
回顾与架构设计
在刚开始接触架构设计的时候,对于这个知识点我觉得很奇怪。因为架构设计看上去是一个很复杂的话题,然而他是属于设计的一部分。如果你懂得什么是 美、什么是丑,那么我想你也是懂得设计的。而设计是一件很有意思的事——刚开始写字时,我们被要求去临摹别人的字体,到了一定的时候,我们就可以真正的去 设计。
自我总结
总结在某种意义上相当于自己对自己的反馈:
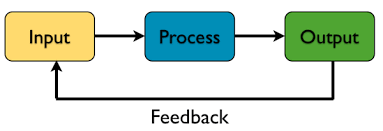
当我们向自己输入更多反馈的时候,我们就可以更好地调整我们的方向。它属于输出的一部分,而我们也在不断调整我们的输入的时候,我们也在导向更好地输出。
吾日三省吾身
为什么你不看不到自己的方向?
Retro
Retro,又可以称为回顾,它的目的是对团队的激励、改进。它的模式的特点就是让我们更关注于 Less Well,即不好的地方。当我们无法变得更好的时候,它可以帮助我们反观团队自身,即不要让现状变得更差,避免让破窗效应2难以发生。
在敏捷团队里,Retro 通常会发生一个迭代的结束与下一个迭代的开始之间,这看上去就是我们的除旧迎新。相信很多人都会对自我进行总结,随后改进。而 Retro 便是对团队进行改进,即发生了一些什么不好的事,而这些事可以变好,那么我们就应该对此进行改进。
Retro 是以整个团队为核心去考虑问题的,通常来说没有理由以个人为对象。因为敏捷回顾有一个最高指导原则,即:
无论我们发现了什么,考虑到当时的已知情况、个人的技术水平和能力、可用的资源,以及手上的状况,我们理解并坚信:每个人对自己的工作都已全力以赴。
下面就让我们来看看在一个团队里是如何 Retro 的。
Retro 的过程
它不仅仅可以帮助我们发现团队里的问题,也可以集思广益的寻找出一些合适的解决方案。Retro 的过程和我们之前说的数据分析是差不多的,如下图所示:

即:
- 设定会议目标。在会议最开始的时候我们就应该对会议的内容达成一种共识,我们要回顾的主题是啥,我们要回顾哪些内容。如果是一般性的迭代 Retro,那么我们的会议主题就很明显了。如果是针对某一个特定项目的 Retro,那么主题也很明显。
- Retro 的回顾。即回顾上一个 Retro 会议的 Action 情况,并进行一个简单的小结。
- 收集数据。收集数据需要依赖于我们收集数据的模式,要下面将会说到的四种基本维度,或者是雷达图等等。不同的收集数据的形式有不同的特别,团队里的每个人都应该好好去参与。
- 激发灵感。当我们寻找到团队中一个值得去庆祝的事,或者一个出了问题的事,我们就应该对这个问题进行讨论。并且对其展开了解、调查,让大家进一步看到问题,看到问题的根源。
- 决定做什么。现在我们已经做了一系列的事,最重要的来了,就是决定我们去做什么。我们应该对之前的问题做出怎样的改进。
- 总结和收尾。记录会议成果,更新文档等等。
三个维度
以我们为例,我们以下面的三个维度去进行 Retro:
- Well.
- Less Well.
- Suggestion
当然最后还会有一个Action:
- Action
该模式的特点是会让我们更多的关注 Less Well,关注我们做的不好的那些。

Well。我们在 Well 里记录一些让我们开心的事,如最近天气好、迭代及时完成、没有加班等等,这些事从理论上来说应该继续保持(KEEP)下去。
Less Well。关注于在这个迭代的过程中,发生了一些什么不愉快的事。一般来说,我们就会对 Less Well 加以细致的讨论,找出问题的根源,并试图找到一个解决方案。换句话来说,就是改变(CHANGE)。
Suggestion/Puzzle。如果我们可以直接找到一些建议,那么我们就可以直接提出来。并且如果我们对当前团队里的一些事情,有一些困惑那么也应该及早的提出来。
Action。当我们对一些事情有定论的时候,我们就会提出相应的 Action。这些 Action 应该有相应的人去执行,并且由团队来追踪。
架构模式
模式就是最好的架构。
架构的产生
在刚开始接触架构设计的时候,我买了几本书然后就开始学习了。我发现在这些书中都出现了一些相似的东西,如基本的分层设计、Pipe and Filters 模式、MVC 模式。然后,我开始意料到这些模式本身就是最好的架构。
MVC 模式本身也是基于分层而设计的,如下图是 Spring MVC 的请求处理过程:
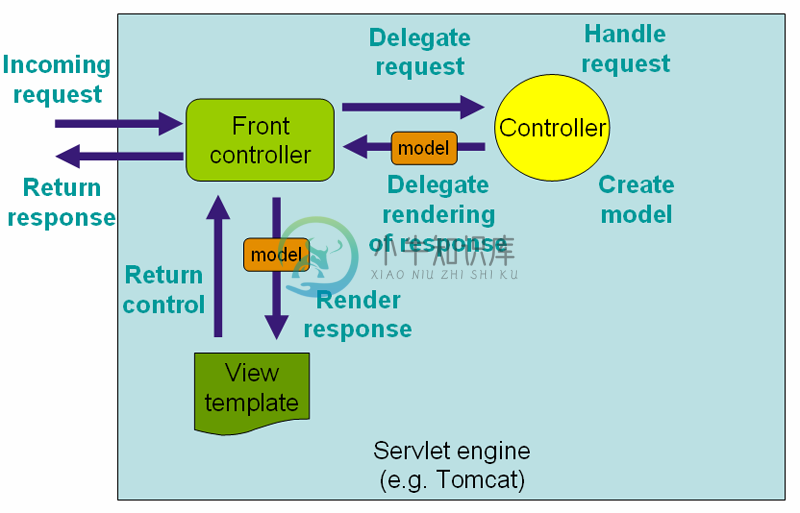
而这只是框架本身的架构,这一类也是我们预先设计好的框架。
在框架之上,我们会有自己本身的业务所带来的模式。如下图是我在网上搜罗到的一个简单的发送邮件的架构:
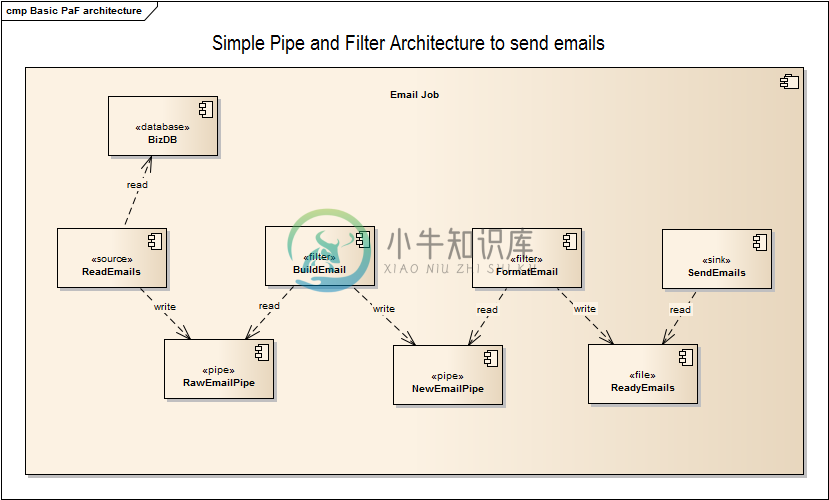
这样的模式则是在业务发展的过程中演进出来的。
预设计式架构
日常使用的框架多数是预先设计的构架,因为这些架构本身的目标是明确的。系统会围绕一定的架构去构建,并且在这个过程中架构会帮助我们更好地理解系统。如下图所示的是 Emacs 的架构:
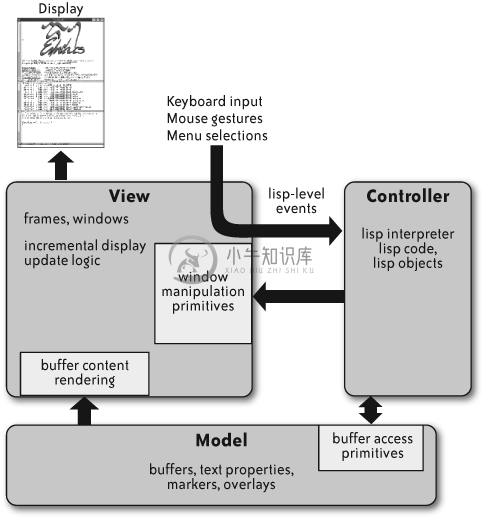
它采用的是交互式应用程序员应用广泛的模型-视图-控制器模式。
无论是瀑布式开发——设计好系统的框架,然后对系统的每个部分进行独立的完善和设计,最后系统再集成到一起。还是敏捷式开发——先做出 MVP,再一步步完善。它们都需要一定的预先式设计,只是传统的开发模式让两者看上去是等同的。
在过去由于 IT 技术变革小,新技术产生的速率也比较低,预先设计系统的架构是一种很不错的选择。然而,技术的发展趋势是越来越快,现有的设计往往在很短的一段时间里就需要推倒重来。
演进式架构:拥抱变化
演进式架构则是我们日常工作的业务代码库演进出来的。由于业务本身在不断发展,我们不断地演进系统的架构。在这样的模式下产生的架构系统会更加稳定,也更加优美。仅仅依赖于事先的设计,而不考虑架构在后期业务中的变化是一种不可取的设计模式。
这不并意味着不采用预先式设计,而是不一味去依靠原先系统的架构。
浮现式设计
设计模式不是一开始就有的,好的软件也不是一开始就设计成现在这样的,好的设计亦是如此。
导致我们重构现有系统的原因有很多,但是多数是因为原来的代码变得越来越不可读,并且重构的风险太大了。在实现业务逻辑的时候,我们快速地用代码实现,没有测试,没有好的设计。
而下图算是最近两年来想要的一个答案:
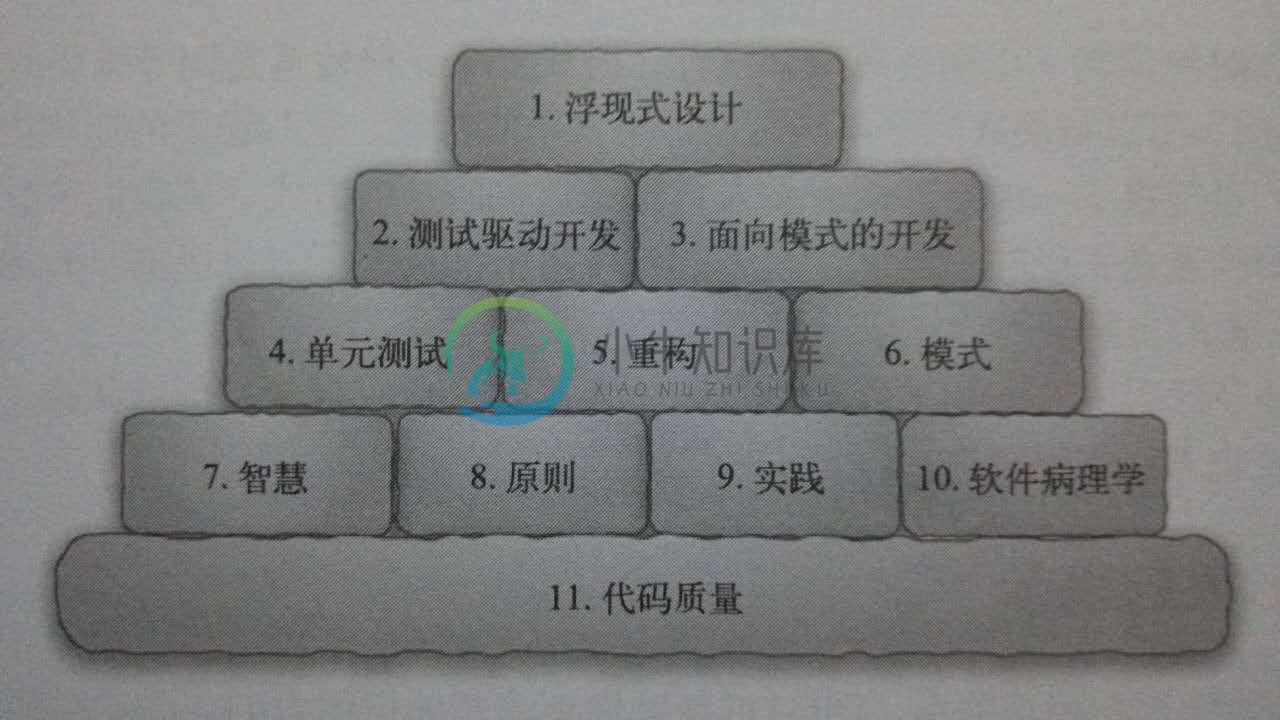
浮现式设计是一种敏捷技术,强调在开发过程中不断演进。软件本身就不应该是一开始就设计好的,它需要经历一个演化的过程。
意图导向
和 Growth 一样,在最开始的时候,我不知道我想要的是怎样的——我只有一个想法以及一些相对应的实践。接着我便动手开始做了,这是我的风格。不得不说这是结果导向编程,也是大部分软件开发采用的方法。
所以在一开始的时候,我们就有了下面的代码:
if (rating) {
$scope.showSkillMap = true;
skillFlareChild[skill.text] = [rating];
$scope.ratings = $scope.ratings + rating;
if (rating >= 0) {
$scope.learnedSkills.push({
skill: skill.text,
rating: rating
});
}
if ($scope.ratings > 250) {
$scope.isInfinite = true;
}
}代码在不经意间充斥着各种 Code Smell:
- Magic Number
- 超长的类
- 等等
重构
还好我们在一开始的时候写了一些测试,这让我们可以有足够的可能性来重构代码,而使其不至于变成遗留代码。这也是我们推崇的一些基本实践:
红 -> 绿 -> 重构
测试是系统不至于腐烂的一个后勤保障,除此我们还需要保持对于 Code Smell 的嗅觉。如上代码:
if ($scope.ratings > 250) {
$scope.isInfinite = true;
}上面代码中的“250”指的到底是?这样的数字怎么能保证别人一看代码就知道250到底是什么?
如下的代码就好一些:
var MAX_SKILL_POINTS = 250;
if ($scope.ratings > MAX_SKILL_POINTS) {
$scope.isInfinite = true;
}而在最开始的时候我们想不到这样的结果。最初我们的第一直觉都是一样的,然而只要我们保持着对 Code Smell 的警惕,情况就会发生更多的变化。
重构是区分普通程序员和专业程序员的一个门槛,也是练习得来的一个结果。
模式与演进
如果你还懂得一些设计模式,那么想来,软件开发这件事就变得非常简单——我们只需要理解好需求即可。
从一开始就使用模式,要么你是专家,要么你是在自寻苦恼。模式更多的是一些实现的总结,对于多数的实现来说,它们有着诸多的相似之处,可以使用相同的模式。
而在需求变化的过程中,一个设计的模式本身也是在不断的改变。如果我们还固执于原有的模式,那么我们就会犯下一个又一个的错误。
在适当的时候改变原有的模式,进行一些演进变显得更有意义一些。如果我们不能在适当的时候引进一些新的技术,那么旧有的技术就会不断累积。这些技术 债就会不断往下叠加,这个系统将会接近于崩塌。而我们在一开始所设定的一些业务逻辑,也会随着系统而逝去,这个公司似乎也要到尽头了。
而如果我们可以不断地演进系统——抽象服务、拆分模块等等。业务就可以在技术不断演进地过程中得以保留。
每个人都是架构师
每一个程序员都是架构师。平时在我们工作的时候,架构师这个 Title 都被那些非常有经历的开发人员占据着。然而,如果你喜欢刷刷 Github,喜欢做一些有意思的东西,那么你也将是一个架构师。
如何构建一个博客系统
如果你需要帮人搭建一个博客你先会想到什么?
先问一个问题,如果要让你搭建一个博客你会想到什么技术解决方案?
- 静态博客(类似于 GitHub Page)
- 动态博客(可以在线更新,如 WordPress)
- 半动态的静态博客(可以动态更新,但是依赖于后台构建系统)
- 使用第三方博客
这只是基本的骨架。因此如果只有这点需求,我们无法规划出整体的方案。现在我们又多了一点需求,我们要求是独立的博客,这样我们就把第4个方案去掉了。但是就现在的过程来说,我们还是有三个方案。
接着,我们就需要看看 Ta 需要怎样的博客,以及他有怎样的更新频率?以及他所能接受的价格?
先说说价格——从价格上来说,静态博客是最便宜的,可以使用 AWS S3 或者国内的云存储等等。从费用上来说,一个月只需要几块钱,并且快速稳定,可以接受大量的流量访问。而动态博客就贵了很多倍——我们需要一直开着这个服务 器,并且如果用户的数量比较大,我们就需要考虑使用缓存。用户数量再增加,我们就需要更多地服务器了。而对于半动态的静态博客来说,需要有一个 Hook 检测文章的修改,这样的 Hook 可以是一个客户端。当修改发生的时候,运行服务器,随后生成静态网页。最后,这个网页接部署到静态服务器上。
从操作难度上来说,动态博客是最简单的,静态博客紧随其后,半动态的静态博客是最难的。
整的性价比考虑如下:
| x | 动态博客 | 静态博客 | 半动态的静态博客 |
|---|---|---|---|
| 价格 | 几十到几百元 | 几元 | 依赖于更新频率 几元~几十元 |
| 难度 | 容易 | 稍有难度 | 难度稍大 |
| 运维 | 不容易 | 容易 | 容易 |
| 数据存储 | 数据库 | 无 | 基于 git 的数据库 |
现在,我们已经达成了一定的共识,有了几个方案可以供用户选择。而这时,我们并不了解进一步的需求,只能等下面的结果。
客户需要可以看到文章的修改变化,这时就去除了静态博客。现在还有第1和第3种方案可以选,考虑到第3种方案实现难度比较大,不易短期内实现。并且第3种方案可以依赖于第1种方案,就采取了动态博客的方案。
但是,问题实现上才刚刚开始。
我们使用怎样的技术?
作为一个团队,我们需要优先考虑这个问题。使用怎样的技术解决方案?而这是一个更复杂的问题,这取决于我们团队的技术组成,以及未来的团队组成。
如果在现有的系统中,我们使用的是 Java 语言。并不意味着,每个人都喜欢使用 Java 语言。因为随着团队的变动,做这个技术决定的那些人有可能已经不在这个团队里。即使那些人还在,也并不意味着我们喜欢在未来使用这个语言。当时的技术决策 都是在当时的环境下产生的,在现在看来很扯的技术决策,有可能在当时是最好的技术决策。
对于一个优秀的团队来说,不存在一个人对所有的技术栈都擅长的情况——除非这个团队所从事的业务范围比较小。在一个复杂的系统里,每个人都负责系统 的相应的一部分。尽管到目前为止并没有好的机会去构建自己的团队,但是也希望总有一天有这样的机会。在这样的团队里,只需要有一个人负责整个系统的架构。 其余的人可以在自己擅长的层级里构建自己的架构。因此,让我们再回到我们的博客中去,现在我们已经决定使用动态的博客。然后呢?
作为一个博客我们至少有前后台,这样我们可能就需要两个开发人员。
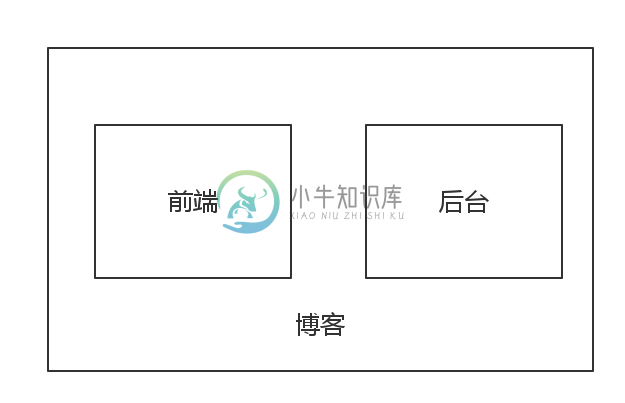
(PS:当然,我们也可以使用 React,但是在这里先让我们忽略掉这个框架,紧耦合会削弱系统的健壮性。)
接着,作为一个前端开发人员,我们还需要考虑的两个问题是:
- 我们的博客系统是否是单页面应用?。
- 要不要做成响应式设计。
第二个问题不需要和后台开发人员做沟通就可以做决定了。而第一个问题,我们则需要和后台开发人员做决定。单页面应用的天然优势就是:由于系统本身是 解耦的,他与后台模板系统脱离。这样在我们更换前端或者后台的时候,不需要去考虑使用何种技术——因为我们使用 API 作为接口。现在,我们决定做成单页面应用,那么我们就需要定义一个 API。之后,我们就可以决定在前台使用何种框架: AngularJS、Backbone、Vue.js、jQuery,接着我们的架构可以进一步完善:
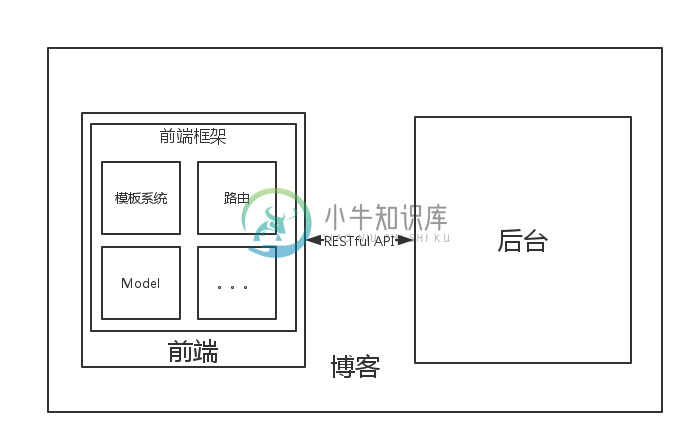
在这时,后台人员也可以自由地选择自己的框架、语言。后台开发人员只需要关注于生成一个 RESTful API 即可,而他也需要一个好的 Model 层来与数据库交付。
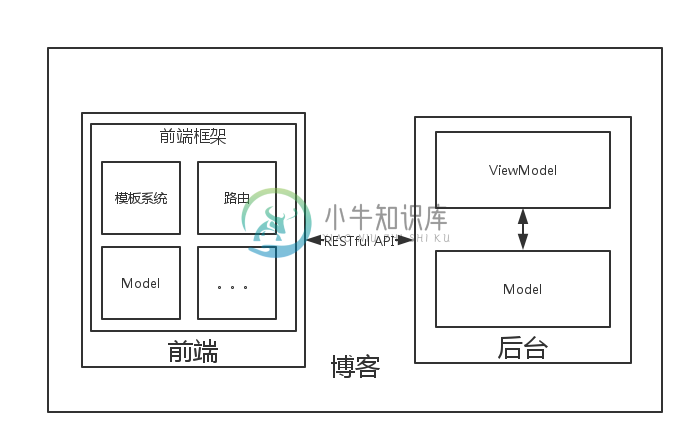
现在,我们似乎已经完成了大部分的工作?我们还需要:
- 部署到何处操作系统
- 使用何处数据库
- 如何部署
- 如何分析数据
- 如何测试
- 。。。
相信看完之前的章节,你也有了一定的经验了,也可以成为一个架构师了。
相关阅读资料
-《程序员必读之软件架构》
架构解耦
解耦是一件很有意思的过程,它也能反应架构的变迁。
从 MVC 到微服务
在我初识架构是什么的时候,我看到了 MVC 模式架构。这种模式是基于分层的结构,要理解起逻辑也很简单。这个模式如下图所示:
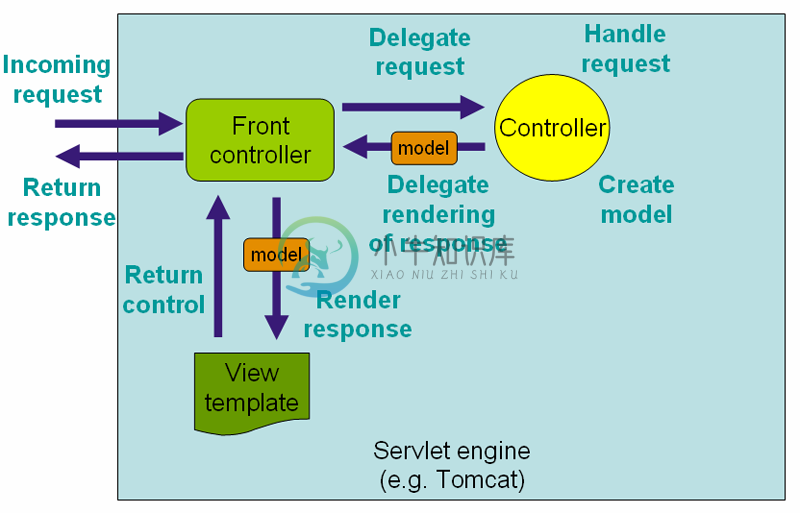
由我们的 Front controller 来处理由客户端(浏览器)发过来的请求,实际上这里的 Front controller 是 DispatcherServlet。 DispatcherServlet 负责将请求派发到特定的 handler,接着交由对应的Controller来处理这个请求。依据请求的内容,Controller 将创建相应 model。随后这个 model 将传到前端框架中渲染,最后再返回给浏览器。
但是这样的架构充满了太多的问题,如 view 与 controller 的紧密耦合、controller 粒度难以把控的问题等等。
Django MTV
我使用 Django 差不多有四年了,主要是用在我的博客上。与 MVC 模式一对比,我发现 Django 在分层上还是很有鲜明特性的:
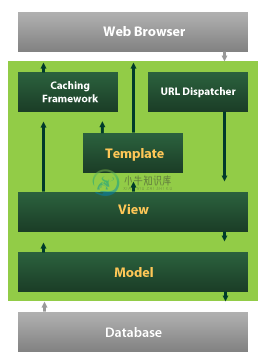
在 Django 中没有 Controller 的概念,Controller 做的事都交由 URL Dispatcher,而这是一个高级的 URL Dispatcher。它使用正则表达式匹配 URL,然后调用合适的 Python 函数。然后这个函数就交由相应的 View 层来处理,而这个 View 层则是处理业务逻辑的地方。处理完后,Model 将传到 Template 层来处理。
对比如下图如示:
| 传统的MVC架构 | Django 架构 |
|---|---|
| Model | Model(Data Access Logic) |
| View | Template(Presentation Logic) |
| View | View(Business Logic) |
| Controller | Django itself |
从上面的对比中,我们可以发现 Django 把 View 分层了。以 Django 对于 MVC 的解释来说,视图用来描述要展现给用户的数据。 而在 ROR 等其他的 MVC 框架中,控制器负责决定向用户展现哪些数据,而视图决定如何展现数据。
联想起我最近在学的 Scala 中的 Play 框架,我发现了其中诸多的相似之处:
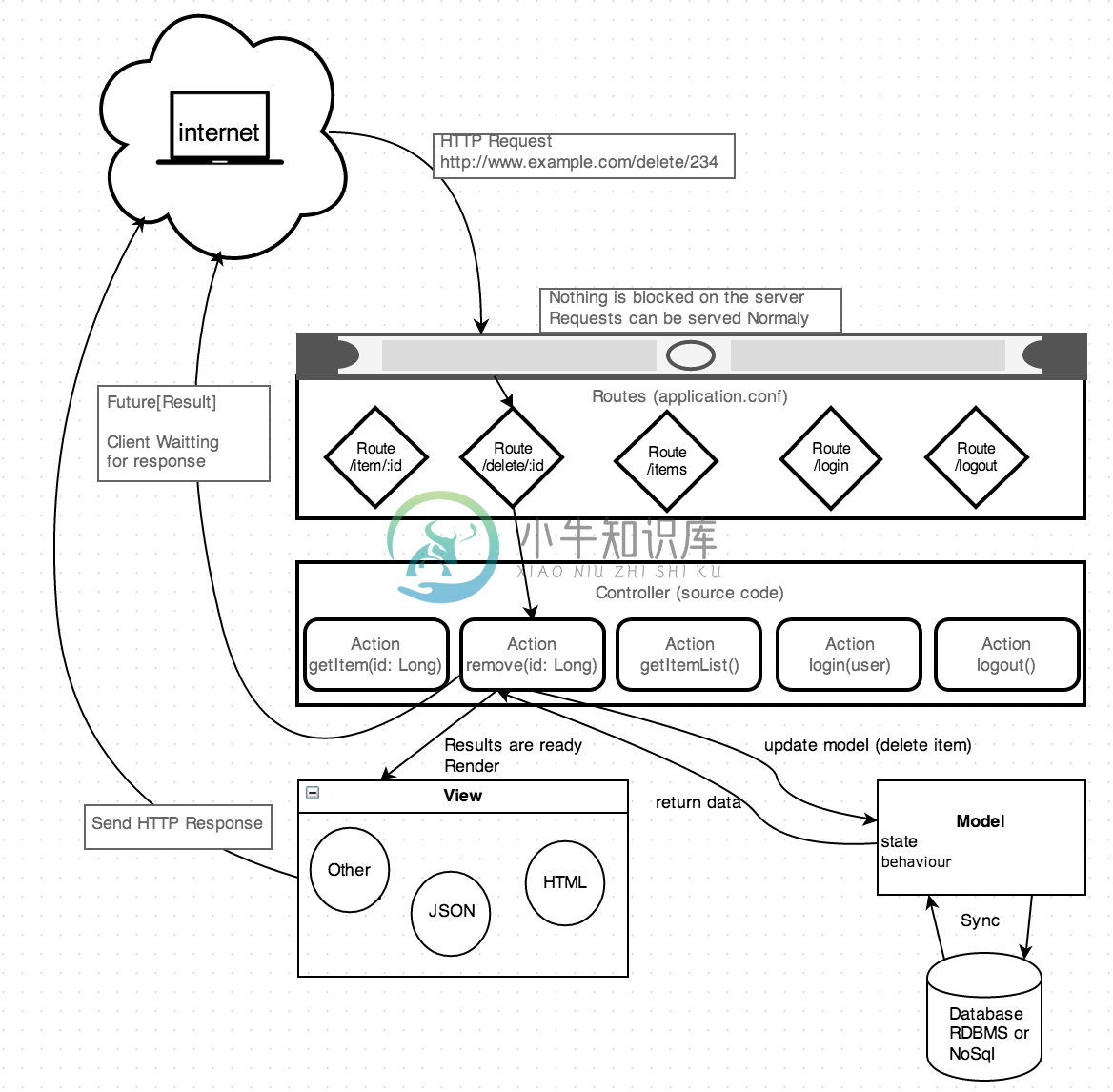
虽然在 Play 中,也有 Controller 的概念。但是对于 URL 的处理先交给了 Routes 来处理,随后再交给 Controller 中的函数来处理。
不过与一般 MVC 架构的最大不同之处,怕是在于 Django 的 APP 架构。Django 中有一个名为 APP 的概念,它是实现某种功能的Web 应用程序。如果我们要设计一个博客系统的话,那么在这个项目中,Blogpost 是一个 APP、评论是一个 APP、用户管理是一个 APP等等。每个 APP 之中,都会有自己的 Model、View 和 Controller。其架构如下图所示:
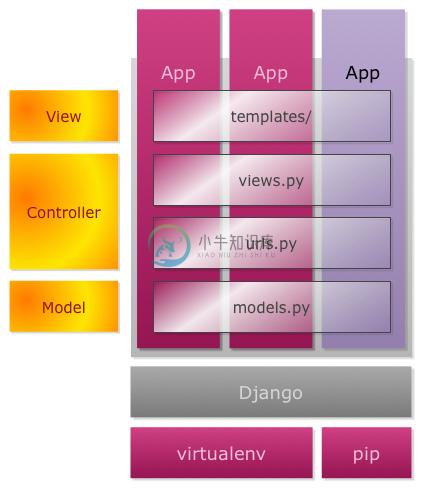
当我们需要创建一个新的功能的时候,我们只需要创建一个新的 APP 即可——为这个 APP 配置新的 URL、创建新的 Model 以及新的 View。如果功能上没有与原来的代码重复的话,那么这就是一个独立的 APP,并且我们可以将这个 APP 的代码 Copy/Paste 到一个新的项目中,并且不需要做修改。
与一般的 MVC 架构相比,我们会发现我们细化了这些业务逻辑原来的三层结构,会随着 APP 的数量发生变化。如果我们有三个 APP 的话,那么我们相当于有3*三层,但是他不是等于九层。这样做可以从代码上直接减少逻辑的思考,让我们可以更加集中注意力于业务实现,同时也利于我们后期 维护。
虽是如此,后来我意识到了这样的架构并没有太多的先进之处。而这实际上是一个美好但是不现实的东西,因为我们还是使用同一个数据库。
微服务与 Reactive
在微服务架构中,提倡将单一应用程序划分成一组小的服务,这些服务之间互相协调、互相配合。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通。每个服务都应该有自己独立的数据库来存储数据。
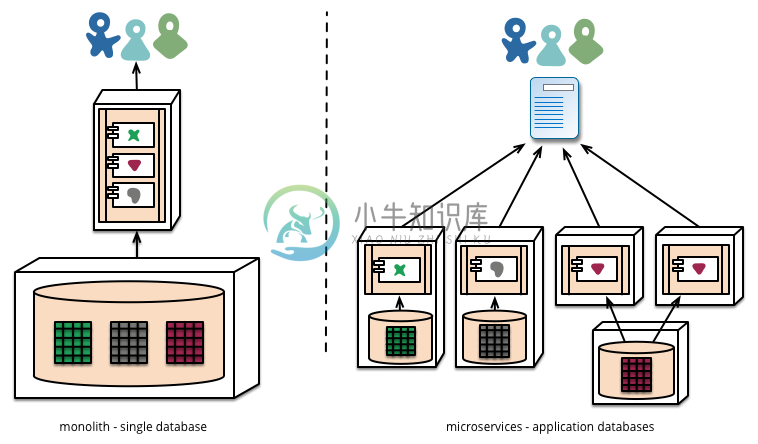
Django 从某种意义上有点接近微服务的概念,只是实际上并没有完全实现。因为它没有实现 Play 框架的异步请求机制。抱句话来说,应用很容易就会在调用 JDBC、Streaming API、HTTP 请求等一系列的请求中发生阻塞。
这些服务都是独立的,对于服务的请求也是独立的。使用微服务来构建的应用,不会因为一个服务的瘫痪让整个系统瘫痪。最后,这一个个的微服务将合并成整个系统。
我们将后台的服务变成微服务的架构,在前台使用 Reactive 编程,这样就可以结合两者的优势,解耦出更好的架构模式。然而,这其中还有一个让人不爽的问题,即数据库。如果我们使用多个数据库,那么维护成本也随着上 升。而如果我们可以在后台使用类似于微服务的 Django MTV 架构,并且它可以支持异步请求的话,并在前台使用 Reactive 来编程,是不是就会更爽一点?
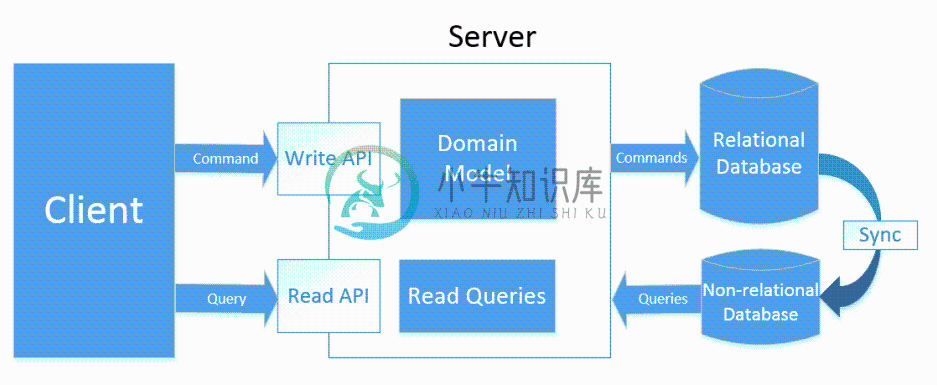
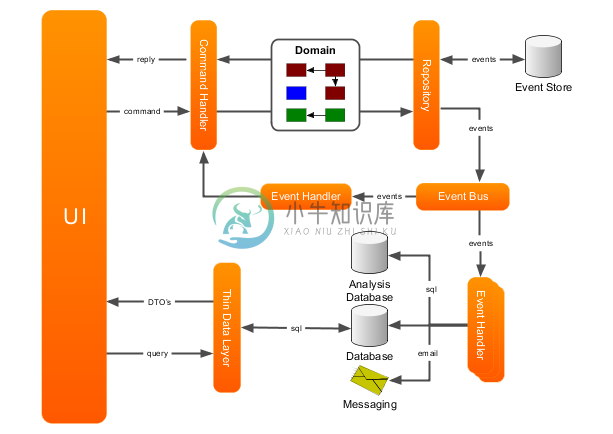
CQRS
对于复杂的系统来说,上面的做法做确实很不错。但是对于一个简单地系统来说,这样做是不是玩过火了?如果我们要设计一个博客系统的话,是不是可以考虑将 Write/Read 分离就可以了?
命令和查询责任分离 Command Query Responsibility Segregation(CQRS)是一种将系统的读写操作分离为两种独立模型的架构模式。
CQS
对于这个架构的深入思考是起源于之前在理解 DDD。据说在 DDD 领域中被广泛使用。理解 CQRS 可以从分离 Model 和 API 集合来处理读取和写入请求开始,即 CQS(Command Query Separation,命令查询分离)模式。CQS 模式最早由软件大师Bertrand Meyer(Eiffel语言之父,面向对象开-闭原则 OCP 提出者)提出。他认为,对象的行为仅有两种:命令和查询。
这个类型的架构如下图所示:
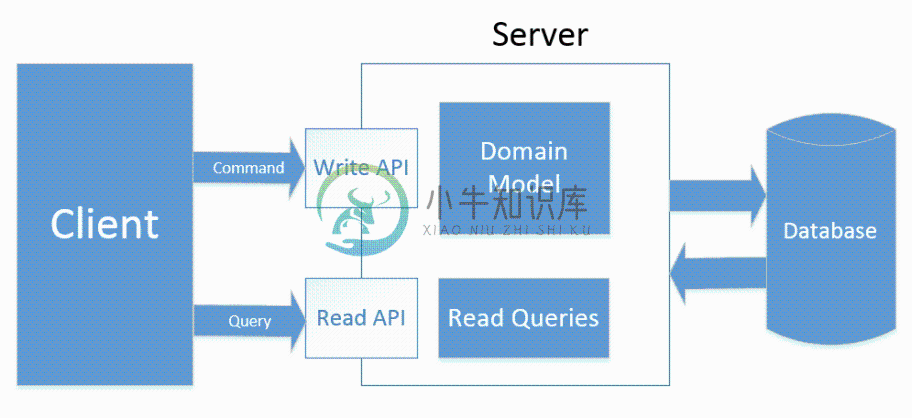
除了编写优化的查询类型,它可以让我们轻松换 API 的一部分读一些缓存机制,甚至移动读取 API 的请求到另一台服务器。
对于读取和写入相差不多的应用来说,这种架构看起来还是不错的。而这种架构还存在一个瓶颈问题,使用同一个 RDBMS。对于写入多、读取少的应用来说,这种架构还是存在着不合理性。
为了解决这个问题,人们自然是使用缓存来解决这个问题了。我们在我们的应用服务外有一个 HTTP 服务器,而在 HTTP 服务器之外有一个缓存服务器,用于缓存用户常驻的一些资源。如下图所示:
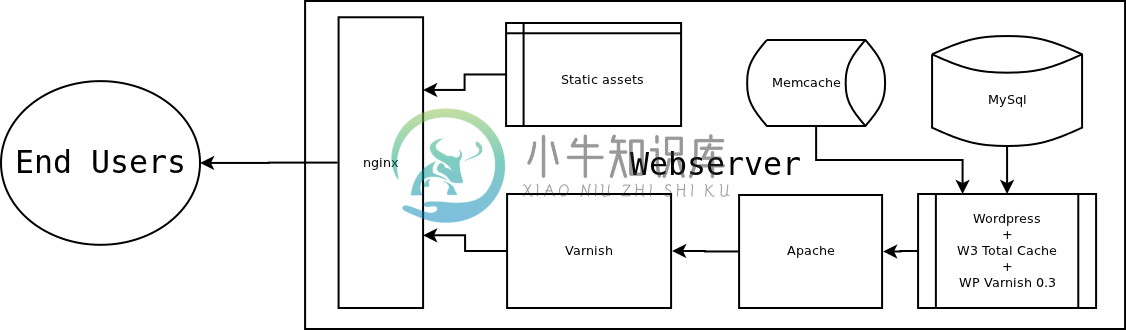
而实际上这样的服务器可能是多余的——我们为什么不直接生成HTML就好了?
编辑-发布分离
或许你听过 Martin Folwer 提出的编辑-发布分享式架构:即文章在编辑时是一个形式,而发表时是另一个形式,比如用 Markdown 编辑,而用 HTML 发表。
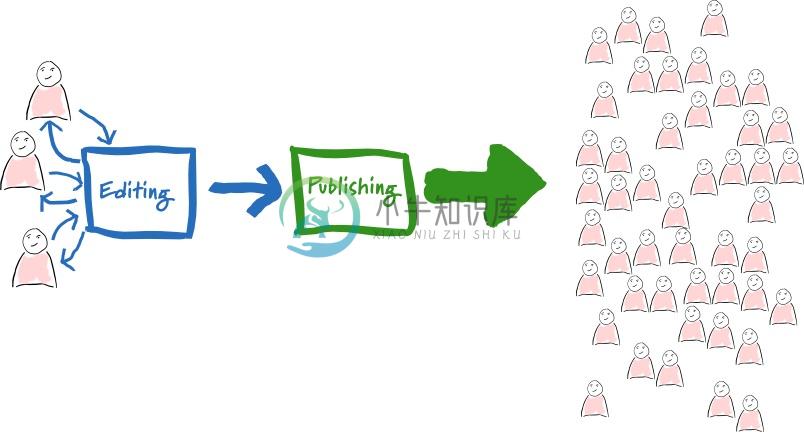
而最典型的应用就是流行于 GitHub 的 Hexo、Jekyll 框架之类的静态网站。如下图所示的是 Hexo 的工作流:
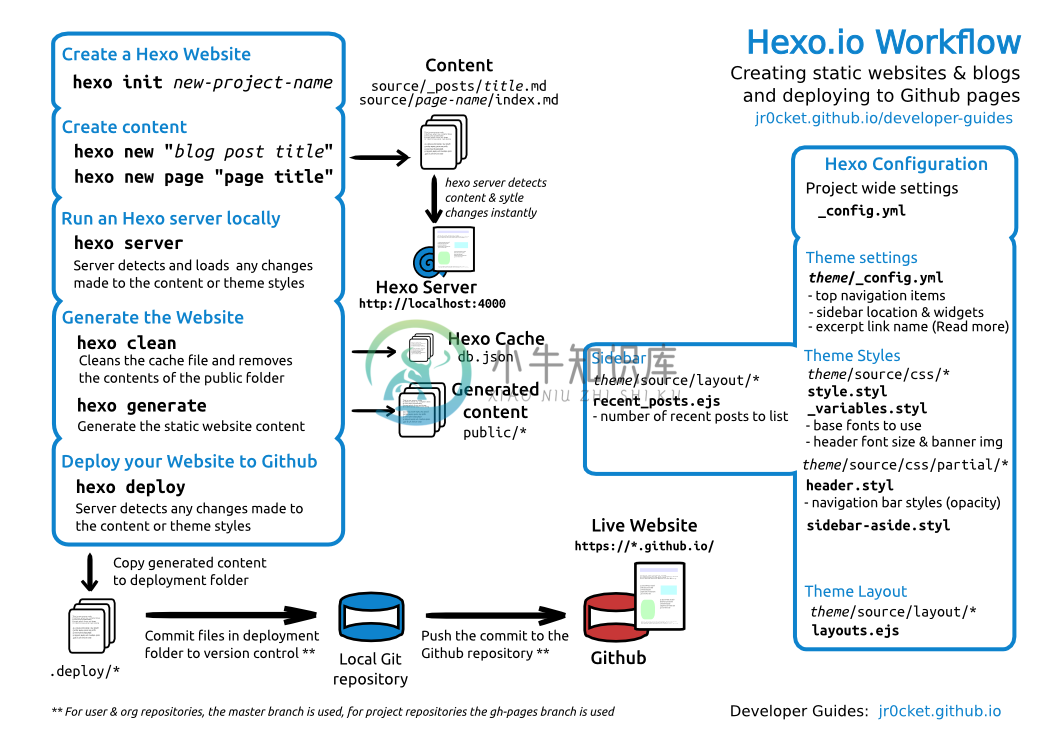
我们在本地生成我们的项目,然后可以创建一个新的博客、开始编写内容等等。接着,我们可以在本地运行起这个服务,除了查看博客的内容,还可以修改样 式等等。完成上面的工作后,我们就可以生成静态内容,然后部署我们的应用到GitHub Page上。这一切看上去都完美,我们有两个不同的数据源——一个是 md 格式的文本,一个是最后生成的 HTML。它们已经实现了读写/分离:
但是作为一个前端开发人员,没有 JSON,用不了 Ajax 请求,我怎么把博客做成一个单页面应用?
编辑-发布-开发分离
我们需要将博客转为 JSON,而不是一个 hexo 之类的格式。有了这些 JSON 文件的存在,我们就可以把 Git 当成一个 NoSQL 数据库。同时这些 JSON 文件也可以直接被当成 API 响应来使用。
其次,这些博客还需要像 hexo 一样生成 HTML。
并且,开发人员在开发的时候不会影响到编辑的使用,于是就有了下面的架构:
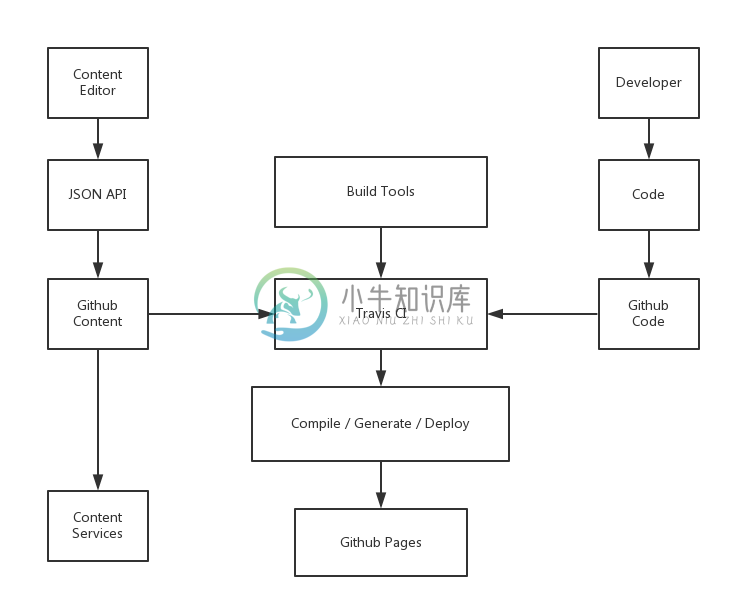
在这其中我们有两种不同的数据形式,即存储着 Markdown 数据的 JSON 文件和最后生成的 HTML。
对博客数量不是很大的网站,或者说一般的网站来说,用上面的技术都不是问题。然而有大量数据的网站怎么办?使用 EventBus:
在我之前玩的一个 Demo 中,使用 Python 中的 Scrapy 爬虫来抓取现有的动态网站,并将其变成静态网站部署到 AWS S3上。
但是上面仅仅只是实现了文章的显示,我们还存在一些问题:
- 搜索功能
- AutoComplete
等等的这些服务是没有用静态 API 来实现的。
CQRS 结合微服务
既然可以有这么多分法,并且我们都已经准备好分它们了。那么分了之后,我们就可以把他们都合到一起了。
Nginx as Dispatcher
最常见的解耦应用的方式中,就有一种是基于 Nginx 来分发 URL 请求。在这种情况下,对于 API 的使用者,或者最终用户来说,他们都是同一个 API。只是在后台里,这个 API 已经是不同的几个 API 组成,如下图所示:
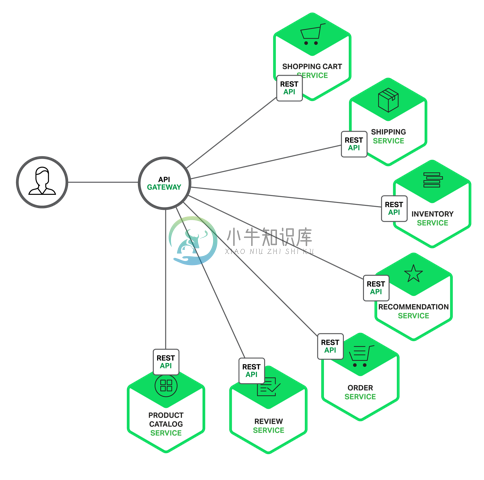
客户端的请求来到 API Gateway,根据不同的请求类型,这些 URL 被分发到不同的 Service,如 Review Service、Order Service 等等。
对于我们想要设计的系统来说也是如此,我们可以通过这个 Dispatcher 来解耦我们的服务。
CQRS 结合微服务
现在,我们想要的系统的雏形已经出现了。
从源头上来说,我们把能缓存的内容变成了静态的 HTML,通过 CDN 来分发。并且,我们还可以将不同的服务独立出来。
从实现上来说,我们将博客的数据变成了两部分: 一个以 Git + JSON 格式存在的 API,它除了可以用于生成 HTML,另外一部分作为 API 来使用。
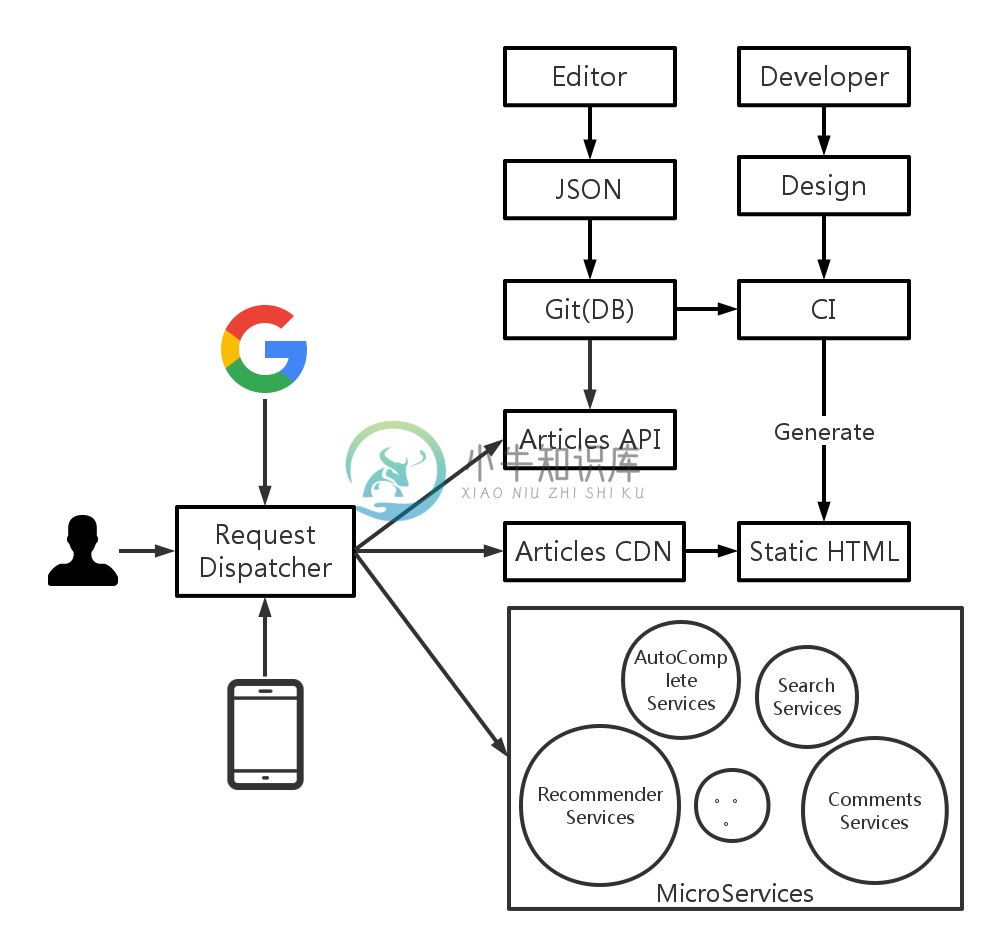
最后,我们可以通过上面说到的 Nginx 或者 Apache 来当这里的 Request Dispatcher。
以一幢有少许破窗的建筑为例,如果那些窗不被修理好,可能将会有破坏者破坏更多的窗户。最终他们甚至会闯入建筑内,如果 发现无人居住,也许就在那里定居或者纵火。又或想像一条人行道有些许纸屑,如果无人清理,不久后就会有更多垃圾,最终人们会视为理所当然地将垃圾顺手丢弃 在地上。因此破窗理论强调着力打击轻微罪行有助减少更严重罪案,应该以零容忍的态度面对罪案。