
4.5 附加组件 - Cluster AutoScaler
Cluster AutoScaler 是一个自动扩展和收缩 Kubernetes 集群 Node 的扩展。当集群容量不足时,它会自动去 Cloud Provider (支持 GCE、GKE 和 AWS)创建新的 Node,而在 Node 长时间资源利用率很低时自动将其删除以节省开支。
Cluster AutoScaler 独立于 Kubernetes 主代码库,维护在 https://github.com/kubernetes/autoscaler。
部署
Cluster AutoScaler v1.0+ 可以基于 Docker 镜像 gcr.io/google_containers/cluster-autoscaler:v1.0.0 来部署,详细的部署步骤可以参考
- GCE: https://kubernetes.io/docs/concepts/cluster-administration/cluster-management/
- GKE: https://cloud.google.com/container-engine/docs/cluster-autoscaler
- AWS: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
- Azure: https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler/cloudprovider/azure
比如 Azure 中的部署方式为
apiVersion: v1data:ClientID: <client-id>ClientSecret: <client-secret>ResourceGroup: <resource-group>SubscriptionID: <subscription-id>TenantID: <tenand-id>ScaleSetName: <scale-set-name>kind: ConfigMapmetadata:name: cluster-autoscaler-azurenamespace: kube-system---apiVersion: extensions/v1beta1kind: Deploymentmetadata:name: cluster-autoscalernamespace: kube-systemlabels:app: cluster-autoscalerspec:replicas: 1selector:matchLabels:app: cluster-autoscalertemplate:metadata:labels:app: cluster-autoscalerspec:tolerations:- effect: NoSchedulekey: node-role.kubernetes.io/masternodeSelector:kubernetes.io/role: mastercontainers:- image: gcr.io/google_containers/cluster-autoscaler:{{ca_version}}name: cluster-autoscalerresources:limits:cpu: 100mmemory: 300Mirequests:cpu: 100mmemory: 300Mienv:- name: ARM_SUBSCRIPTION_IDvalueFrom:configMapKeyRef:name: cluster-autoscaler-azurekey: SubscriptionID- name: ARM_RESOURCE_GROUPvalueFrom:configMapKeyRef:name: cluster-autoscaler-azurekey: ResourceGroup- name: ARM_TENANT_IDvalueFrom:configMapKeyRef:name: cluster-autoscaler-azurekey: TenantID- name: ARM_CLIENT_IDvalueFrom:configMapKeyRef:name: cluster-autoscaler-azurekey: ClientID- name: ARM_CLIENT_SECRETvalueFrom:configMapKeyRef:name: cluster-autoscaler-azurekey: ClientSecret- name: ARM_SCALE_SET_NAMEvalueFrom:configMapKeyRef:name: cluster-autoscaler-azurekey: ScaleSetNamecommand:- ./cluster-autoscaler- --v=4- --cloud-provider=azure- --skip-nodes-with-local-storage=false- --nodes="1:10:$(ARM_SCALE_SET_NAME)"volumeMounts:- name: ssl-certsmountPath: /etc/ssl/certs/ca-certificates.crtreadOnly: trueimagePullPolicy: "Always"volumes:- name: ssl-certshostPath:path: "/etc/ssl/certs/ca-certificates.crt"
工作原理
Cluster AutoScaler 定期(默认间隔 10s)检测是否有充足的资源来调度新创建的 Pod,当资源不足时会调用 Cloud Provider 创建新的 Node。
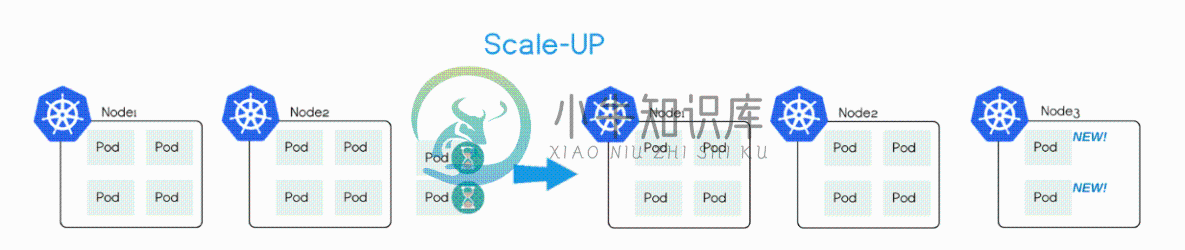
为了自动创建和初始化 Node,Cluster Autoscaler 要求 Node 必须属于某个 Node Group,比如
- GCE/GKE 中的 Managed instance groups(MIG)
- AWS 中的 Autoscaling Groups
- Azure 中的 Scale Sets 和 Availability Sets
当集群中有多个 Node Group 时,可以通过 --expander=<option> 选项配置选择 Node Group 的策咯,支持如下四种方式
- random:随机选择
- most-pods:选择容量最大(可以创建最多 Pod)的 Node Group
- least-waste:以最小浪费原则选择,即选择有最少可用资源的 Node Group
- price:选择最便宜的 Node Group(仅支持 GCE 和 GKE)
目前,Cluster Autoscaler 可以保证
- 小集群(小于 100 个 Node)可以在不超过 30 秒内完成扩展(平均 5 秒)
- 大集群(100-1000 个 Node)可以在不超过 60 秒内完成扩展(平均 15 秒)
Cluster AutoScaler 也会定期(默认间隔 10s)自动监测 Node 的资源使用情况,当一个 Node 长时间(超过 10 分钟其期间没有执行任何扩展操作)资源利用率都很低时(低于 50%)自动将其所在虚拟机从云服务商中删除(注意删除时会有 1 分钟的 graceful termination 时间)。此时,原来的 Pod 会自动调度到其他 Node 上面(通过 Deployment、StatefulSet 等控制器)。
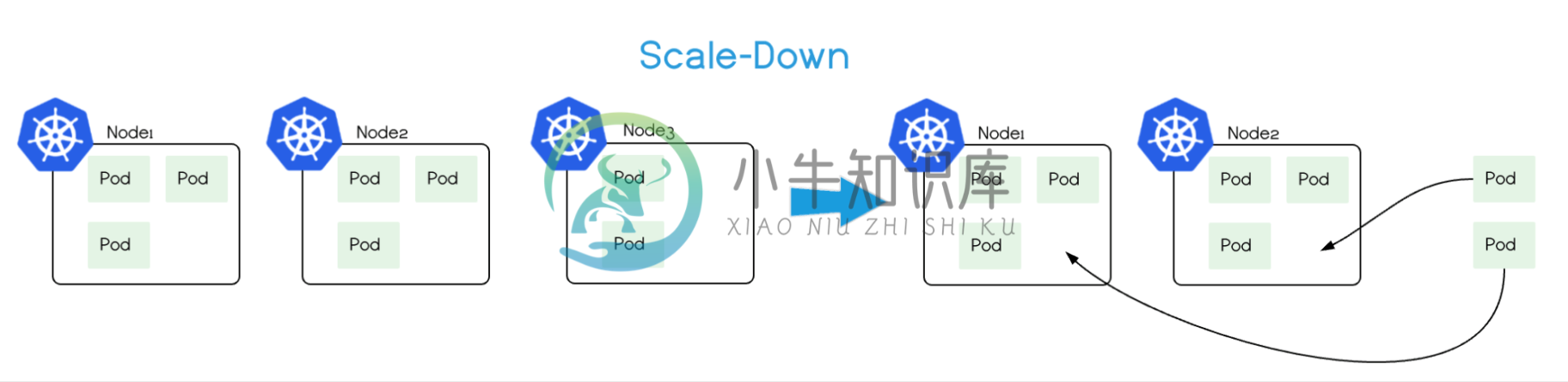
注意,Cluster Autoscaler 仅根据 Pod 的调度情况和 Node 的整体资源使用清空来增删 Node,跟 Pod 或 Node 的资源度量(metrics)没有直接关系。
用户在启动 Cluster AutoScaler 时可以配置 Node 数量的范围(包括最大 Node 数和最小 Node 数)。
在使用 Cluster AutoScaler 时需要注意:
- 由于在删除 Node 时会发生 Pod 重新调度的情况,所以应用必须可以容忍重新调度和短时的中断(比如使用多副本的 Deployment)
- 当 Node 上面的 Pods 满足下面的条件之一 时,Node 不会删除
- Pod 配置了 PodDisruptionBudget (PDB)
- kube-system Pod 默认不在 Node 上运行或者未配置 PDB
- Pod 不是通过 deployment, replica set, job, stateful set 等控制器创建的
- Pod 使用了本地存储
- 其他原因导致的 Pod 无法重新调度,如资源不足,其他 Node 无法满足 NodeSelector 或 Affinity 等
最佳实践
- Cluster AutoScaler 可以和 Horizontal Pod Autoscaler(HPA)配合使用
- 不要手动修改 Node 配置,保证集群内的所有 Node 有相同的配置并属于同一个 Node 组
- 运行 Pod 时指定资源请求
- 必要时使用 PodDisruptionBudgets 阻止 Pod 被误删除
- 确保云服务商的配额充足
- Cluster AutoScaler 与云服务商提供的 Node 自动扩展功能以及基于 CPU 利用率的 Node 自动扩展机制冲突,不要同时启用