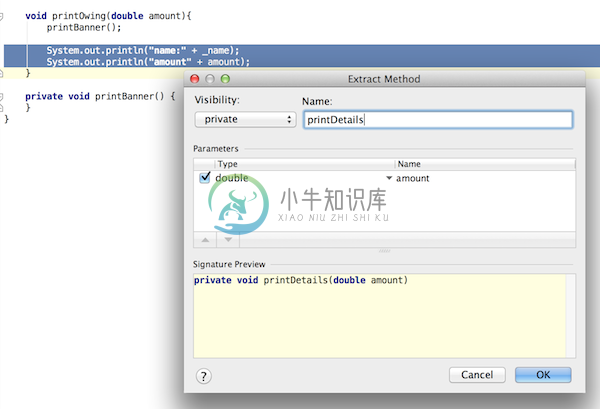
输入
printDetails那么重构就完成了。
重构之后
IDE 就可以将方法提出来
public class extract {
private String _name;
void printOwing(double amount){
printBanner();
printDetails(amount);
}
private void printDetails(double amount) {
System.out.println("name:" + _name);
System.out.println("amount" + amount);
}
private void printBanner() {
}
}重构
还有一种就以 Intellij IDEA 的示例为例,这像是在说其的智能。
public class extract {
public void method() {
int one = 1;
int two = 2;
int three = one + two;
int four = one + three;
}
}只是这次要选中的只有一行,
int three = one + two;以便于其的智能,它便很愉快地告诉你它又找到了一个重复
IDE has detected 1 code fragments in this file that can be replaced with a call to extracted method...便返回了这样一个结果
public class extract {
public void method() {
int one = 1;
int two = 2;
int three = add(one, two);
int four = add(one, three);
}
private int add(int one, int two) {
return one + two;
}
}然而我们就可以很愉快地继续和它玩耍了。当然这其中还会有一些更复杂的情形,当学会了这一个剩下的也不难了。
内联函数
继续走这重构一书的复习之路,接着便是内联,除了内联变量,当然还有内联函数。
快捷键
Mac: alt+command+N
Windows/Linux: Ctrl+Alt+N
鼠标: Refactor | Inline
重构之前
public class extract {
public void method() {
int one = 1;
int two = 2;
int three = add(one, two);
int four = add(one, three);
}
private int add(int one, int two) {
return one + two;
}
}在add(one,two)很愉快地按上个快捷键吧,就会弹出
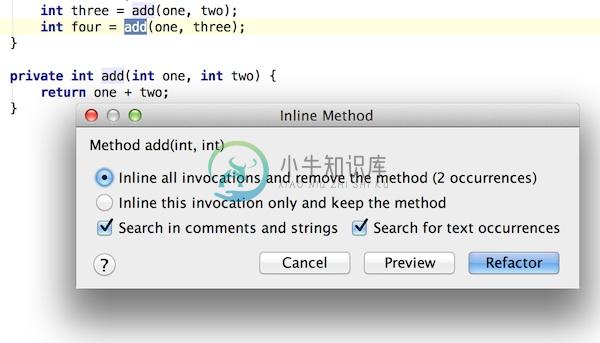
再轻轻地回车,Refactor 就这么结束了。。
Intellij Idea 内联临时变量
以书中的代码为例
double basePrice = anOrder.basePrice();
return (basePrice > 1000);同样的,按下Command+alt+N
return (anOrder.basePrice() > 1000);对于 python 之类的语言也是如此
def inline_method():
baseprice = anOrder.basePrice()
return baseprice > 1000查询取代临时变量
快捷键
Mac: 木有
Windows/Linux: 木有
或者: Shift+alt+command+T 再选择 Replace Temp with Query
鼠标: Refactor | Replace Temp with Query
重构之前
过多的临时变量会让我们写出更长的函数,变量不应该太多,以便使功能单一。这也是重构的另外的目的所在,只有函数专注于其功能,才会更容易读懂。
以书中的代码为例
import java.lang.System;
public class replaceTemp {
public void count() {
double basePrice = _quantity * _itemPrice;
if (basePrice > 1000) {
return basePrice * 0.95;
} else {
return basePrice * 0.98;
}
}
}重构
选中basePrice很愉快地拿鼠标点上面的重构
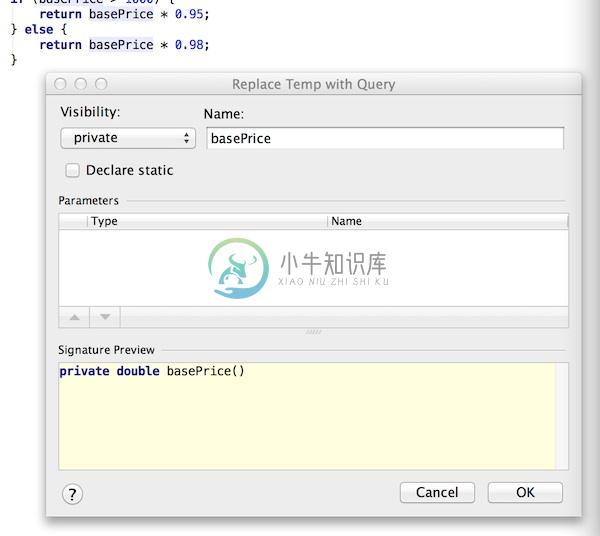
便会返回
import java.lang.System;
public class replaceTemp {
public void count() {
if (basePrice() > 1000) {
return basePrice() * 0.95;
} else {
return basePrice() * 0.98;
}
}
private double basePrice() {
return _quantity * _itemPrice;
}
}而实际上我们也可以
选中
_quantity * _itemPrice对其进行
Extrace Method选择
basePrice再Inline Method
在 Intellij IDEA 的文档中对此是这样的例子
public class replaceTemp {
public void method() {
String str = "str";
String aString = returnString().concat(str);
System.out.println(aString);
}
}接着我们选中aString,再打开重构菜单,或者
Command+Alt+Shift+T 再选中 Replace Temp with Query
便会有下面的结果:
import java.lang.String;
public class replaceTemp {
public void method() {
String str = "str";
System.out.println(aString(str));
}
private String aString(String str) {
return returnString().concat(str);
}
}重构到设计模式
模式和重构之间存在着天然联系,模式是你想到达的目的地,而重构则是从其他地方到达这个目的地的条条道路——Martin Fowler《重构》
过度设计与设计模式
过度设计和设计模式是两个很有意思的词语,这取决于我们是不是预先式设计。通过以往的经验我们很容易看到一个环境来识别一个模式。遗憾的是使用设计 模式依赖于我们整个团队的水平。对于了解设计模式的人来说,设计模式就是一种沟通语言。而对于了解一些设计模式的人来说,设计模式就是复杂的代码。
并且在软件迭代的过程中需求总是不断变化的,这就意味着我们对代码设计的越早,在后期失败的概率也就越大。设计会伴随着需求而发生变化,在当时看起来合理的设计,在后期就会因此而花费过多的代价。
而如果我们不进行一些设计,就有可能出现设计不足。这种情况可能出现于没有时间写出更好的代码的项目,在这些项目里由于一些原因出现加班等等的原因,使得我们没有办法写出更好的代码。同时,也有可能是因为参考项目的程序员在设计方面出现不足。
我们没有介绍设计模式的一个原因是——它需要有大量的编程经验,才可以让我们实现:重构到设计模式。