
python实现
ID3算法python实现
数据集来源《机器学习实战》:https://github.com/apachecn/MachineLearning/blob/master/input/3.DecisionTree/lenses.txt
young myope no reduced no lenses
young myope no normal soft
young myope yes reduced no lenses
young myope yes normal hard
young hyper no reduced no lenses
young hyper no normal soft
young hyper yes reduced no lenses
young hyper yes normal hard
pre myope no reduced no lenses
pre myope no normal soft
pre myope yes reduced no lenses
pre myope yes normal hard
pre hyper no reduced no lenses
pre hyper no normal soft
pre hyper yes reduced no lenses
pre hyper yes normal no lenses
presbyopic myope no reduced no lenses
presbyopic myope no normal no lenses
presbyopic myope yes reduced no lenses
presbyopic myope yes normal hard
presbyopic hyper no reduced no lenses
presbyopic hyper no normal soft
presbyopic hyper yes reduced no lenses
presbyopic hyper yes normal no lenses
数据集的特征从左到右为 ['age', 'prescript', 'astigmatic', 'tearRate'],最后一个为类别,类别包含三种类型['no lenses', 'hard', 'soft' ]。
基本思路:构建一个树形结构的输出,选择信息增益最大的特征作为节点,非叶子节点都是特征,节点上的特征将数据集分成各个子集,然后再递归。
# -*- coding: utf-8 -*-
from math import log
from collections import Counter
class DecisionTree(object):
def __init__(self, input_data, labels):
pass
def create_decision_tree(self, data_set, labels): # 输出树形结构
class_list = [data[-1] for data in data_set]
if class_list.count(class_list[0]) == len(class_list): # 如果剩下的数据集的类别都一样
return class_list[0]
if len(data_set[0]) == 1: # 如果数据集没有特征,只剩下类别,选择类别最多的输出
major_label = Counter(data_set).most_common(1)[0]
return major_label
feature_index = self.get_feature_with_biggest_gain(data_set, labels) # 获取最大信息增益的特征
feature_name = labels[feature_index]
del labels[feature_index]
feature_set = set([ data[feature_index] for data in data_set ]) # 找到该特征的所有可能取值
decision_tree = {feature_name: {}}
for i in feature_set:
# 遍历该特征的所有取值,将数据集分割成各个子集,然后递归对各个子集进行同样的特征选择
feature_data_list = [ data for data in data_set if data[feature_index] == i ] # 满足
new_data_list = []
for j in feature_data_list: # 移除已经选择的特征,获取子集
new_data = j[:]
del new_data[feature_index]
new_data_list.append(new_data)
#print(i, new_data_list)
new_lables = labels[:]
decision_tree[feature_name][i] = self.create_decision_tree(new_data_list, new_lables)
return decision_tree
def cal_data_set_entropy(self, data_set): # 计算数据集的经验熵
total_num = len(data_set)
class_list = [data[-1] for data in data_set]
class_dict = dict()
for i in class_list:
ck_num = class_dict.get(i, 0)
class_dict[i] = ck_num + 1
entropy = 0
for k in class_dict:
ck_rate = float(class_dict[k])/total_num
entropy -= ck_rate * log(ck_rate, 2)
return entropy
def get_feature_with_biggest_gain(self, data_set, labels): #获取最大信息增益的特征
feature_num = len(labels)
data_entropy = self.cal_data_set_entropy(data_set)
biggest_gain_index = None
biggest_gain = 0
for i in range(feature_num):
# 遍历所有特征,找出最大的信息增益特征
condition_entroy = self.cal_feature_condition_entropy(data_set, i)
gain = data_entropy - condition_entroy
if gain > biggest_gain:
biggest_gain_index = i
biggest_gain = gain
#print(labels[biggest_gain_index], biggest_gain)
return biggest_gain_index
def cal_feature_condition_entropy(self, data_set, index): # 计算某个特征的条件熵
total_num = len(data_set)
feature_list = [data[index] for data in data_set]
feature_dict = dict()
for i in feature_list:
feature_num = feature_dict.get(i, 0)
feature_dict[i] = feature_num + 1
condition_entropy = 0
for k in feature_dict:
feature_rate = float(feature_dict[k])/total_num
feature_data_set = [data for data in data_set if data[index] == k]
entropy = self.cal_data_set_entropy(feature_data_set)
condition_entropy += feature_rate * entropy
return condition_entropy
train_data = "*/input/3.DecisionTree/lenses.txt"
with open(train_data) as f:
lenses = [line.strip().split('\t') for line in f.readlines()] # 特征之间用tab键隔离开
labels = ['age', 'prescript', 'astigmatic', 'tearRate']
#[['young', 'myope', 'no', 'reduced', 'no lenses'],
# ['young', 'myope', 'no', 'normal', 'soft']
dTree = DecisionTree(lenses, labels)
print(dTree.create_decision_tree(lenses, labels))
{'tearRate': {'reduced': 'no lenses',
'normal': {'astigmatic': {'yes': {'prescript': {'hyper': {'age': {'pre': 'no lenses',
'presbyopic': 'no lenses',
'young': 'hard'}},
'myope': 'hard'}},
'no': {'age': {'pre': 'soft',
'presbyopic': {'prescript': {'hyper': 'soft',
'myope': 'no lenses'}},
'young': 'soft'}}
}
}
}
}
如果画成树形结构:
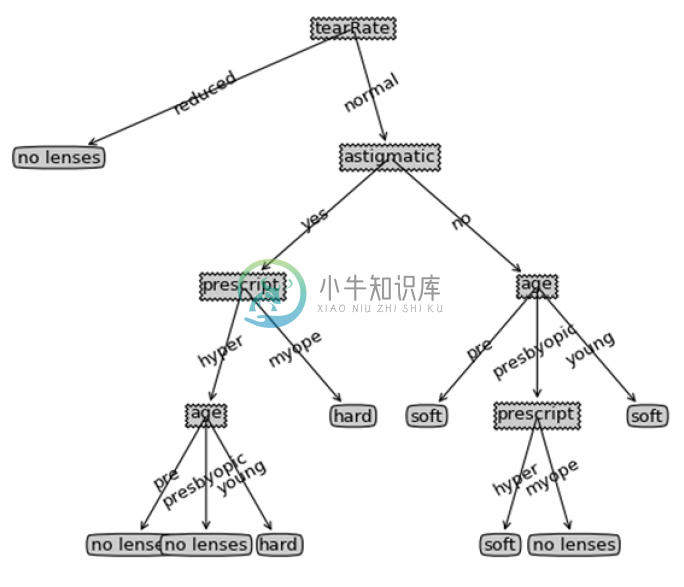
树形结构代码参考:https://github.com/apachecn/MachineLearning/blob/master/src/py3.x/3.DecisionTree/decisionTreePlot.py